
Snowflake is a native Cloud Relational Database that is a Data Warehouse as a Service (DWaaS) solution. As a DWaaS, Snowflake handles all of the resource management, availability, configuration, authentication, data protection and optimization. All that is needed is to load and use the data! Snowflake is currently available on Amazon AWS and Microsoft Azure cloud platforms, and, as announced during the Snowflake Summit, will be available on Google Cloud Platform(GCP) in preview in Fall 2019. Snowflake has made connections extremely easy by partnering with many BI, Data Integration, and Advanced Analytical tools. It also provides ODBC, JDBC, Go, .Net. Node.js drivers, connectors for Python, Spark, and Kafka (in public preview as of June 4, 2019), SNOWSQL CLI and works with tools like DBWeaver.
The architecture behind Snowflake’s performance, scalability, and ease of use is based on a shared data, multi-cluster design, as shown below.
Let’s walk through the layers of this architecture to really get to know Snowflake…
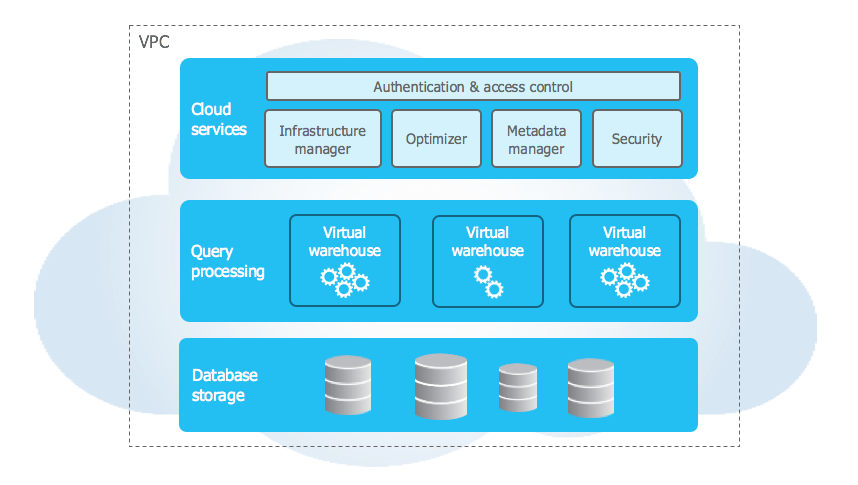
Database Storage Layer
In the Storage Layer, data is compressed, encrypted using AES 256 and stored in the columnar format. Partitioning is done automatically, but can be configured.
Snowflake supports semi-structured data like JSON, AVRO, Parquet, XML and ORC with a datatype called variant in addition to regular structured data types like varchar and number.
Query Processing Layer
The Query Processing or Compute Layer is where the queries are run. Snowflake uses “Virtual Warehouses” - independent node clusters that can all access the same data (hence shared data) and most importantly without the issues of resource contention or performance degradation at peak times.
Cloud Services Layer
The Cloud Services layer is where the Snowflake orchestration and management happens. It is responsible for Authentication & Access Control (Ensuring only authenticated users can access only the objects they are authorised to), Infrastructure Management (managing cloud resources to ensure high availability and fault tolerance) Query Optimization (parse SQL and optimize without manual tuning and index creation), Metadata Management (logical and statistical data that is used by multiple services for eg. Query Optimization), Transaction Management (ensures that Snowflake is ACID), and Security (Ensure that data is encrypted at rest and in flight and is secure).
Now that we’ve taken a peek under the hood, let’s get to work…
Loading and Querying Data in Snowflake
Note: this assumes access to Snowflake on AWS either via an existing customer or partner instance or via the free trial signup.
Data can be loaded into Snowflake using inserts, bulk loading and limited loads via the web interface. Snowflake also offers SnowPipe for continuous ingestion.
For this example, we are going to use Snowflake on AWS and data from the GDELT project (Global Database of Events, Language and Tone: https://www.gdeltproject.org/) as it is publicly available on AWS S3 and it is a very interesting dataset.
We’re using SnowSQL CLI on a Mac to run the queries on Snowflake (All SQL commands can also be run via Snowflake Worksheets except the PUT command needed to load from a local file system)
To create a schema to store the tables as part of this exercise:
CREATE SCHEMA SAMPLE_SCHEMA;
To create the virtual warehouses for querying and loading:
CREATE WAREHOUSE LOAD_WH WAREHOUSE_SIZE = XSMALL AUTO_SUSPEND = 60 AUTO_RESUME = TRUE;
CREATE WAREHOUSE ANALYSE_WH WAREHOUSE_SIZE = XSMALL AUTO_SUSPEND = 60 AUTO_RESUME = TRUE;
The above commands creates warehouses of the smallest size and sets them to suspend after 60 seconds of inactivity and to resume automatically. In practice, of course, the size and parameters will be different based on requirements. A fun exercise would be to change the sizes and see how much time it takes. (Note: Snowflake caches query results to enable faster results and also maintains which files have been loaded to a table to avoid re-loading)
To set the schema in which the table will be created:
USE SCHEMA SAMPLE_SCHEMA;
Loading data
For bulk loading, Snowflake has 3 options for stage: User (associated and accessed by the specific user), Table (associated with the specific table) or Named Stage, a database object and can be used to load multiple tables and access given to multiple users. For this post, we will create named stages.
Loading data from AWS S3
To create the table for the GDELT data. This particular data file has a lot of columns and we’re loading them all but you could re-order the columns or choose only a subset of the columns to actually load into the table as part of the COPY command.
CREATE OR REPLACE TABLE GDELT_DAILYUPDATES (
GLOBALEVENTID number PRIMARY KEY, SQLDATE date , MonthYear varchar(6) , Year varchar(6) , FractionDate double , Actor1Code varchar(64) ,Actor1Name varchar(255) , Actor1CountryCode varchar(6) , Actor1KnownGroupCode varchar(6) ,Actor1EthnicCode varchar(6) , Actor1Religion1Code varchar(6) , Actor1Religion2Code varchar(6) , Actor1Type1Code varchar(6) , Actor1Type2Code varchar(6) , Actor1Type3Code varchar(6) , Actor2Code varchar(64) , Actor2Name varchar(255) , Actor2CountryCode varchar(6) , Actor2KnownGroupCode varchar(6) ,
Actor2EthnicCode varchar(6) , Actor2Religion1Code varchar(6) ,Actor2Religion2Code varchar(6) , Actor2Type1Code varchar(6) , Actor2Type2Code varchar(6) , Actor2Type3Code varchar(6) , IsRootEvent number(11) , EventCode varchar(6), EventBaseCode varchar(6), EventRootCode varchar(6), QuadClass number(11) , GoldsteinScale double , NumMentions number(11) ,
NumSources number(11) , NumArticles number(11) , AvgTone double , Actor1Geo_Type number(11) , Actor1Geo_FullName varchar(255) , Actor1Geo_CountryCode varchar(6) , Actor1Geo_ADM1Code varchar(6), Actor1Geo_Lat float , Actor1Geo_Long float , Actor1Geo_FeatureID varchar(20) , Actor2Geo_Type number(11) , Actor2Geo_FullName varchar(255) ,
Actor2Geo_CountryCode varchar(6) , Actor2Geo_ADM1Code varchar(6) ,Actor2Geo_Lat float , Actor2Geo_Long float , Actor2Geo_FeatureID varchar(20) , ActionGeo_Type number(11) , ActionGeo_FullName varchar(255) , ActionGeo_CountryCode varchar(6) ,ActionGeo_ADM1Code varchar(6) , ActionGeo_Lat float , ActionGeo_Long float , ActionGeo_FeatureID varchar(20) , DATEADDED number(11) ,SOURCEURL varchar(255)
);
Note: Snowflake supports defining primary and foreign key constraints for reference purposes and does not enforce them.
Snowflake allows loading into a table directly from an AWS S3 bucket but recommends creating an external stage that references the S3 bucket. You could also create named file formats for commonly used ones that can then be used in the file_format parameter below.
CREATE OR REPLACE STAGE stage_gdelt url='s3://gdelt-open-data/events/'
file_format = (type = 'CSV' field_delimiter = '\t');
If the data is not publicly available, S3 credentials will need to be provided at this stage(!)
For Copy and other sql queries require that the Virtual Warehouse to be used for their execution
USE WAREHOUSE LOAD_WH;
Now to load the files into the final table. The below will load all files in the s3 url defined above that match the pattern:
copy into GDELT_DAILYUPDATES
from @stage_gdelt
pattern='.*2019052.*.export.csv' FORCE=TRUE;
Note: The initial .* regular expression in the above pattern parameter is required even though the filename begins with 2019.
Loading JSON semi-structured data from a local file system
For this exercise, We use the following excerpt from a GDELT lookup to create a JSON file, and store it in our local filesystem as gdelt_type.json:
{
"event_code": "ENV",
"event_label": "Environmental"
},
{
"event_code": "HLH",
"event_label": "Health"
}
Create the table for the JSON data using Variant is the datatype that Snowflake uses to store semi-structured data and enables you to query its elements
CREATE TABLE gdelt_type_json (src variant);`
Creating the stage for the JSON file
CREATE OR REPLACE STAGE stage_dim file_format = (type = json);
For loading a local file into Snowflake, it first needs to be uploaded to Snowflake by explicitly putting it into stage
put file://<filepath>/gdelt_type.json @stage_dim;
Load the data into the target table:
copy into gdelt_type from @stage_dim;
Querying Data
Switching to use the Analyse_WH created earlier for querying:
USE WAREHOUSE ANALYSE_WH;
Using standard SQL to analyze and query the data.
To get the top 10 countries with the most events:
select Actor1CountryCode, count(*) as event_cnt
from GDELT_DAILYUPDATES group by Actor1CountryCode
order by count(*) desc limit 10;
To query semi-structured JSON data:
select * from GDELT_TYPE_JSON;
Using SQL to query elements of the JSON data (flatten can be used to access nested elements too) :
select src:event_code::string, src:event_label::string from GDELT_TYPE_JSON;
There are plenty of things to love about Snowflake, here are a few highlights:
Scalability: Since it is designed and built for the cloud, Snowflake fully leverages the elasticity to offer near infinite scalability. Also, since storage is decoupled from compute, they are independently scalable.
Flexibility: Being able to scale storage, compute, number of users quickly based on requirements and changing the size of a warehouse from a menu is so cool (pun intended)
Pay As You Use: Snowflake billing allows Pay per second and auto-suspend, auto-resume of the virtual warehouses so customers are not paying for “off” times when the warehouses are idle.
Data Cloning: Snowflake lets you clone datasets for say, QA without needing to store (and pay for) the entire dataset multiple times.
Secure Data Sharing: Snowflake lets you securely share read-only access to data with one or more consumers without having to transfer the data out of Snowflake.
Note: During Snowflake Summit 2019, Snowflake announced the Data Exchange that provides a data platform for customers to easily and quickly acquire and leverage data from various data providers.
Personally, I’m very excited about Snowflake due to the low barrier to entry in terms of
Infrastructure: Traditional data warehousing infrastructure can be time-consuming and expensive at the outset of a project whereas Snowflake customers do not even need AWS or Azure accounts.
SQL: A language most folks who work with databases are already familiar with
Cost: Free credit provided by Snowflake worth $400 to try it out for 30 days.
All of which make it easier to: Go out and play in the snow(flake)!
For more information on how Ippon Technologies, a Snowflake partner, can help your organization utilize the benefits of Snowflake for a migration from a traditional Data Warehouse, Data Lake or POC, contact sales@ipponusa.com.


Comments