


MongoDB is one of the most popular NoSQL databases. Its unique capabilities to store document-oriented data using the built-in sharding and replication features provide horizontal scalability as well as high availability.
Apache Spark is another popular “Big Data” technology. Spark provides a lower entry level to the world of distributed computing by offering an easier to use, faster, and in-memory framework than the MapReduce framework. Apache Spark is intended to be used with any distributed storage, e.g. HDFS, Apache Cassandra with the Datastax’s spark-cassandra-connector and now the MongoDB's connector presented in this article.
By using Apache Spark as a data processing platform on top of a MongoDB database, you can benefit from all of the major Spark API features: the RDD model, the SQL (HiveQL) abstraction and the Machine Learning libraries.
In this article, I present the features of the connector and some use cases. An upcoming article will be a tutorial to demonstrate how to load data from MongoDB and run queries with Spark.
“MongoDB connector for Spark” features
The MongoDB connector for Spark is an open source project, written in Scala, to read and write data from MongoDB using Apache Spark.
The latest version - 2.0 - supports MongoDB >=2.6 and Apache Spark >= 2.0. The previous version - 1.1 - supports MongoDB >= 2.6 and Apache Spark >= 1.6 this is the version used in the MongoDB online course.
The connector offers various features, most importantly:
- The ability to read/write BSON documents directly from/to MongoDB.
- Converting a MongoDB collection into a Spark RDD.
- Utility methods to load collections directly into a Spark DataFrame or DataSet.
- Predicates pushdown:
- Predicates pushdown is an optimization from the Spark SQL's Catalyst optimizer to push the
wherefilters and theselectprojections down to the datasource.
With MongoDB as the datasource, the connector will convert the Spark's filters to a MongoDB aggregation pipelinematch.
As a result, the actual filtering and projections are done on the MongoDB node before returning the data to the Spark node. - Integration with the MongoDB aggregation pipeline:
- The connector accepts MongoDB's pipeline definitions on a MongoRDD to execute aggregations on the MongoDB nodes instead of the Spark nodes.
In reality, with most of the work to optimize the data load in the workers done automatically by the connector it should be used in rare cases. - Data locality:
- If the Spark nodes are deployed on the same nodes as the MongoDB nodes, and correctly configured with a
MongoShardedPartitioner, then the Spark nodes will load the data according to their locality in the cluster. This will avoid costly network transfers when first loading the data in the Spark nodes.
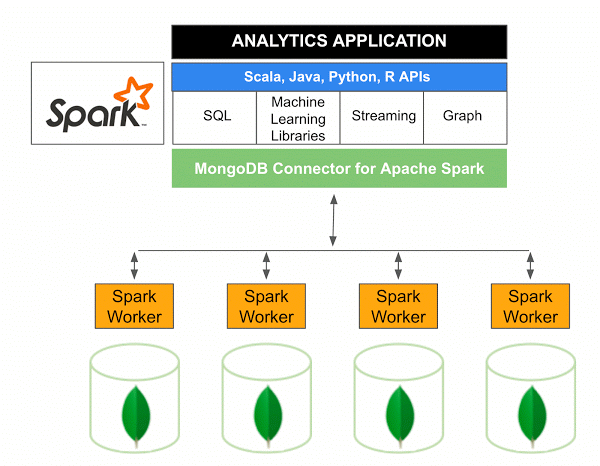
Spark nodes deployed next to the MongoDB nodes
Use cases
Different use cases can apply to run Spark on top of a MongoDB database, but they all take advantage of MongoDB’s built-in replication and sharding mechanisms to run Spark on the same large MongoDB cluster used by the business applications to store their data.
Typically, applications read/write on the primary replica set while the Spark nodes read data from a secondary replica set.
To provide analytics, Spark can be used to extract data from MongoDB, run complex queries and then write the data back to another MongoDB collection. This has the benefit to not introduce a new data storage while using the processing power of Spark.
If there is already a centralized storage - a Data Lake, for instance, built with HDFS - Spark can extract and transform data from MongoDB before writing it to HDFS. The advantage is to use Spark as a simple and effective ETL tool to move the data from MongoDB to the data lake.
Conclusion
In this article, I have listed the MongoDB connector features and use cases.
The connector is fully functional and provides a set of utility methods to simplify the interactions between Spark and MongoDB.
Data locality - the ability to load the data on Spark nodes based on their MongoDB shard location - is another optimization from the MongoDB connector but requires extra configuration and is beyond the scope of this article.
In the next post, I will give a practical tour with code examples on how to connect Spark to MongoDB and write queries.


Comments