

Main Takeaways
- S3 is the recommended option over HDFS much of the time
- Use Transient Clusters for your workloads to save on cost
- Amazon EMR team has spent a lot of time tuning default settings, so don't tweak default settings unless you really know what you're doing and why you need to do it.
Moving Data Into EMRS
EMRS is best populated from S3
When populated EMRS from an existing cluster for the first time, it is best to use S3 as an escrow data storage location for your on-prem HDFS/non-HDFS data.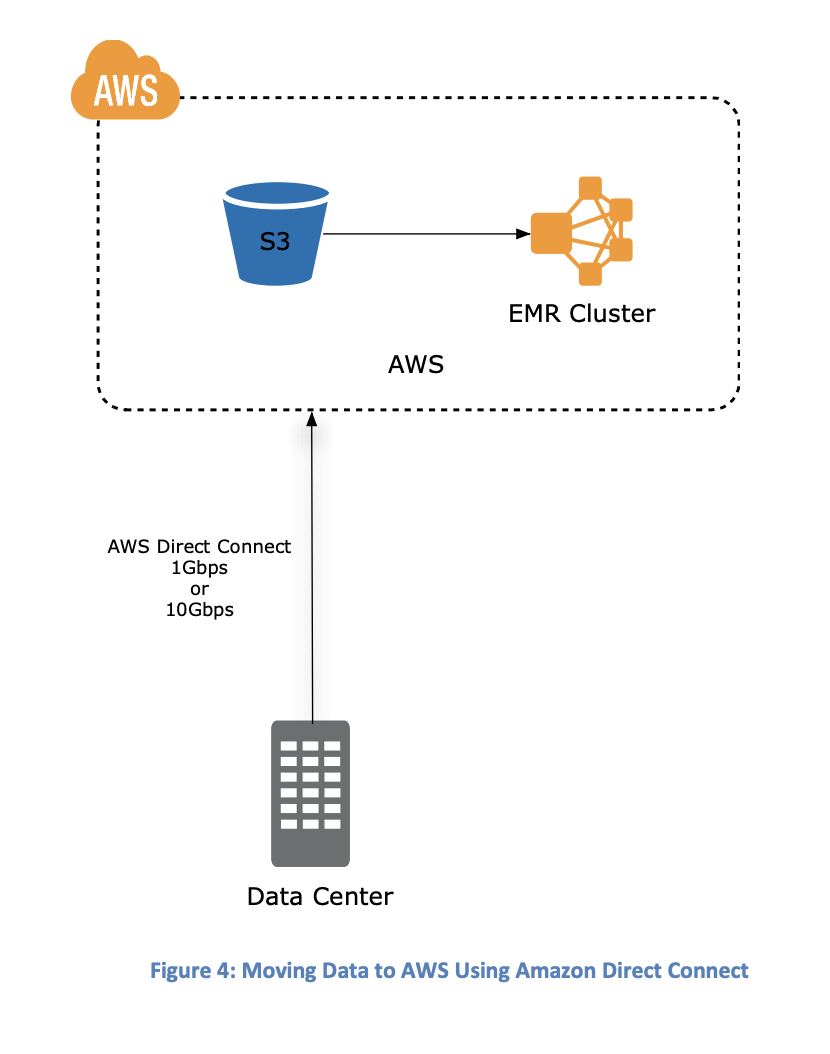
Use S3DistCp to copy data to S3
S3DistCp is the same as the Hadoop binary DistCp, except it takes advantage of multi-part upload to S3 for larger files. Hadoop is optimized for large file blocks, so it is usually best to use S3DistCp for copying HDFS files from an external data center or local disk to S3 to take advantage of this optimization.
S3DistCp is faster than DistCp
The exception to this may come in very specific instances, where you need to specify the number of mappers needed for your copy job. DistCp allows you to specify the number of mappers using CLI flags, whereas S3DistCp does not. It is possible DistCp could perform faster in some cases when the proper number of mappers need to be specified manually. However, the default formula used by DistCp is usually the best option for most workloads, which means S3DistCp is your best bet for copying data.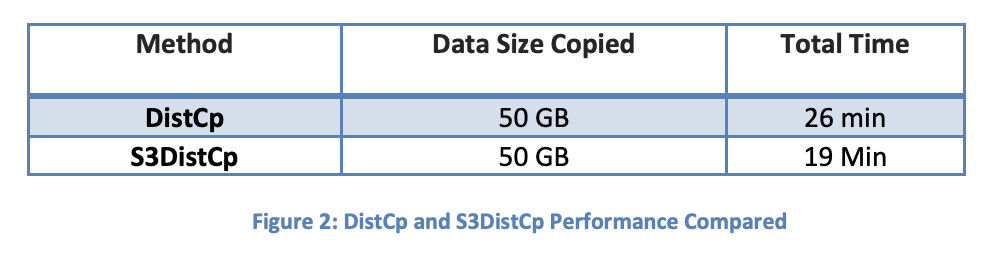
AWS Import/Export or Storage Volume Gateway to copy non-HDFS data into S3
Recommended AWS supported option for transferring data from a non-HDFS source to S3 at the time of publication. At the time of this post's writing, you could likely replace Import/Export with a Storage Gateway Volume which writes directly to S3.
Copy from S3 to EMR
Use the S3DistCp command to copy the data from your S3 bucket onto a Core Node. Run the command on a core node, specifying the HDFS directory as the destination. Let EMR handle the redundant copies to the other core nodes in the cluster. You cannot run this on a Task or Master node as those nodes do not have HDFS on them.
EMRFS > HDFS
Use EMRFS over HDFS to take advantage of S3 as a storage layer. This works well when continuously adding data to your EMR cluster. It is better to forward logs to S3 than directly to HDFS. But when your cluster uses EMRFS, it gets the updates to the file system from S3. This allows you to take advantage of bucket policies, bucket encryption, and object versioning for your EMR files.
Consistent View
For more information on how S3 bypasses eventual consistency for new PUT requests, check out Consistent View, a special feature of EMR which utilizes DynamoDB to bypass the eveentual consistency model employed by S3.
Iterative Jobs Should Use HDFS Only
Do not use S3 and EMRFS for iterative jobs, as you will introduce additional costs and latency for all of the repeated S3 GETs.
Aggregating Data for MapReduce
Fewer Large Files > Many Small Files
This scheme takes advantage of multi-part uploads to S3, and reduces the number of connections required to upload data. Additionally, fewer files stored in S3 improves performance for EMR reads on S3.
Log Forwarding
Where possible use a log forwarding framework like Apache Flume or Fluentd and write directly to the S3 bucket.
Aggregate Logs Based on Size
If your log aggregator can aggregate logs based on size, try to split your log files into large 1GB or 2GB chuncks. This will be most performant for EMR. If you cannot aggregate on size, aggregate on time taking into consideration log volume over time.
Recall the "Map" in MapReduce
This stage breaks large files into chunks for parallel processing. That is why it is best to upload large files to HDFS or S3 for EMRFS.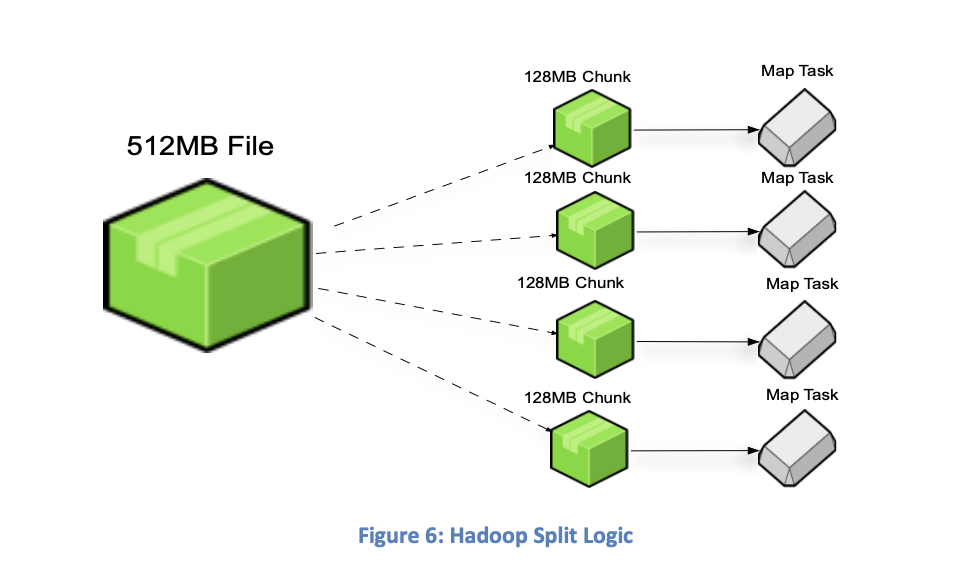
Compress Your Files Before Processing
This will save on data transfer costs. Recall though, EMR splits up files phase. Make sure you consider your compression algorithm with your log aggregator. Some compression schemes like GZip and Snappy will not allow the resulting compressed file to be split. In that case, try not to surpass 1GB per compressed file. If you do choose a "splitable" compression algorithm like LZO or BZip2, you can drastically increase the size of your compressed files up to 4GB. Choose intelligently based on required compression speeds and ratios. These factors are more important than choosing an aggregated file size. You will hit a bottleneck in compression speed and ratios before you take a performance hit on S3 for logging more files.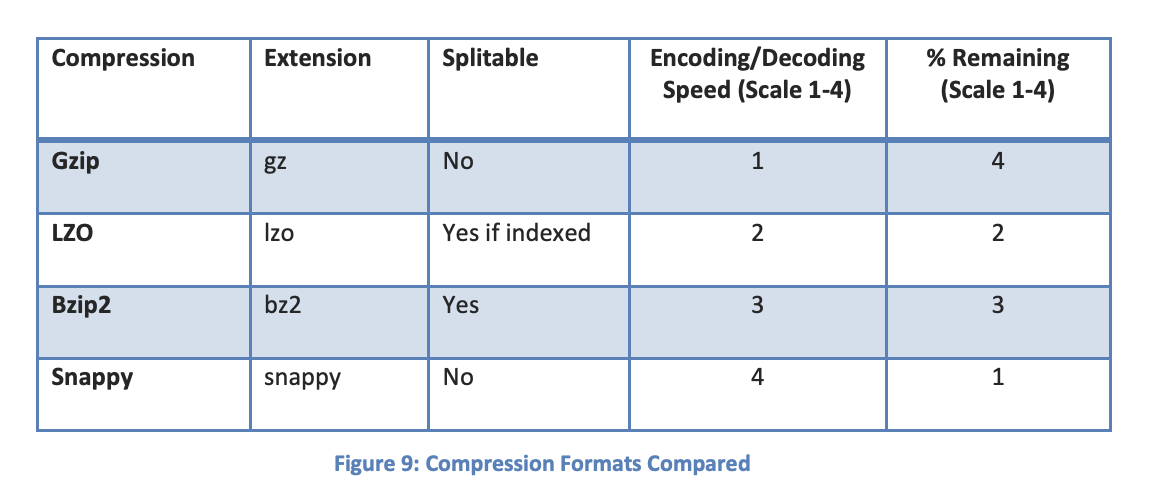
Consider compressing Mapper Outputs
EMR allows you to compress the output of the "Map" function, during the "Reduce" function. This is something to consider to save on data transfer costs. You can enable this in the core node properties.
Consider compressing Mapper Outputs in Memory
EMR allows you to compress the memory footprint of the "Map" function as well. This is an important consideration for large jobs that need to be completed quickly. If there is a large amount of data to map, compressing the output of the mappers in memory will prevent the output from being written to disk. You can enable this in the core node properties.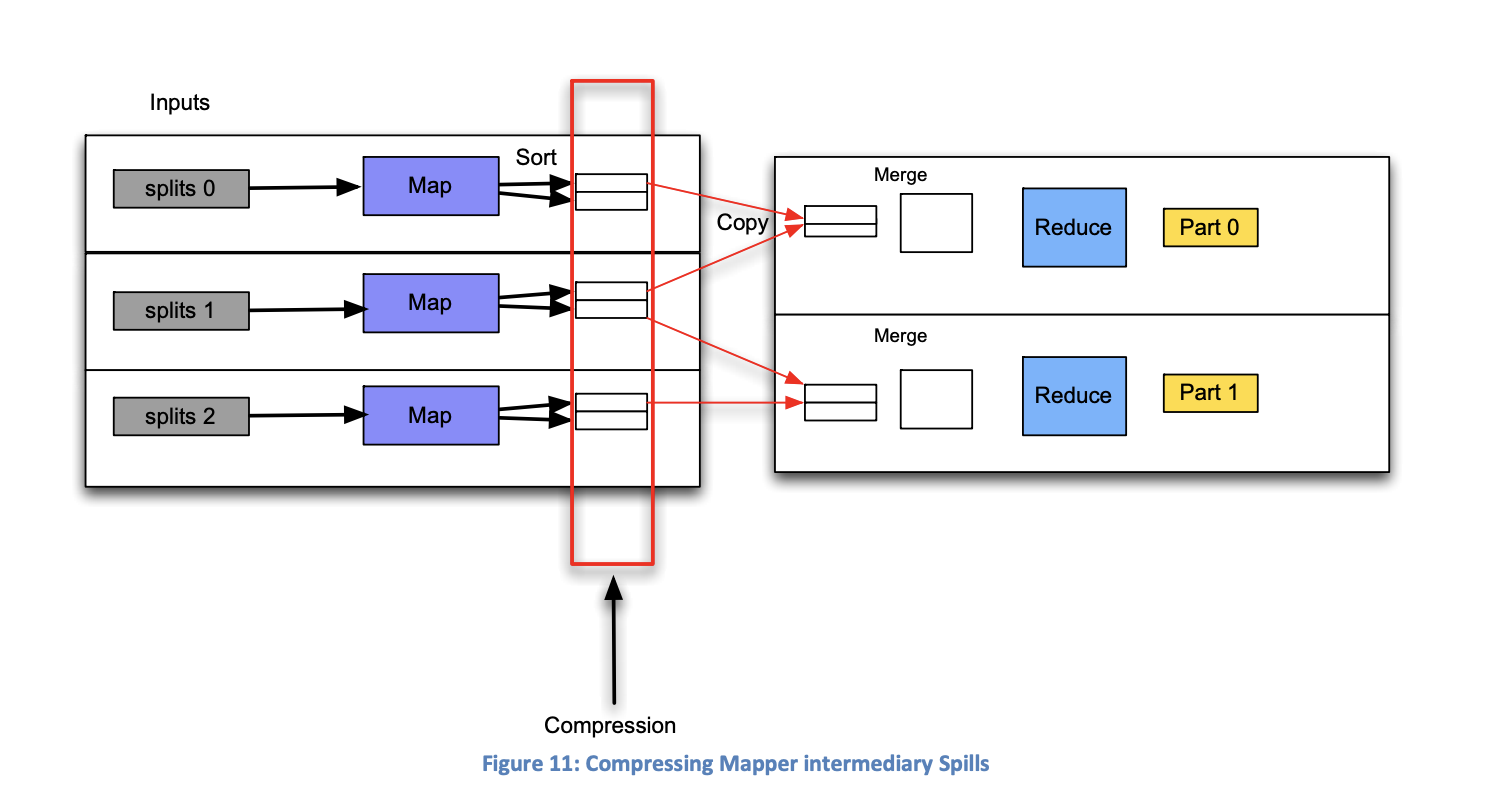
Tuning EMR
Instance Size
Use M2 instances for jobs requiring lots of memory. C1 or C2 instances provide larger compute resources. Consider spinning up clusters repeatedly until you discover the most performant instances for your workload. Keep in mind, larger memory pools prevent disk writes while larger CPU pools process jobs faster.
Mapper Process Count
The best way to calculate this is to rely on the EMR defaults. If you run a job on a default EMR cluster, you can see in the logs the number of mappers launched to process the job. Divide this value with the number of Core and Task nodes you have. The result is the number of mappers per EC2 instance. From there, you can determine how many mappers per EC2 you will need, and can then make a decision on the instance sizes you will create in your cluster.
Transient Clusters
If the number of processesing hours on your cluster is less than a day, spin up a transient cluster. The cluster will be terminated after the job is done, and you will save on costs. Additionally, consider transient clusters when using EMRFS, as the data will be backed up in S3. When the cluster dies, all cluster data will be backed up to S3, allowing you to resume processing at a later date from where you left off. Generally, if you're using S3 for storage, you will benefit from a transient cluster.
Cost Optimization
Use Spot Instances for Task Nodes
Task nodes offer additional compute, nothing else. Consider Spot instances for Task nodes to take advantage of EC2 market pricing without introducing potential data loss on your cluster should the Spot instance price rise above what you are willing to pay.
Purchase a Reserved Instance for Heavy Utilized Nodes
The master node and the minimum number of Core nodes should be reserved instances. This guarantees you will always have a node available to orchestrate your cluster as the master node. Additionally, reserved instances for the Core nodes ensures your cluster can always perform at a minimum high efficiency.
Using Reserved Instances requires deep workload knowledge
Only purchase Reserved Instances after you know what your cluster's workload will look like. Only purchase reserved instances to cover the predictable, steady-state workload of the cluster. Spot or on-demand instances should act as a buffer for workloads exceeding expectations.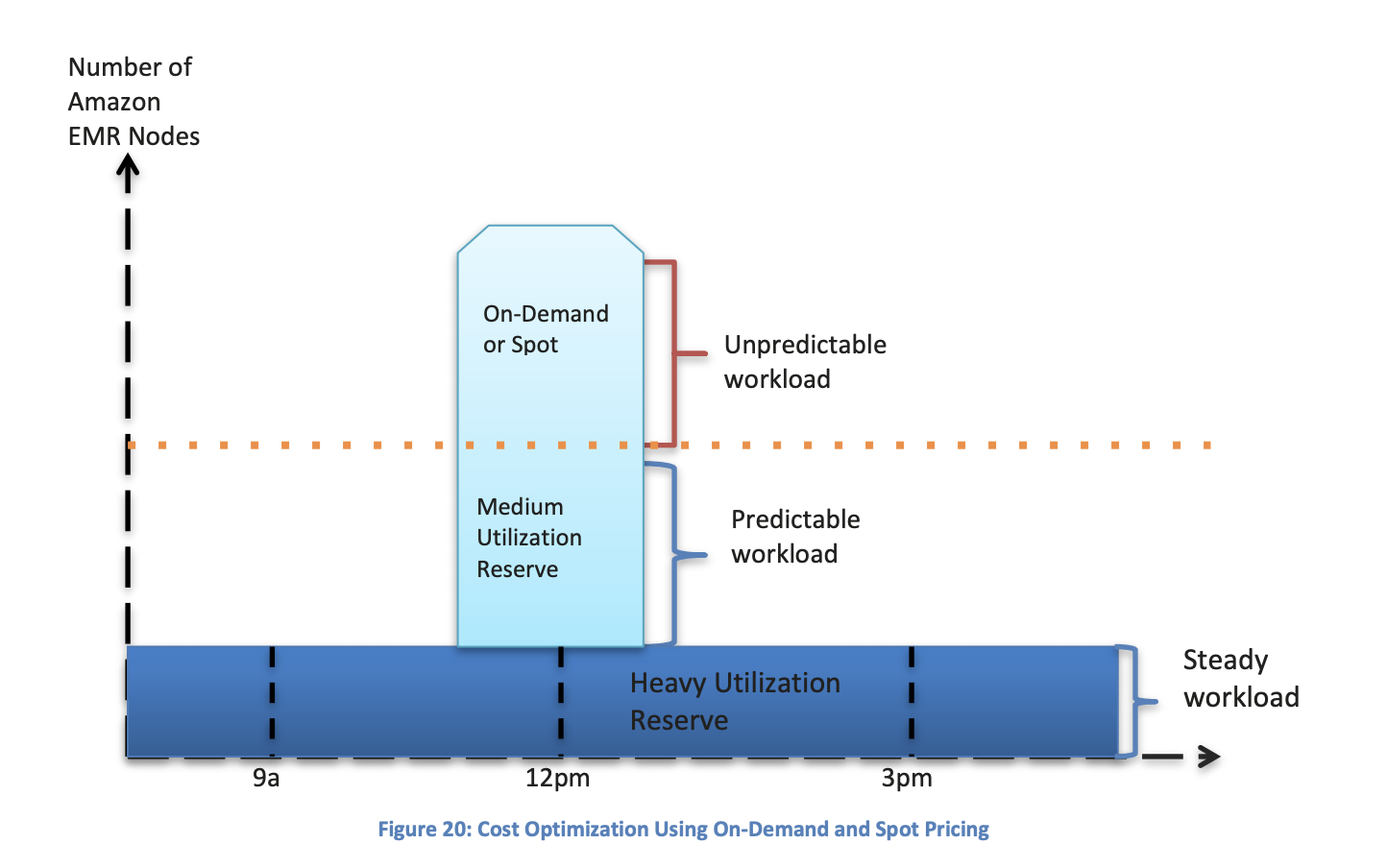
Design Patterns
S3 & EMRFS > HDFS
This is pushed by AWS as the best option for most workloads.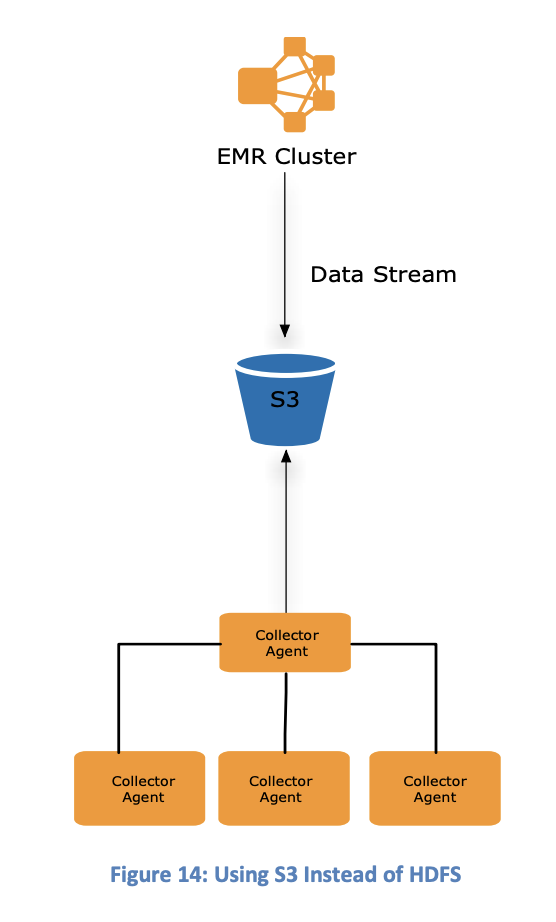
S3 & HDFS
Store data on S3 and copy to HDFS. Introduces start up latency, but is preferred for iterative workloads to save on S3 GET requests.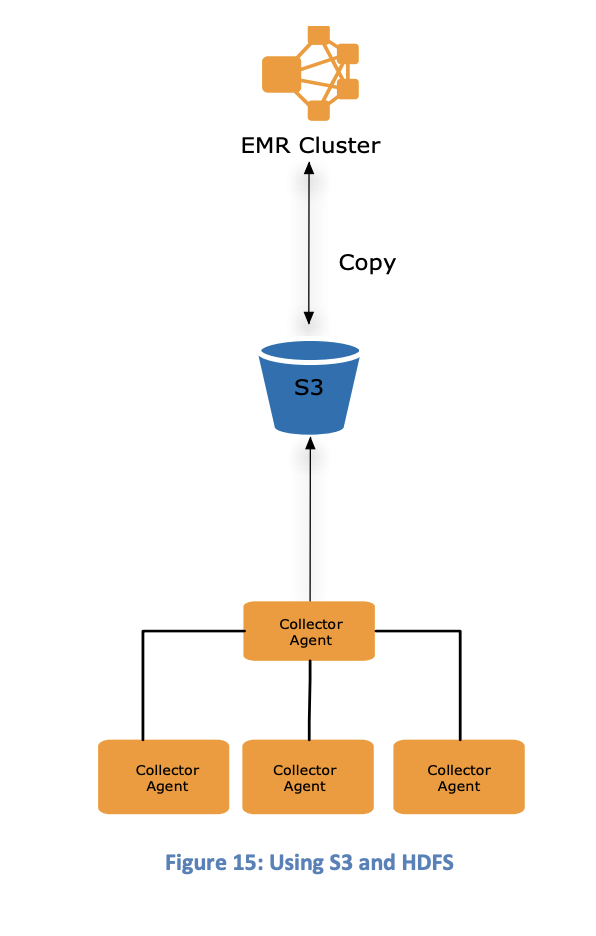
HDFS with S3 Backup
Use the HDFS on the core nodes, and backup to S3 whenever needed.
Manual Tuning
Use EMR console and CloudWatch to tune and configure EMR Cluster to fit your use case.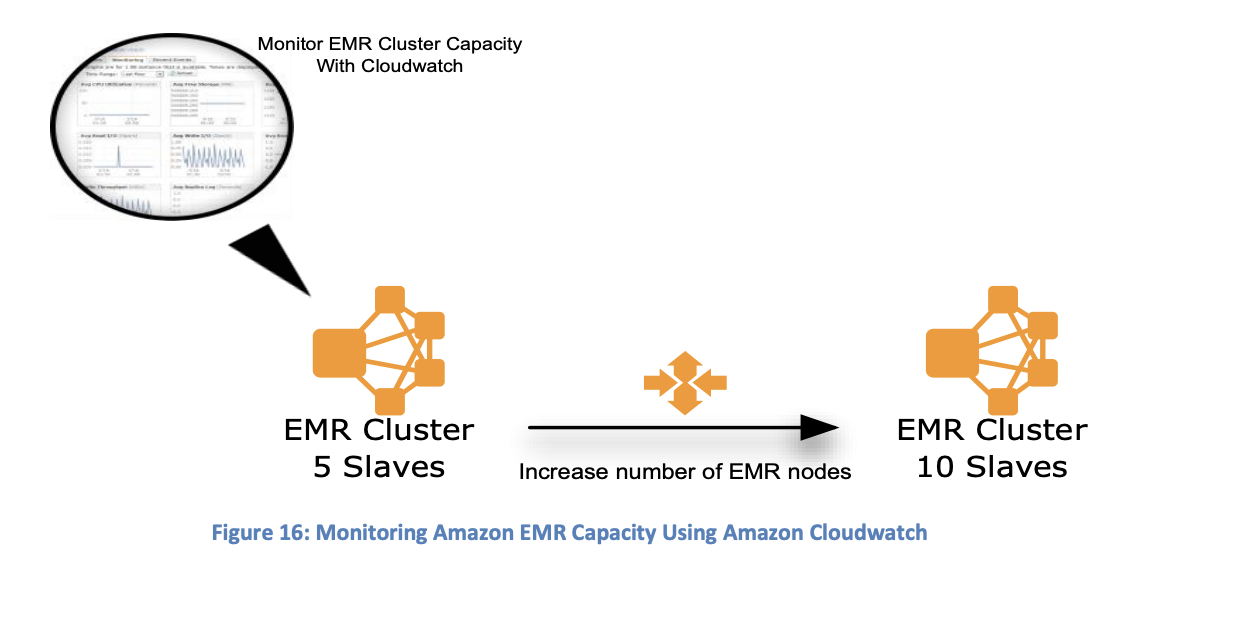
Automatic Tuning
Use CloudWatch alarms to tune EMR in response to your cluster's performance monitoring.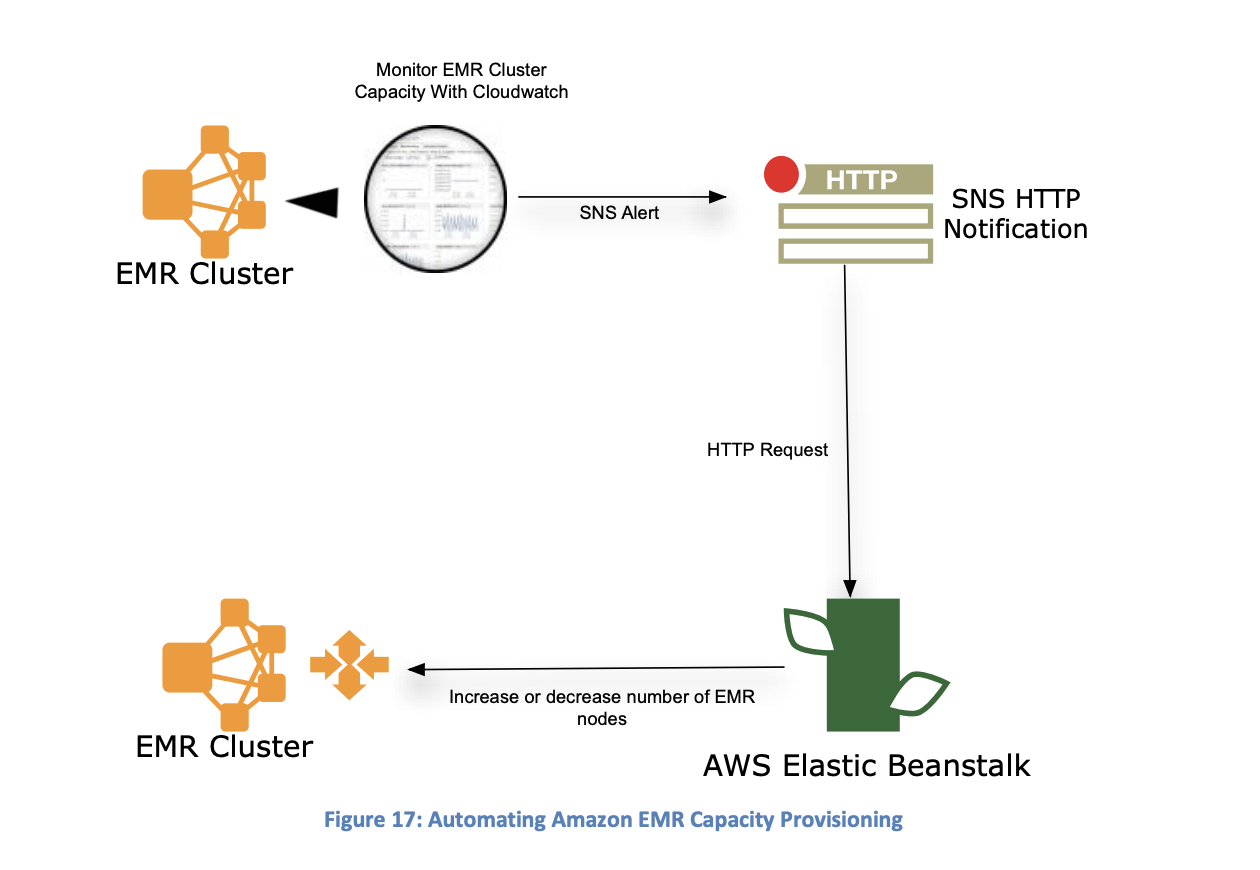
This image comes from the white paper. The image suggests using Elastic Beanstalk as an intermediary between SNS and the EMR API. The Beanstalk instance must be configured to interpret SNS messages generated by EMR CloudWatch alarms into EMR API commands. Given the date of publication of this white paper, Beanstalk may not be the best service to use in this case any more. I would suggest using API Gateway with Lambda functions to convert the SNS messages into EMR API calls; but the specific use case is relevant to the individual workload.
Summary of Themes
- S3 with EMRFS and Consistent Views works great on Transient Clusters.
- Compress your files intelligently based on required compression speeds and ratios. Adjust your aggregated file size to reflect the splittability of the compression algorithm chosen. If you cannot split the compressed files, ensure your files are no larger than 1GB.
- Do not use S3 for workloads which consistently read against the log data
- Purchase Reserved Instances to cover baseline, predictable workloads. Purchase Spot instances for Task nodes, but not Core and Master nodes as the immediate removal of a Core or Master node could compromise the cluster's health.
- Partition your data intelligently, based on how you will use it. If your log data is time sensitive, partition the logs based on time. Make sure your files are on the larger side to take advantage of EMRFS/HDFS file processing.

Comments