


When you ship an application to production, one of the key factors of quality is the monitoring capabilities of this application. In this post, we will see what options are available for your JHipster applications, and we will dive down into using Datadog.
Observability
Observability is the ability to understand what an application is doing, and how well it is performing.
We usually talk about the 3 ways of observability:
- metrics: numbers that are reported, such as the memory used by the application, the number of calls to an API endpoint...
- logging: the events that happened
- tracing: the measure of how much time each component took to perform an action.
I recommend watching Adrien Cole's talk:
We will see in this post if we can achieve these 3 principles of observability with a JHipster application.
Basic monitoring with JHipster
Out of the box, JHipster provides you with a page to display the metrics of your application.
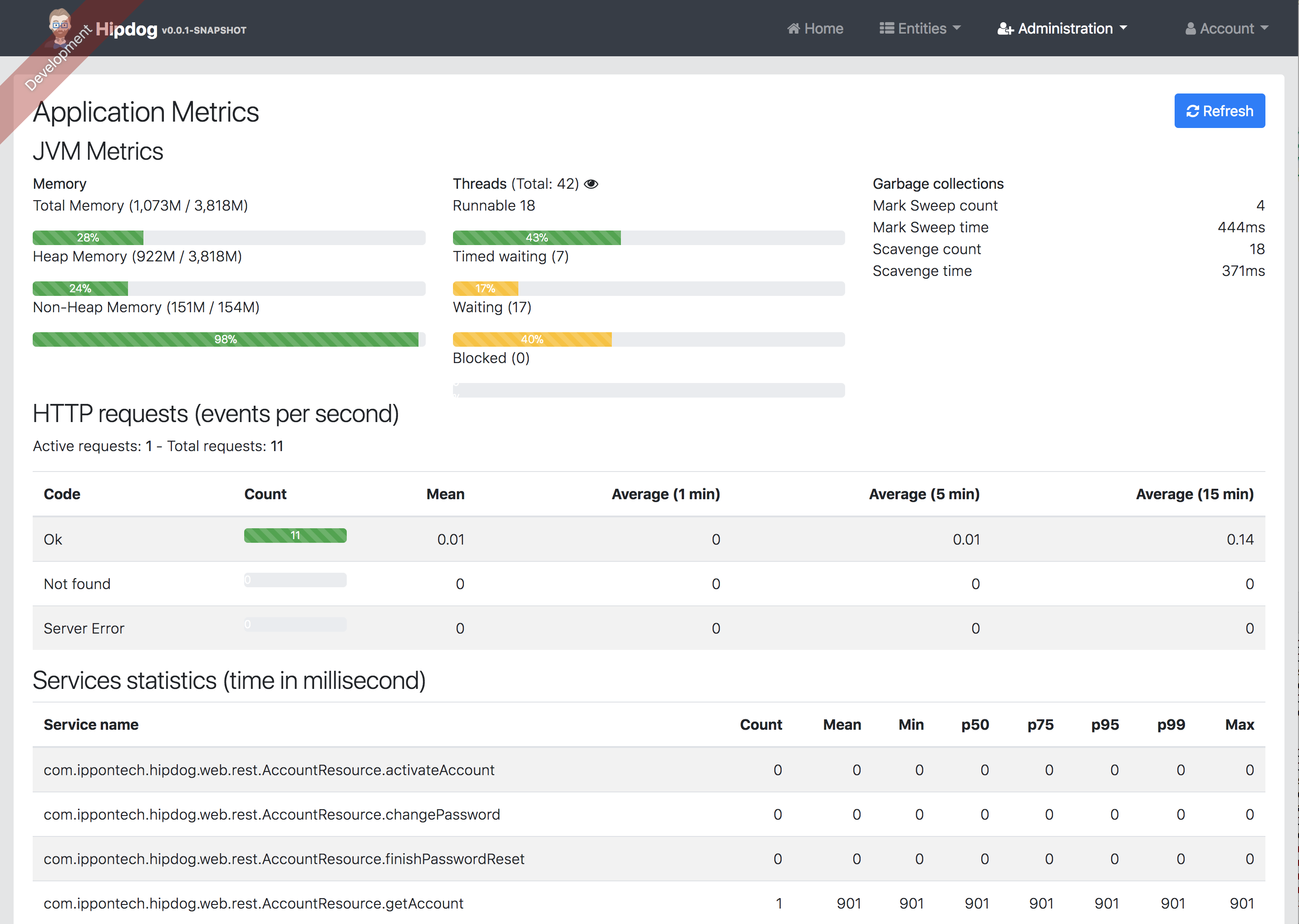
We also get the logs of our application on the console, and we can redirect them to a file by changing the configuration. Log levels can also be adusted on the file to get more or less details.
This is a great start, but we're missing 3 things:
- tracing: you would need to use other products for this
- history of the metrics: you only get a live view of the metrics
- centralized and aggregated storage: if your app is distributed (multiple instances or multiple microservices), finding important imformation will be difficult.
JHipster Console & Zipkin
JHipster offers a console as a separate product. It provides a dashboard to visualize your metrics. Since JHipster Console is based on Elasticsearch and Kibana, logs and metrics are archived and searchable.
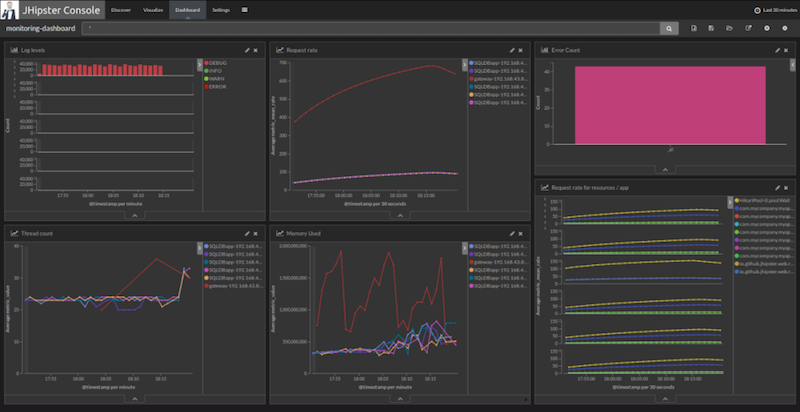
Integration with Zipkin is also possible to get distributed tracing of your application.
See JHipster's monitoring documentation page for more information.
Integration with Datadog
Now, if you already use Datadog, you probably want to send your metrics/logs/tracing to this service. If you don't know Datadog, it is a monitoring solution as a service. They provide an agent to install on your machine/server/EC2 instance, and the agent will ship metrics and logs to Datadog's servers. They then offer a UI to dig into your data.
I am not going to go through the features provided by Datadog, but instead show how to configure your JHipster application to send its monitoring information.
Reporting metrics
Let's start with the metrics. A JHipster application uses Dropwizard Metrics to collect and ship metrics to another system. In this case, we want to ship the metrics to Datadog. Let's start by adding Metrics Datadog Reporter to our build.
I'm using Gradle, so I'm adding this line to my build.gradle file:
compile 'org.coursera:dropwizard-metrics-datadog:1.1.13'
If you are using Maven, you would add this to your pom.xml:
<dependency>
<groupId>org.coursera</groupId>
<artifactId>dropwizard-metrics-datadog</artifactId>
<version>1.1.13</version>
</dependency>
Now, we're going to modify the MetricsConfiguration class. You can add the following code as the end of the init() method:
EnumSet<Expansion> expansions = EnumSet.of(COUNT, RATE_1_MINUTE, RATE_15_MINUTE, MEDIAN, P95, P99);
HttpTransport httpTransport = new HttpTransport.Builder()
.withApiKey(apiKey)
.build();
DatadogReporter reporter = DatadogReporter.forRegistry(metricRegistry)
.withHost(InetAddress.getLocalHost().getHostName())
.withTransport(httpTransport)
.withExpansions(expansions)
.build();
reporter.start(10, TimeUnit.SECONDS);
You will then need to retrieve your API key. Once you have that key, you will most likely want to put it the application.yml file and inject its value as a property of the MetricsConfiguration bean.
Once this is done, the application will send its metrics to Datadog every 10 seconds. You can then visualize them on Datadog, and create dashboards:
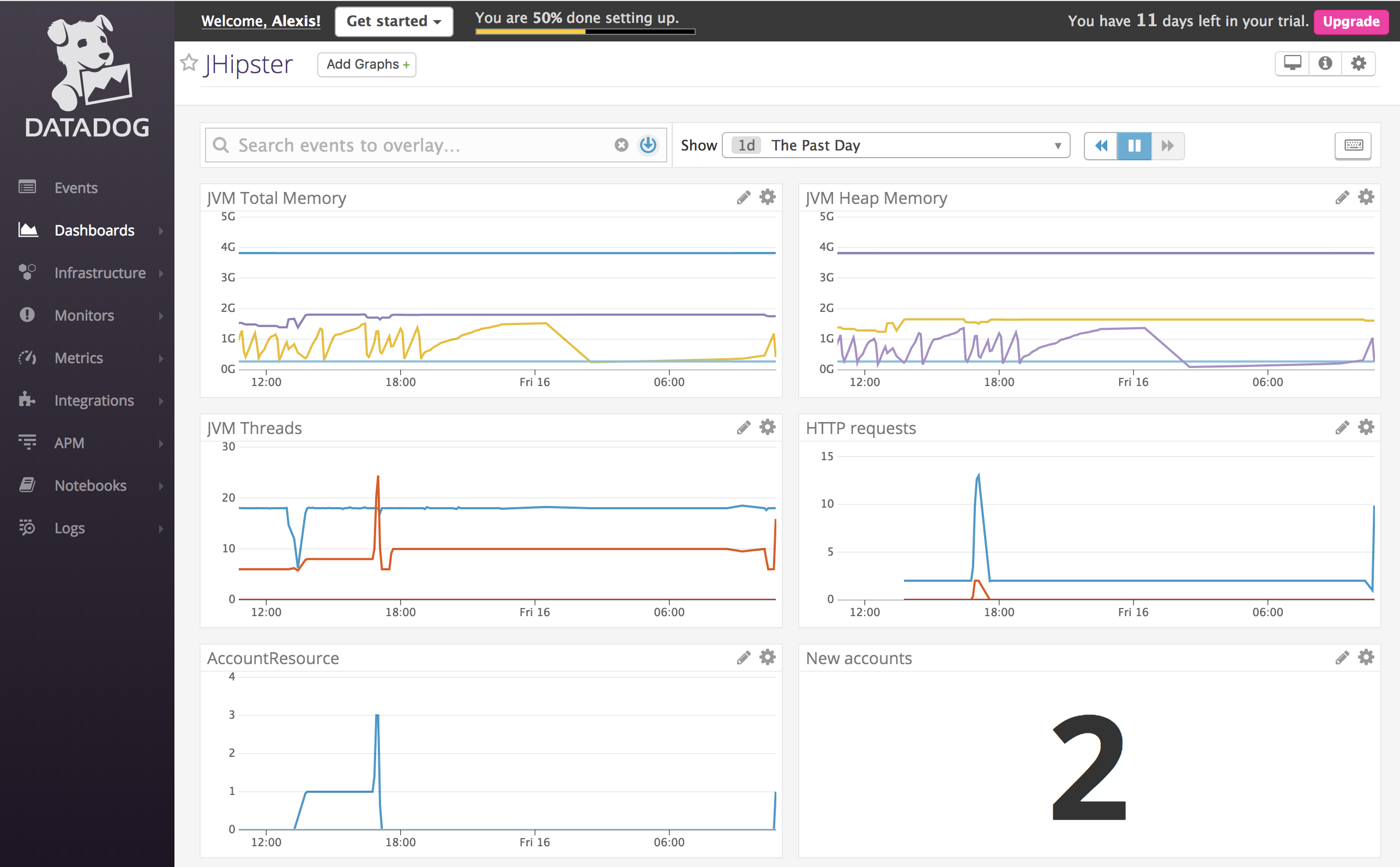
Reporting logs
The next step is to send our logs to Datadog. Datadog recently acquired Logmatic, and the product is now integrated in the service.
There are 2 ways to send your logs to Datadog:
- have your application write its logs to a file, and use Datadog's agent to read from this file
- have the agent listen for TCP or UDP connections, and have your app send its logs straight to the agent.
We're going to use files. It is - in my opinion - easier to inspect and debug.
We first need to configure JHipster to log to files. Open the logback.xml file and add the following configuration:
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>logs/logFile.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>90</maxHistory>
</rollingPolicy>
<encoder>
<charset>utf-8</charset>
<Pattern>%d %-5level [%thread] %logger{0}: %msg%n</Pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="FILE" />
</root>
Logs will still be written to the console, but also written to files in the logs directory.
Now, let's configure the Datadog agent to collect the logs. Start by enabling the log collection feature in the datadog.yaml file:
logs_enabled: true
We then need to create a configuration file for Datadog's agent. My application is called "HipDog", so I am creating a file called conf.yaml in a hipdog.d folder (/opt/datadog-agent/etc/conf.d/hipdog.d/conf.yaml), with the following content:
logs:
- type: file
path: /Users/aseigneurin/dev/jhipster-datadog/logs/*.log
service: hipdog
source: jhipster
log_processing_rules:
- type: multi_line
name: new_log_start_with_date
pattern: \d{4}\-(0?[1-9]|1[012])\-(0?[1-9]|[12][0-9]|3[01])
Now, if you restart the Datadog agent and wait a few seconds, your logs should start appearing in the UI:
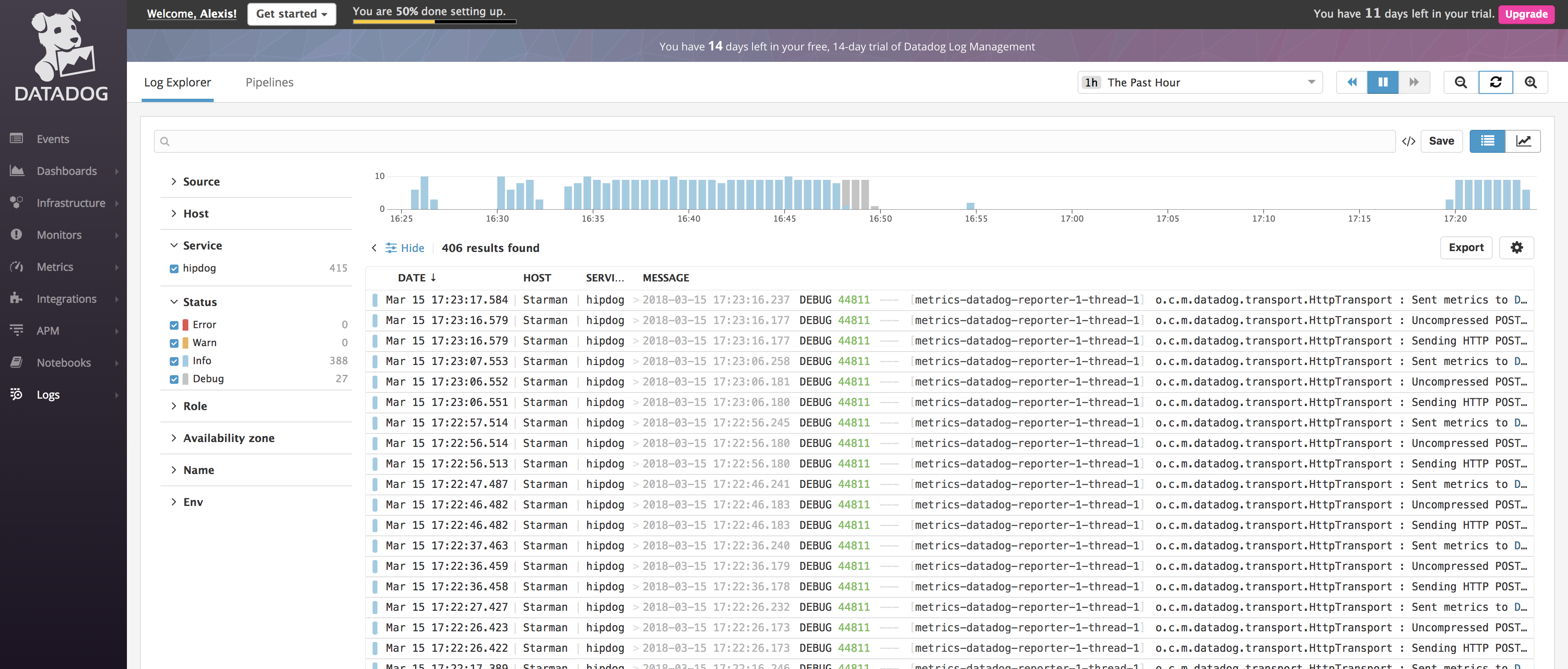
Notice that, at this point, we've only shipped the logs. They're not parsed yet, meaning the timestamps may be a little off (they correspond to when the agent read the lines), and the level will always be INFO.
What we need is to define a "Pipeline". You would define a Grok parser:
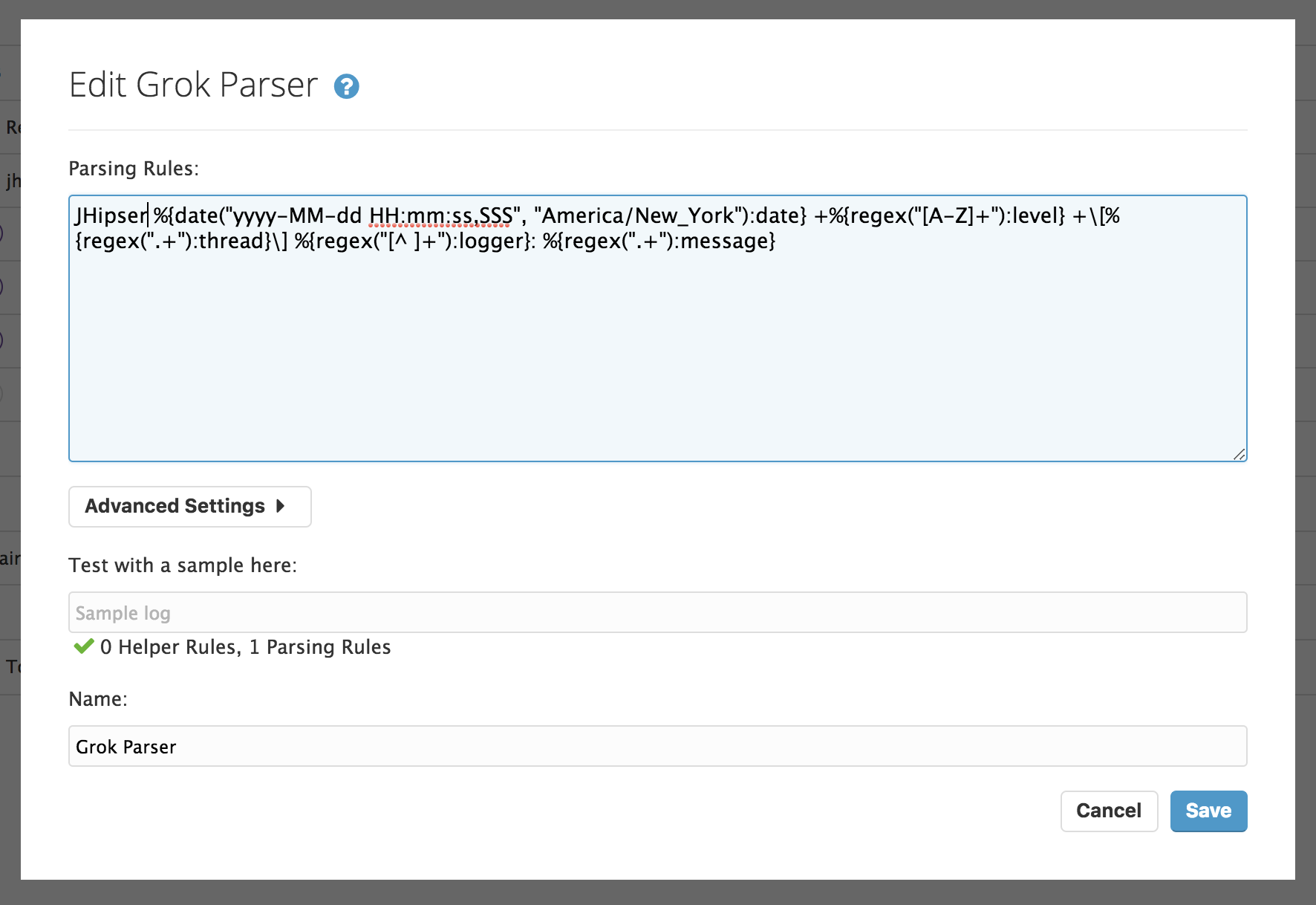
The configuration I used is:
JHipsterRule %{date("yyyy-MM-dd HH:mm:ss,SSS", "America/New_York"):date} +%{regex("[A-Z]+"):level} +\[%{regex(".+"):thread}\] %{regex("[^ ]+"):logger}: %{regex(".+"):message}
Make sure you specify the correct time zone (or, better, configure Logback to output logs with a timezone indication), otherwise your timestamps will be shifted by a few hours and be rejected by Datadog (the ingestion process will not consider logs that are more than 5 hours old or 2 hours in the future).
We then need to add 2 other components to our Pipeline:
- a Log Status Remapper, to remap the level we found in the log lines to the level attribute
- a Log Date Remapper, to use the timestamp we parsed rather than the agent's timestamps.
Once done, you should be able to see extra attributes in your logs:
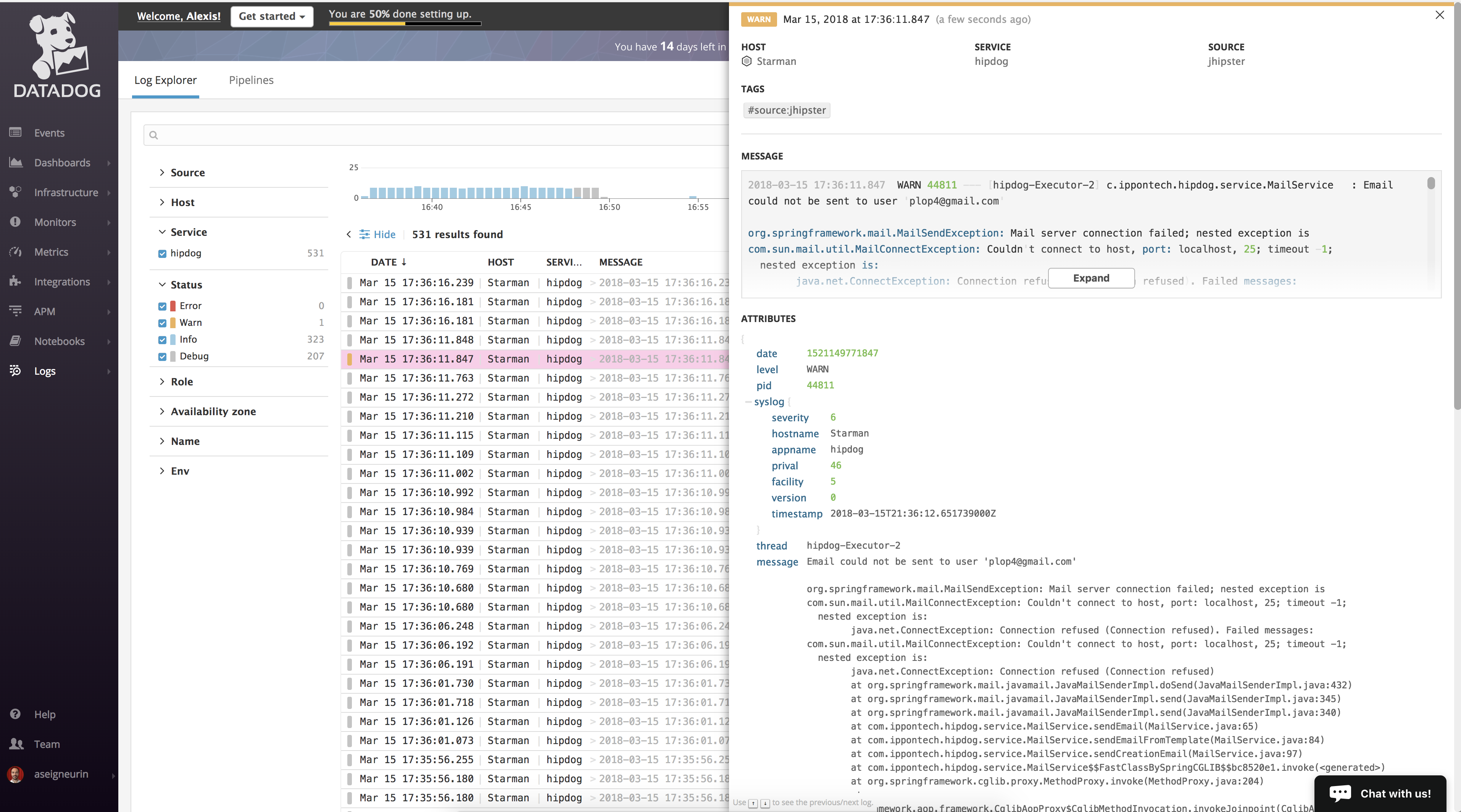
You will also be able to search / drill down into your logs.
Reporting tracing information
Datadog has a feature called APM to collect and analyze traces from your application. For the JVM, you need to download a JVM agent and enable it:
-javaagent:dd-java-agent.jar -Ddd.service.name=hipdog
Traces would then be sent from the JVM agent to the Datadog agent, and then to Datadog, allowing you to analyze the traces online:
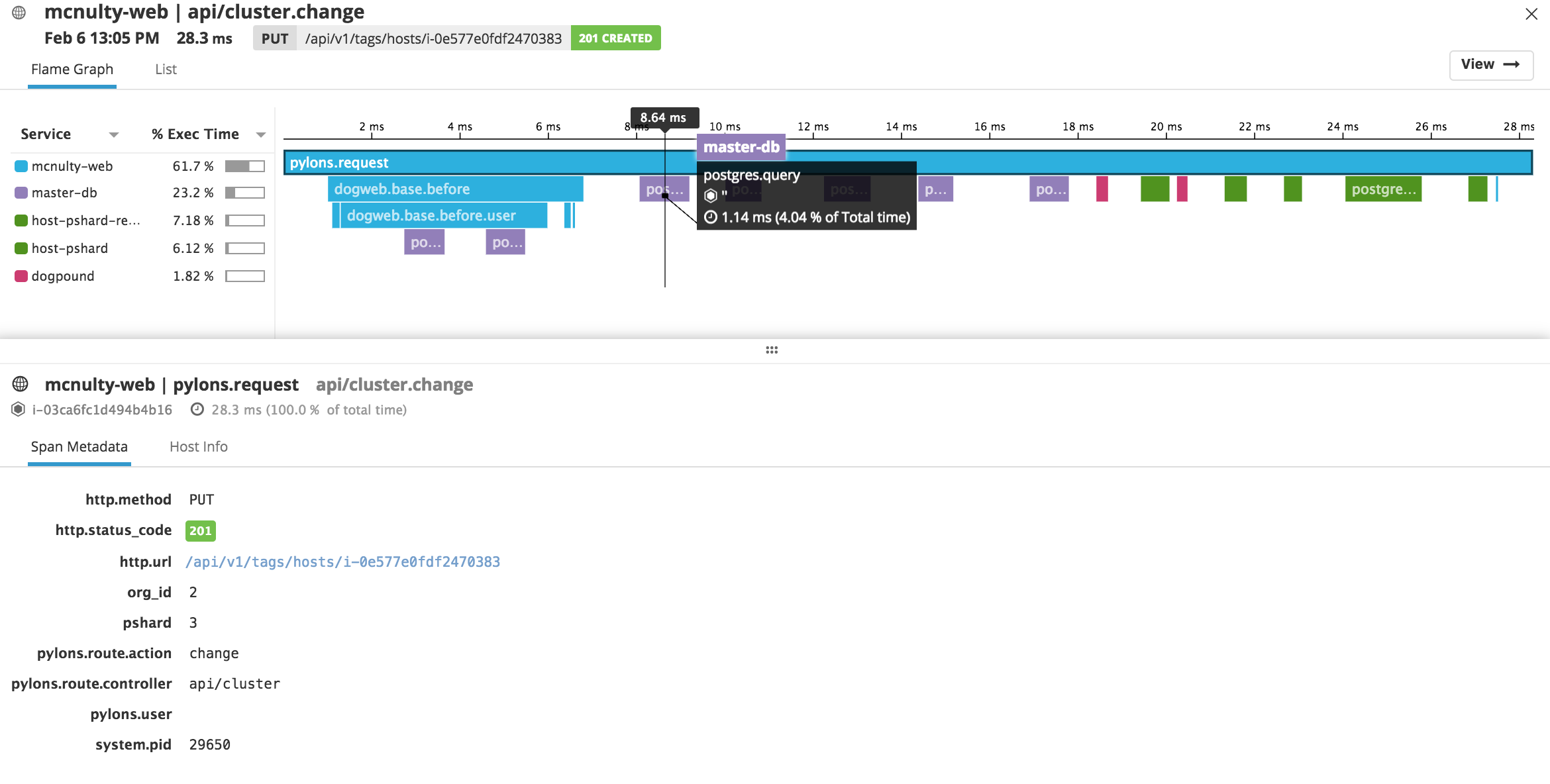
Unfortunately, so far, I haven't been able to get this to work. I will update this post as soon as I have found the issue.
Conclusion
If we ignore the fact that I wasn't able to enable the APM functionality, Datadog allows us to achieve the 3 ways of Observability for our JHipster application. This is very easy to configure and provides a very easy-to-use UI. If we had had microservices, we would even had been able to provide an aggregated view of the health of our platform!
The main drawback is that we cannot provide a default configuration for Datadog's UI that would suit any JHipster application. It would be nice to be able to provide a dashboard, as well as a pipeline configuration, to import into Datadog. We may be able to provide an integration and get it accepted by Datadog...


Comments