

How Databricks Delta Live Tables (DLT) simplify your life
Delta Live Tables (DLT) is a framework for building reliable, maintainable, and testable data processing pipelines. You define the transformations to perform on your data, and Delta Live Tables will then manage the task orchestration, cluster management, monitoring, data quality, and error handling.
One of the great things about DLT is that you can use Python decorators to handle things like table dependencies or data quality. Coupled with Auto Loader, you will be able to load and transform your data with a very low amount of code. For more details and real examples, I suggest to take a look at these example notebooks.
You can also build a streaming pipeline that runs all the time and will ingest your streaming data. Migrating from a regular batch pipeline requires minimal changes as all the syntax is the same and you will be able to perform complex operations like joins and aggregations.
What is SCD2 (Slowly Changing Dimensions Type 2)?
Storing daily data in your data lake is the traditional way of operating and will provide historical data. Nothing wrong by doing that, and in most cases, having daily data is enough for your internal processes. But what if you could enhance your data by being able to know its period of validity?
For example, let's say that your system is saving estimate data for stocks and those estimates change over time. Portfolio managers are going to want to enhance their decision making by easily knowing when a given estimate was valid. Here is how it would look like in the tables:
Daily estimates for APPL:
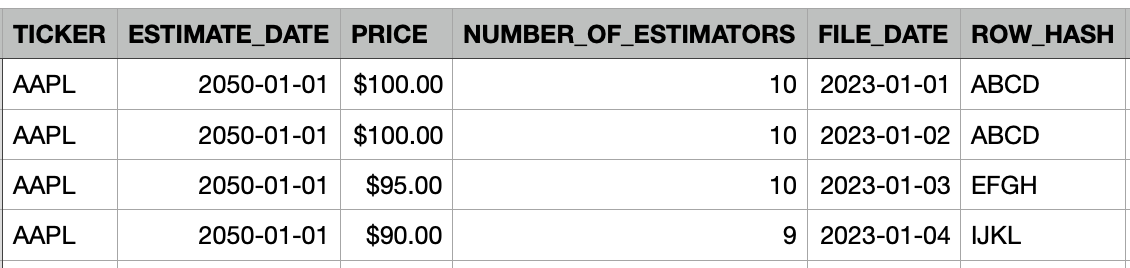
TICKERfor the stock tickerESTIMATE_DATEfor the date of the estimationPRICEfor the price estimationNUMBER_OF_ESTIMATORSfor how many estimators were used to calculate the priceFILE_DATEfor the date associated with the raw fileROW_HASHfor a hash calculated using all columns exceptFILE_DATE(to simplify comparing rows)
Daily estimates for APPL with SCD2:

You can see that 3 columns were added: START_DATE, END_DATE and IS_CURRENT. Those are the columns that will give you the history so you can query row-level change information.
For more details about all types of SCD, I recommend reading this great blog.
Retain history on your tables with DLT
To capture your data changes and retain history with DLT, you will just need to use the function dlt.apply_changes() and provide the correct parameters. Those parameters are very important and are going to be unique for each table. For more information about those arguments, please read the documentation of apply_changes(). Make sure that your DLT pipeline also has the configuration pipelines.enableTrackHistory set to true and that the edition is either Pro or Advanced.
Based on the dataset from above, here's how it would look:
import dlt
from pyspark.sql.functions import col, expr
@dlt.view
def stock_estimate():
return spark.readStream.format("delta").table("stock_estimate_raw")
dlt.create_streaming_live_table("stock_estimate_scd2")
dlt.apply_changes(
target = "stock_estimate_scd2", # The target table
source = "stock_estimate", # The temp view
keys = ["ticker", "estimate_date"], # Columns to uniquely identify a row
sequence_by = "file_date", # Logical order of the rows
stored_as_scd_type = "2", # To use SCD2
track_history_column_list = ["row_hash"] # To track changes of the whole row
)
With very low changes to your DLT pipeline, the stock_estimate_scd2 table will now track history by adding 2 new columns __START_AT/__END_AT and they can be queried to know the validity period of the row.
Usage in the finance world
To best support your portfolio managers, it's recommended that your data lake include financial and filings data. Bloomberg data is usually the best for that and your ELT process just has to process the data incrementally (since there is no estimate).
Then usually the next goal is to support forecasts and estimates made by stock analysts on the future earnings of publicly traded companies. The two major companies that provide that kind of data are Visible Alpha and Refinitiv and their estimates are provided through snapshots. Those snapshots will create duplicates in your database and also make the data hard to use as tracking changes will have to be done manually. Your Portfolio Managers will save a lot of time and make better decisions by having access to a row-level history using SCD2. That's why I recommend enhancing your ELT pipelines to support that feature by simply updating your DLT code or switching to the Databricks Lakehouse Platform.
Need help with your existing Databricks Lakehouse Platform in your Financial Institution? Or do you need help using the latest Data lake technology? Ippon can help! Send us a line at contact@ippon.tech.

Comments