
Introduction
This is the second part of a 3-part introductory series on using JHipster with Cassandra. You can read yesterday’s post here: Using Cassandra with JHipster.
CQL vs Hector
At Ippon Technologies we started using Cassandra many years before CQL existed. At that time, we were using Hector (or its Netflix version Astyanax), and we even know some people who directly used Cassandra’s Storage Proxy!
Without a doubt, CQL is one of the strongest reasons why Cassandra has become so widely used today, after taking several years to take off. But CQL also gives a false vision of your data: it makes things a lot easier, at the cost of masking how data is stored in Cassandra, and we have found this very confusing for several of our customers.
As a result, we use some diagrams to explain how Cassandra works internally, and how CQL fits its data into this internal storage. We have had several customers who told us we should share those diagrams, so here they are!
We are going to study two of the most common use cases in Cassandra: a one-to-many relationship, and a value-less “wide row”. Once you have studied both of them, it is easy to follow the same methodology for other use cases.
Modeling a one-to-many relationship
We want to model a classic one-to-many relationship: an author has written many books.
Here is the CQL code for this table:
CREATE TABLE book ( author_id text, birthday timestamp static, firstname text static, book_id bigint, book_date timestamp, book_title text, book_price int, PRIMARY KEY((author_id), book_id) );
We have two keys here:
- The author_id is the partition key: authors will be distributed all over the Cassandra ring, so we can insert a lot of authors. The downside is that finding all authors will be very slow, unless we have another table, to do the lookup.
- The book_id is the clustering key: all books will be on the same Cassandra node. They won’t scale well (as they are not distributed), but it will be fast and easy to select all the books from one author
Here is how CQL will show you this table:
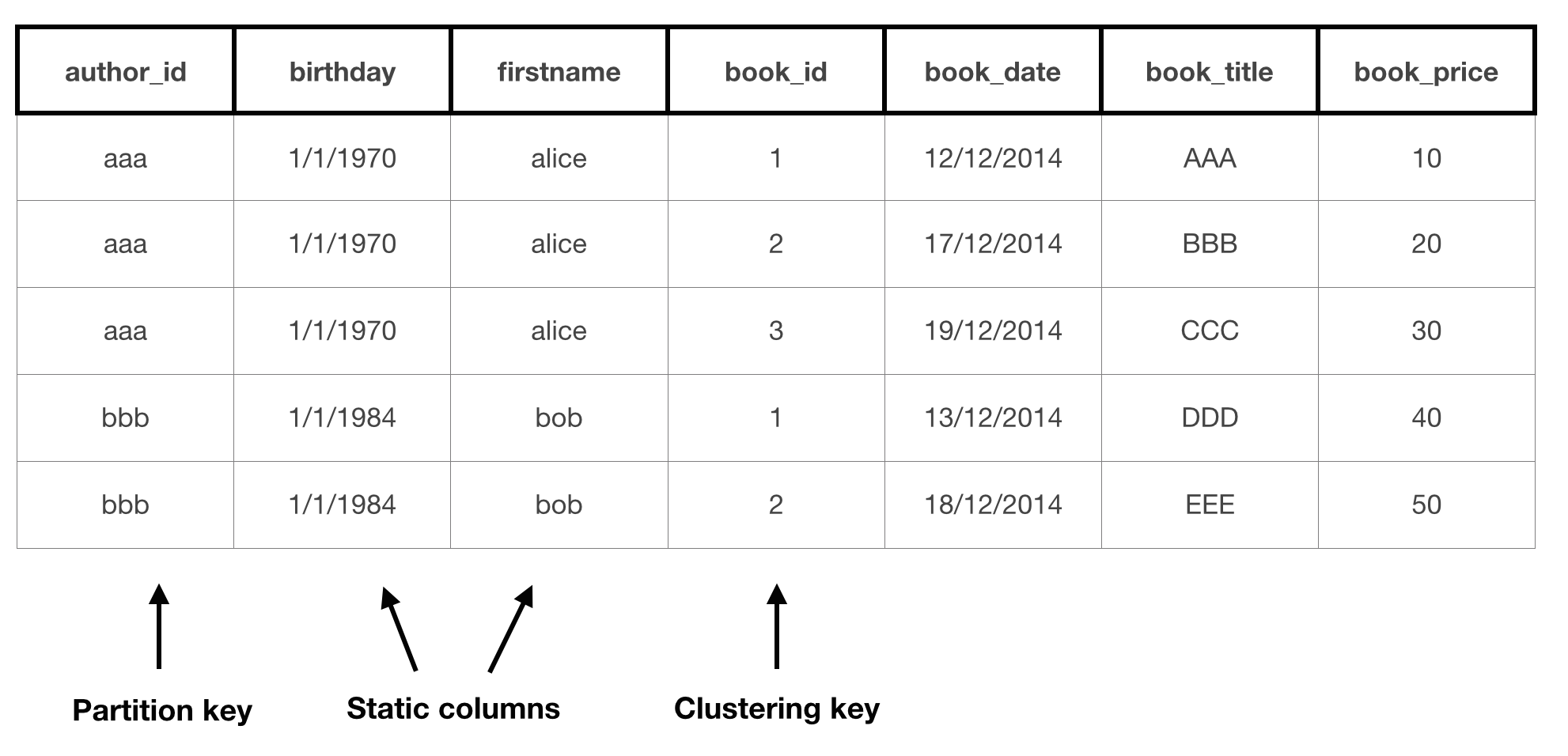
But underneath, Cassandra is only storing this data inside one row per author: the partition key will be the row key, and then all the rest of the data (author information and all books) will be stored on the same row.
Here is how the same data is stored inside Cassandra:

This second view is harder to read at first, but it makes it a lot easier to understand how data is distributed across the cluster, as only rows are distributed.
- The partition key is in fact the Cassandra row key.
- Static columns are only stored once (when the CQL table shows them duplicated).
- The clustering key is used in the column names, so all the clustered data is in fact on the same Cassandra row. It is perfectly normal, with Cassandra, to store data in the column name.
- By default, Cassandra rows are ordered: in our example, this means that books are sorted by their book_id. This is an important feature, for example when you store time series.
Modeling an index table
In the 1st part of this series, we used “index tables” to look up a user according to his login, email, or activation key. We are going to model one of those “index tables”.
We would like to find all authors according to their first name, but this column is not a partition key. Even worst, as this is a static column, it is distributed all over our cluster: looking for it is the NoSQL equivalent of doing a “full scan”, but this would be a “distributed full scan” on the whole Cassandra ring. That would be very inefficient!
The solution is to create a second table, that is specialized for doing that query: as always with Cassandra, writes are cheap, and we model our database for the queries we will need to use.
Here is the CQL script for that table:
CREATE TABLE author_by_firstname ( firstname text, author_id text, PRIMARY KEY((firstname), author_id) );
When querying this data, here is how the CQL table will look like:
But as we have seen in the first part of this article, data is stored differently in Cassandra. Here is how it is stored:
This table has some interesting properties:
- As the firstname is used as a partition key, we can have an unbalanced cluster if we have one very common first name (for example, if a lot of people are named “john”). In a normal use case, this will of course works very well.
- By default, columns are ordered by name: our authors will be returned sorted by their id, and that list will be easy to paginate.
- It is a valueless table: its columns do not have any values! This is perfectly normal with Cassandra, as we can use the column names to store data, and that information is enough in this use case.
Going further with Cassandra
Following this 2nd post on this series, we will post tomorrow another article giving 10 tips and tricks on using Cassandra.


Comments