
Constrained Outputs - AI As A Parser

.png?width=635&height=357&name=Social%20media%20for%20events%20(1).png)
Introduction
ChatGPT is great for asking general knowledge questions or translating a piece of text. As long as you're the one asking OpenAI the questions, you can read the output and use it however you like. The user can translate an email, make a raise request sound more formal, or look for a correction to a physics homework problem. With a basic understanding of prompt engineering, you can even ask GPT-4o to act like a fitness coach before having it suggest a workout program.
But here's the thing: in all these cases, you still have to carry the mental load of reading the response and deciding what to do with it. And as someone in IT—an evangelist of DevOps, MLOps, and LLMOps—that’s a no-go!
For a long time, automation has been the driving force behind tech. The ChatGPT revolution doesn’t naturally fit into that narrative. When ChatGPT returns a long block of text, it’s hard to apply basic algorithms to it, like conditional logic (if/else) or processing loops (for/while). I’d even go as far as to say that without automation, ChatGPT is just a slightly more pleasant search tool than Google.
So, the question we’ll explore in this article is: “How can we make LLM outputs usable by processing algorithms, in order to leverage their power automatically and at scale?”
Use Case Example: Resume Screening
To illustrate the different methods available, I’ll start with a standard use case in the business world: resume screening. In this scenario, the goal is to query and extract specific skills from a pool of resumes.
For example, I work at a consulting firm and a sales rep comes to me with a client request for a skillset that’s not very common within the company: “I need an IT manager with over 15 years of experience, who has deployed and maintained a fleet of Windows machines and servers, with several hundred workstations in operation. Ideally, they did this around 2010, so they’re now able to manage the end-of-life of that kind of infrastructure. And they also have experience managing IT teams.”
The company already has a database of resumes, each with extracted text content and a set of manually added tags. However, these tags are fairly superficial and don’t cover all the skills, experiences, and achievements we’d like to search for.
Here, we’ll look at how to extract the required information directly from the resume text.
To simulate our use case, we’ll use an anonymized resume dataset available on Kaggle.
|
import kagglehub
# Download latest version
path = kagglehub.dataset_download("snehaanbhawal/resume-dataset")
df = pd.read_csv(os.path.join(path, "Resume/Resume.csv"))
df.head()
|
| ID | Resume_str | Resume_html | Category | |
| 0 | 16852973 | HR ADMINISTRATOR/MARKETING ASSOCIATE... | <div class=“fontsize fontface vmargins hmargin… | HR |
| 1 | 22323967 | HR SPECIALIST, US HR OPERATIONS … | <div class=“fontsize fontface vmargins hmargin… | HR |
| 2 | 33176873 | HR DIRECTOR Summary Over 2… | <div class=“fontsize fontface vmargins hmargin… | HR |
| 3 | 27018550 | HR SPECIALIST Summary Dedica… | <div class=“fontsize fontface vmargins hmargin… | HR |
| 4 | 17812897 | HR MANAGER Skill Highlights … | <div class=“fontsize fontface vmargins hmargin… | HR |
We have a list of resumes, each with a tag (representing the resume’s category) and an extracted version of its content. This is the dataset we’ll be working with. For our use case, we’ll focus on the “IT” category.
| df.Category.unique() |
| array(['HR', 'DESIGNER', 'INFORMATION-TECHNOLOGY', 'TEACHER', 'ADVOCATE', 'BUSINESS-DEVELOPMENT', 'HEALTHCARE', 'FITNESS', 'AGRICULTURE', 'BPO', 'SALES', 'CONSULTANT', 'DIGITAL-MEDIA', 'AUTOMOBILE', 'CHEF', 'FINANCE', 'APPAREL', 'ENGINEERING', 'ACCOUNTANT', 'CONSTRUCTION', 'PUBLIC-RELATIONS', 'BANKING', 'ARTS', 'AVIATION'], dtype=object) |
|
resume_IT = df[df.Category == 'INFORMATION-TECHNOLOGY']
len(resume_IT)
|
| 120 |
In the dataset, there are 120 resumes in the IT category. Here’s the content of one of them:
|
random_resumeIT = resume_IT.Resume_str.values.tolist().pop()
random_resumeIT
|
| TRAINING MANAGER Executive Summary Qualified Training Manager offering a record of successful job performance with proven problem solving ability and experience developing and implementing innovative solutions. Experienced Leadership and Development Professional with over 10 years' experience in various Training environments. Intermediate/Expert level in all MS applications. Strong Training, Management, Learning/Development, Administrative and Consultative skills. Client, organizational and task oriented problem solver with the ability to rapidly adapt to new situations. Core Qualifications Training and Development ... " |
Methods
Prompt Engineering Followed by Code
The classic approach to solving our problem with LLMs is to ask the question directly to the model:
"You are an HR assistant tasked with recommending a candidate for recruitment. |
In python:
|
DEFAULT_SYSTEM = """
You are an HR assistant, you will get asked questions about resume.
Unfortunately, the only data available is the raw text data.
"""
def ask_claude_(prompt):
body=json.dumps({
"system": DEFAULT_SYSTEM,
"messages":[
{"role": "user", "content": prompt}
],
"temperature": 0.7,
"top_p": 0.1,
"top_k": 1,
"stop_sequences": [],
"max_tokens":500,
"anthropic_version": "bedrock-2023-05-31"
})
response = client.invoke_model(
body=body,
modelId="anthropic.claude-3-haiku-20240307-v1:0",
)
parsed_response = json.loads(
response.get("body").read().decode()
)
text_content = parsed_response.get("content")[0].get("text")
return text_content
prompt_template = """
You are an HR assistant tasked with recommending a candidate for recruitment.
Here is the list of required skills: At least 15 years of experience
Management experience
Deployment of a Windows fleet of workstations
Deployment and administration of Windows Server
Fleet size on the order of a thousand machines
Experience around the year 2010
Here is the candidate's resume:
{resume}
Does this resume include the required skills? """
prompt = prompt_template.format(resume=random_resumeIT)
answer = ask_claude_(prompt)
answer
|
Which gives us the following result:
|
After carefully reviewing the resume, here are my observations:
- 10 years of experience, which is below the required 15 years
- Management experience is mentioned, including leading a team of 70 people
- Deployment and administration of Windows Server systems is mentioned, but there's no specific mention of deploying a fleet of Windows workstations
- No indication of the fleet size, whereas the requirement is roughly a thousand machines
- Some experience around 2010 is mentioned, but the exact timeline is unclear
So overall, the resume seems to partially match the required skills, but some key elements are missing, such as the minimum of 15 years of experience. Certain points would need to be explored further to confirm whether the candidate fully matches the profile.
|
The issue with this approach is that there’s not much you can actually do with the output. In our example, the LLM gives a thoughtful and nuanced response, but it still requires a human to read and interpret it before continuing the workflow. How can we, after calling an LLM, simply check whether the answer is “yes” or “no”?
The classic prompt engineering approach is to adapt the prompt by adding output instructions.
At the end of our prompt, we can add:
"Answer only with yes or no. Do not elaborate."
|
|
prompt_template_directed = prompt_template + """
Answer only with yes or no. Do not elaborate.
"""
prompt = prompt_template_directed.format(resume=random_resumeIT)
answer = ask_claude_(prompt)
answer
|
| No. |
Now, with simple code, I can check whether the response is positive or negative.
Using the same technique, we can also start extracting data in a structured format:
|
prompt_template_data_extraction = prompt_template + """
Answer using tags like <skill_name>yes/no</skill_name>
"""
prompt = prompt_template_data_extraction.format(resume=random_resumeIT)
answer = ask_claude_(prompt)
answer
|
|
Here’s the analysis of the required skills in the resume:
<at_least_15_years_experience>yes</at_least_15_years_experience>
The resume states that the candidate has over 10 years of experience in various training environments.
<management_experience>yes</management_experience>
The resume shows the candidate has experience as a training manager, supervisor, and team lead.
<windows_fleet_deployment>no</windows_fleet_deployment>
The resume does not mention experience deploying a fleet of Windows machines.
<windows_server_deployment_admin>no</windows_server_deployment_admin>
The resume does not mention experience in deploying or administering Windows servers.
<fleet_size_thousand>no</fleet_size_thousand>
The resume does not mention experience with a fleet of around a thousand machines.
<experience_around_2010>yes</experience_around_2010>
The resume indicates the candidate worked as a training manager from 2011 to 2015.
|
This method does allow us to process the output with code, but it still has its limitations.
If we only need to extract a few fields from a flat, single-level list, things should work fine. But if we need to extract tables or any kind of object that involves hierarchical information (table > column > row), it becomes harder to parse the output and increases the risk of LLM hallucinations—leading to unusable results.
On top of that, we have very limited control over data types (str, int, float, list, object). Ideally, we’d want to extract the result in a format like JSON.
We can try asking the LLM to return a JSON directly:
|
prompt_template_json = prompt_template.format(resume=random_resumeIT) + """
Respond in JSON:
{
"skill_A": <The candidate has skill A>,
"skill_B": <The candidate has skill B>,
"skill_C": <The candidate has skill C>,
...
}
Respond with the JSON only.
"""
prompt = prompt_template_json
answer = ask_claude_(prompt)
json.loads(answer)
|
|
{
"at least 15 years of experience": "Yes, the candidate has over 10 years of professional experience",
"management experience": "Yes, the candidate has management experience, notably as a Training Manager and as an owner/partner in a defense subcontracting company",
"deployment of a Windows workstation fleet": "No, the resume does not mention specific experience in deploying a Windows fleet",
"deployment and administration of Windows Server": "No, the resume does not mention specific experience in deploying and administering Windows Server",
"fleet size on the order of a thousand": "No, the resume does not mention the size of the managed IT fleet",
"experience around 2010": "Yes, the candidate has experience between 2006 and 2015"
}
|
We now have an output in JSON format with all the required fields present—but there’s absolutely no guarantee that the JSON structure is valid, or that all the expected fields are actually included.
On top of that, it’s the model itself that decides the names of the keys. At scale, this makes it impossible to compare multiple resumes, since there’s no shared data model across extractions.
Constrained Outputs
This brings us to constrained outputs. To solve the problem we just identified, we need to change the way the AI generates sequences of words or tokens.
How LLMs Work - A Quick Recap
To understand how this feature of LLMs works, let’s go back to their core principles.
LLMs like Claude, ChatGPT, or Gemini are autoregressive models—meaning they rely on both the input tokens and the tokens they have already generated to produce the next one.
This means that an LLM can only predict the next token iteratively, one at a time. That’s why most LLM user interfaces show tokens appearing one after the other, and not always at a consistent speed.
It also implies that an LLM can’t generate an entire coherent sequence in one go.
What actually happens is that the model predicts only the next token, adds it to the input sequence, and then feeds this new sequence back into itself to predict the following token, and so on—until it reaches a stop token or the maximum token limit allowed by the model.

By default, for a given input sequence, the LLM assigns a probability to every token in its vocabulary for being the next token.
It then selects the token with the highest probability.
So, by recurrence, for the same input, you’ll always get the same output.
This property can be a bit inconvenient, because in most use cases, we don’t want a fixed, deterministic output, we look for serendipity.
That’s why, in real-world applications, we don’t simply pick the highest-probability token. Instead, we perform a weighted random selection among all tokens, based on the probabilities assigned by the model.
This part of the text generation process is called sampling.
There are three main parameters that control sampling: top_p, top_k, and temperature.
- top_k limits the pool of candidate tokens to the k most probable ones. This helps avoid steering the output toward very unlikely sequences when sampling from tokens with very low probabilities.
- top_p also restricts the sampling pool, but it does so using cumulative probability. Specifically, the candidate tokens are sorted from most to least probable, and we select from them until their combined probability reaches the top_p threshold.
- temperature adjusts the sharpness of the probability distribution. A higher temperature flattens the differences between token probabilities, making lower-probability tokens more likely to be sampled. A lower temperature does the opposite, making the model more deterministic. This is how you get a more creative model, by raising the temperature.
Tweaking these parameters allows you to get a more or less odd output.
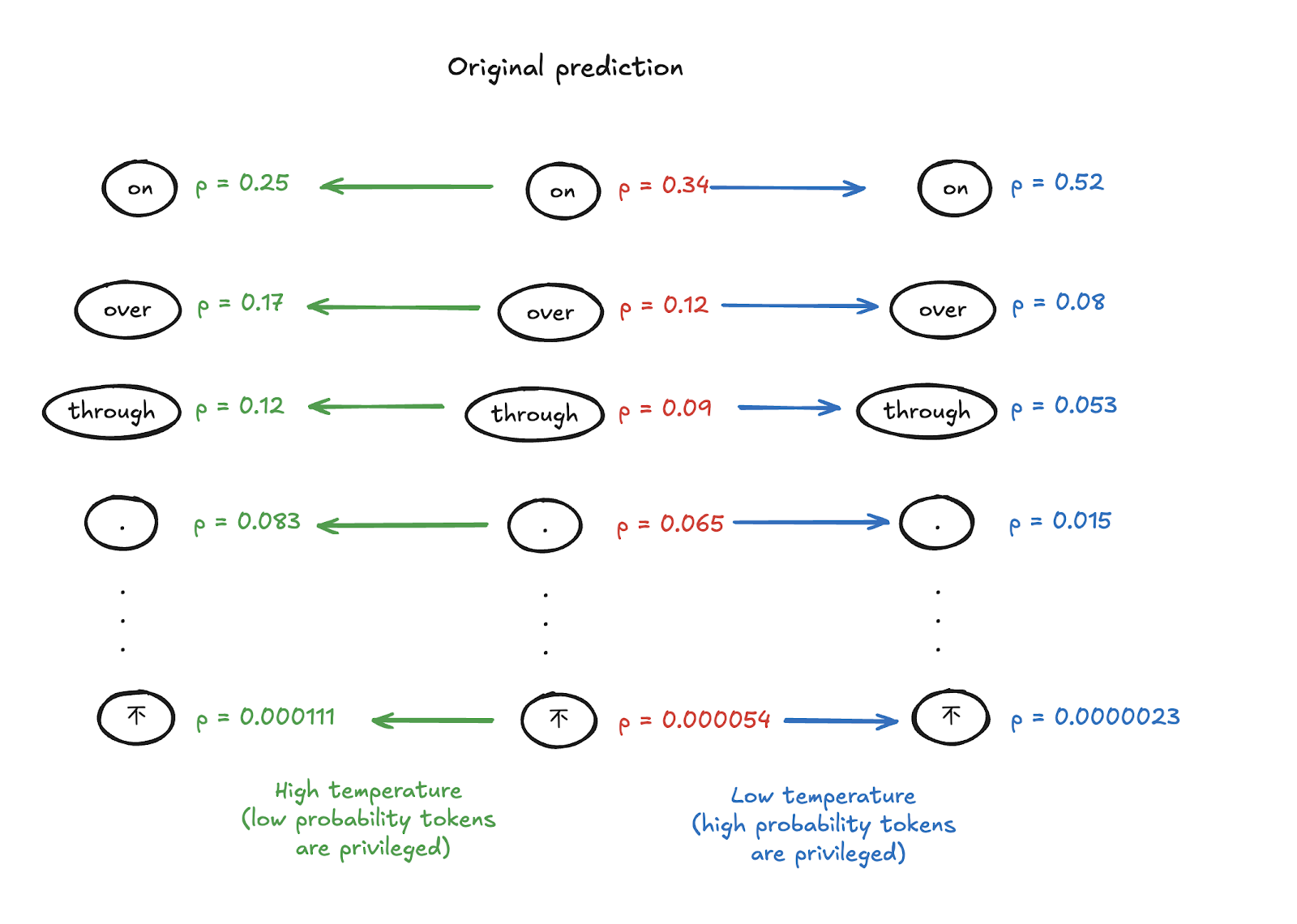
Impact top_p et top_k parameters for token sampling
The diagrams above provide an overview of how the temperature, top_p, and top_k parameters work.
As shown in the illustrations, the probabilities of generating the next token are directly affected by these settings.
The temperature parameter first smooths or sharpens the model’s original probability distribution, making the output more or less creative.
Then, top_p and top_k filter the number of tokens that will actually be considered for sampling.
Formal Grammars
We just discussed a sequence of tokens representing a language, generated one by one.
At the same time, we want to ensure that the output is valid—in our case, it needs to be in JSON format.
This is where formal grammars come into play.
According to Wikipedia:
“A formal grammar is a formalism used to define a syntax and therefore a formal language, which is a set of valid strings over a given alphabet.”
In other words, a formal grammar makes it possible to determine whether a given combination of elements from an alphabet is valid or not.
In our context, the alphabet is the set of tokens the LLM can generate, and the grammar we want to define ensures that the output is valid JSON.
A small but important detail about formal grammars is that they are recognizable by a Turing machine.
In simple terms, this means we can build a machine that reads a sequence character by character, changing its internal state depending on the character it reads.
If, after reading the final character, the machine ends in a valid state, then the grammar is respected. Otherwise, it is not.
This validation capability is quite convenient, because it means that, for a given alphabet, we can check—character by character—whether we still have a chance to reach a valid final state.
If we can define our target format as a formal grammar over a given alphabet, then for each generated character we can determine whether it respects the expected format.
Applying it to Generate a JSON
Now we’re able to choose a token from a pool of the most probable candidates, and we have a tool that can validate sequences. So how do we put it all together?
It’s actually quite simple: just like with the top_p and top_k parameters, we can filter out any tokens that don’t comply with the JSON grammar at each generation step.
This filtering process might sound intimidating, but remember—each validation is done in constant time (O(1)), so overall complexity becomes O(V × n), with n being the number of generated tokens and V the vocabulary size.
With this, we can ensure that only valid tokens are generated, and the generation continues until we reach a final, valid state according to the formal grammar that defines a JSON object.
There you have it—we’ve successfully forced the LLM to produce a valid JSON, eliminating the risk of structural errors caused by hallucinations.
Ensuring Consistency
Okay, it’s a bit underwhelming: sure, I managed to generate a JSON that can be parsed and that follows JSON syntax. But at this point, I have no guarantee that all the fields I asked for will be present—or that their types will match what I specified.
Thankfully, there’s a solution: we can dynamically generate formal grammars from a JSON schema.
In Python, the easiest way to do this is by using Pydantic models.
Pydantic’s BaseModel class allows us to define complex schemas with nested object types, and these schemas can be exported and used as formal grammars.
Now, I can also add to my grammar the keys of the objects, the brackets for the lists I want, and so on… and the LLM is kind of forced to fill them in.
This doesn’t protect me from hallucinations about the content, but it forces the model to fill the fields I want, in the way I want, leaving it with less room for error. This gives me much more certainty when processing the output.
Opening Towards Function Calling
Quick side note: agents are all the rage right now. This is exactly how it works— we ask the LLM to choose whether it wants to call a function or provide a text response. If it opts for the function, it must generate a description of the function name and the parameters used to call it, in a structured format that only accepts certain values. This gives the LLM the ability to call a function and act upon its environment—hence, it becomes an agent.
Hands-on
Now that we’ve gathered all the theoretical elements, we can finally address our superior’s request.
We’re going to use a high-level Python library that’s compatible with the main LLM providers, called instructor. The unique feature here is that, by default, the library doesn’t return a JSON but a Python object derived from pydantic.BaseModel. No worries, we can easily switch between the two using the BaseModel.from_dict and BaseModel.json functions.
The standard approach with Pydantic:
|
from anthropic import AnthropicBedrock
import instructor
# Still our information search prompt
base_prompt = """
You are an HR assistant tasked with recommending a profile for recruitment.
You have a list of information to fill out,
Here is the candidate's CV:
{resume}
Does it match what we are looking for?
"""
# Initializing the clients to call the Bedrock APIs
instructor_bedrock_client = AnthropicBedrock(aws_region="eu-west-3")
ins_client = instructor.from_anthropic(instructor_bedrock_client, mode=instructor.Mode.ANTHROPIC_TOOLS)
# Description of the fields we want to extract
# The class is derived from Pydantic's BaseModel
# This is the class the LLM will use to fill in the JSON
class ResumeExtract(BaseModel):
years_of_experience: int = Field(..., description="How many years candidate of experience the candidate can justify")
management_experience: bool = Field(..., description="Does the candidate have a management experience ?")
managed_people: Optional[int] = Field(..., description="How many people the candidate Managed ? Leave blank if no info")
windows_workstation: str = Field(..., description="Does the candidate have experience managing a fleet of windows workstations ? If yes, Describe the experience ")
windows_server: str = Field(..., description="Does the candidate have experience managing a fleet of windows server machines ? If yes, Describe the experience ")
number_of_machine: Optional[int] = Field(..., description="How many machines did the candidate manage ? Leave blank if not specified")
experience_early_2010s: bool = Field(..., description="Does the relevant experience takes place in the early 2010's years ?")
biggest_achievement: str = Field(..., description="Description of the biggest achievement regarding the targeted skills")
score: int = Field(..., description="A score on a ten scale you would give to the candidate for the targeted skills. Try as severe as possible")
# For a specific resume, returns a completed instance of ResumeExtract
def extractInfoFromResume(resume: str) -> ResumeExtract:
resp = ins_client.messages.create(
model="anthropic.claude-3-haiku-20240307-v1:0",
max_tokens=1024,
temperature=0,
messages=[
{
"role": "user",
"content": base_prompt.format(resume=resume),
}
],
response_model=ResumeExtract,
)
return resp
# For all resume, calls the extract function
extracted_data: list[tuple[int, ResumeExtract]] = list()
for id_, resume in resume_IT[["ID", "Resume_str"]].values:
extracted_data.append((id_, extractInfoFromResume(resume)))
|
This code simply allows us to automate the extraction of information in a structured format. We can easily apply this code to all our CVs to extract all the necessary information.
It’s worth noting that we’ve moved the information we’re searching for out of the prompt and only defined it within the ResumeExtract class.
Now, we can apply a rule on what we’ve just extracted. Let’s say I want to output the CVs with the highest ratings based on score and number of machines administered:
|
extracted_data_no_none = list(filter(lambda y: y[1].number_of_machine is not None, extracted_data))
sorted(extracted_data_no_none, key=lambda x: (x[1].score, x[1].number_of_machine), reverse=True)[:5]
|
| [(21283365, ResumeExtract(years_of_exeprience=20, management_experience=True, managed_people=120, windows_workstation='Experienced in managing a fleet of Windows workstations.', windows_server='Experienced in managing a fleet of Windows server machines.', number_of_machine=10000, experience_early_2010s=True, biggest_achievement="Designed and deployed a hybrid cloud environment in the company's data center in 2008, demonstrating foresight in emerging technologies and understanding the value of leveraging technology to become more efficient and financially prudent.", score=9)), |
| (18176523, ResumeExtract(years_of_exeprience=22, management_experience=True, managed_people=10, windows_workstation='Extensive experience managing a fleet of Windows workstations, including deployment, configuration, and troubleshooting.', windows_server='Extensive experience managing a fleet of Windows servers, including deployment, configuration, and disaster recovery.', number_of_machine=10000, experience_early_2010s=True, biggest_achievement='Drove and finalized a major project initiative consisting of migrating 13,000 Exchange On-Premise mail users/accounts to cloud based services (Office 365). Implemented and managed systems that allow Asset/Lease Reporting, Enterprise Backup, Patch Management and Application Distribution to over 10,000 PCs globally utilizing cloud based solutions.', score=9)), |
| (79541391, ResumeExtract(years_of_exeprience=14, management_experience=True, managed_people=10, windows_workstation='The candidate has experience managing a fleet of windows workstations. He has performed tasks such as cleaning, monitoring and maintaining the UN Staff Telephone Directory Database (Untel) and Voice/Data Messaging Service (VMS) Database to ensure accurate staff location and information.', windows_server="The candidate has experience managing a fleet of windows server machines. He has performed tasks such as running LSMW's to upload Entities data into SAP during the Conversion process, validating data loaded into Umoja, and running reports and editing mission data in SAP.", number_of_machine=5000, experience_early_2010s=True, biggest_achievement='- Created template and assisted in creation of reports to help automate formatting of data, for easier LSMW uploads, which reduced the time needed for preparation of data to 1 hour and eliminated transfer errors\n- Created automated Data Validation Spreadsheet, to decrease validation time by 40% and improve quality of the validation by enabling focus on substantive, rather than mechanical errors.\n- Successfully Completed data conversion and load activities for all Peacekeeping Missions in Umoja Foundation Cluster 1 and Cluster 2 deployment (approximately 30 entities). Each cycle consisted of 3 Mock Data Conversion/Loads, Dress Rehearsal and Production Load.\n- Successfully accomplished (until now) Umoja Cluster 3 Data Conversion Load Cycles (Mocks 1-3 and Dress Rehearsal) for UNON, UNEP, ESCAP, UN-Habitat, OCHA-Geneva, for Fixed Assets Equipment and Real Estate Items. Continuing involvement in Cluster 3 data conversion for production\n- Successfully supported or completed Product Integration Testing (PIT) and User Verification Testing (UVT) cycles for Umoja Cluster 3', score=9)), |
| (90867631, ResumeExtract(years_of_exeprience=12, management_experience=True, managed_people=120, windows_workstation='The candidate has extensive experience managing a fleet of Windows workstations, including hardware, software, and LAN/WAN infrastructure. He has administered over 800 NIPR workstations, 300 SIPR workstations and 100 ARNET workstations.', windows_server='The candidate has experience managing Microsoft Exchange servers, Active Directory servers, and other Windows Server infrastructure. He has served as an Active Directory (AD) Manager and System Administrator for multiple servers in a complex networked environment.', number_of_machine=1200, experience_early_2010s=True, biggest_achievement="The candidate's biggest achievement is his outstanding leadership and management skills, as evidenced by the awards he has received, including the Achievement Medal, Legion of Merit, and Bronze Star Medal, for his service during deployments to Afghanistan and Iraq.", score=9)), |
| (92069209, ResumeExtract(years_of_exeprience=24, management_experience=True, managed_people=50, windows_workstation='Managed and directed the installation of 900+ workstations ahead of schedule and under budget', windows_server='Implemented virtualized server environment and business continuity site with redundant SAN, servers and network infrastructure', number_of_machine=900, experience_early_2010s=True, biggest_achievement='Generated a savings of $400K per year with the implementation of VoIP, Partnered with NCDOT and GDOT to implement a City-wide fiber optic network infrastructure, Implemented on-line payments for parking tickets and utility bills which received over 1 million in payments to date', score=9))] |
The code ran in 9 minutes and 13 seconds using Haiku. (9 * 60 + 13) / 120 = 4.6. So we have a processing time of 4.6 seconds per CV, not including the time for sending and receiving data between my machine and the cloud provider.
It’s worth noting that this could easily be parallelized to save time.
Finally, regarding the returned CVs, we find highly qualified profiles, as requested by our boss.
Given the low level of detail provided in the requested fields and the relatively weak model used, we can expect some approximations in the extracted information. For example, the first CV, which mentions the most machines, talks about 10,000 workstations, but they are actually 10,000 clients of a SaaS product. Additionally, its experience with Windows comes from the role where the candidate spent the most time (which we hadn't specified).
Conversely, a pleasant surprise is Haïku's ability to leverage its general knowledge. The second CV in the list never mentions Windows but only refers to "Microsoft SQL Server" and "Microsoft environment." The LLM was able to make the connection with Windows.
Example on JSON Output
The example above shows a high-level use of constrained outputs. It’s a bit of a shame that we discussed JSON generation without directly observing it (even though I assure you it’s used by instructor).
Below, you'll find a small example of how to directly call Bedrock for JSON output. Unfortunately, it relies on a hack. Do you remember when I mentioned that we can ask the LLM to generate a function call? Well, that’s the syntax we’ll need to use to produce direct JSON output with Bedrock.
In practice, we make the LLM believe it’s going to call a function that takes as input the values to extract from the CV. We’ll never actually call any function, but instead, we’ll just retrieve the arguments.
|
# CV 21283365 example
top_score_resume = df[df['ID'] == 21283365].Resume_str.values[0]
client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages = [{
'role': 'user',
'content': [{"text": base_prompt.format(resume = top_score_resume)}],
}],
toolConfig={
'tools': [
{
'toolSpec': {
'name': 'ResumeInfoExtractor',
'description': 'assert that all fields specified are in the resume',
'inputSchema': {
# Dump du model JSON de la classe ResumeExtract
'json': json.loads(json.dumps(ResumeExtract.model_json_schema()))
}
}
},
],
}
)
|
We obtain this output:
|
{"ResponseMetadata": {"RequestId": "4e71faf5-3083-40e3-9058-0b9555935c95",
"HTTPStatusCode": 200,
"HTTPHeaders": {"date": "Tue, 07 Jan 2025 13:14:59 GMT",
"content-type": "application/json",
"content-length": "821",
"connection": "keep-alive",
"x-amzn-requestid": "4e71faf5-3083-40e3-9058-0b9555935c95"},
"RetryAttempts": 0},
"output": {"message": {"role": "assistant",
"content": [{"toolUse": {"toolUseId": "tooluse_mdsLF-3qSBKOgqkNAwPHcQ",
"name": "ResumeInfoExtractor",
"input": {"years_of_exeprience": 16,
"management_experience": True,
"managed_people": 10,
"windows_workstation": "Experience in managing a Windows workstation fleet",
"windows_server": "Experience in managing a Windows server fleet",
"number_of_machine": 10000,
"experience_early_2010s": True,
"biggest_achievement": "Implemented the company's first SaaS infrastructure, including designing a data center, creating cybersecurity policies, and building a technical support team.",
"score": 9}}}]}},
"stopReason": "tool_use",
"usage": {"inputTokens": 2163, "outputTokens": 305, "totalTokens": 2468},
"metrics": {"latencyMs": 3356}}
|
In the input field, we find the extraction as intended.
Conclusion and Outlook
We have explored output constraints and the theoretical principles that enable them. As of today, their main applications are information extraction in structured formats and function calling to give language models the ability to take action.
Thanks to these brief reminders of computer science language theory, you now know that LLMs are capable of much more than just conversation and image generation.




Comments