As we know, the IT industry is constantly evolving: hardware evolutions, the advent of IoT, new services offered by Cloud Providers, etc. The software development industry is no exception to this trend. In addition to new Web frameworks coming out faster than our learning abilities, application architectures are also being rethought and redesigned. Until recently, we all thought that a good old monolith was THE most simple, effective and cheap solution.
With the growth of containers and DevOps tools, a new panel of architectures emerged: Microservices architectures are one of them. Simple, scalable and quick to develop - when leveraging generators such as JHipster - they created a new way to develop Web applications. However, like any new architecture, this one comes with its own set of drawbacks. One of them is infrastructure management: even though DevOps and containers have contributed a lot to deal with this problem, they haven’t solved it.
Today, a new way of designing architectures is born: Serverless computing.
What is Serverless computing?
Serverless architectures refer to applications that depend on third party services (known as Backend as a service or BaaS) or on custom code executed in fully managed, ephemeral containers (Function as a Service or FaaS). The best-known FaaS service provider as of now is AWS Lambda.
Nowadays progress in FrontEnd technologies has allowed us to eliminate our "Always On" server needs. Depending on the circumstances, such systems can significantly reduce operational cost and complexity and can therefore be reduced to paying only usage fees (bandwidth, storage volume). A key feature of Serverless computing is that we only pay for what we use.
Like many trends in software, there is no clear meaning of what “Serverless computing” is, and this has not been helped by the fact that there are really two different but overlapping domains:
- “Serverless” was first used to describe applications that are significantly or totally dependent on third-party applications/services to manage their server logic and state. These are usually "client oriented" applications (think of single-page web applications or mobile applications) that use the vast ecosystem of databases accessible in the cloud (such as Parse, Firebase, AWS DynamoDB, etc ), authentication services (Auth0, AWS Cognito), etc. These types of services were previously described as Backend as a Service (BaaS).
- “Serverless” can also describe applications where a certain amount of backend logic is written by the developer, but unlike with traditional architectures (e.g., Monolithic), this logic gets executed in stateless containers, often triggered by events, or within an ephemeral (only an invocation) and fully managed service by a third party. This corresponds to the concept of Function as a Service or FaaS. AWS Lambda is one of the most popular FaaS implementations at the moment, but there are others competitors (Google Functions, Azure Functions, OpenWhisk).
In this article, we are referring to the second definition because it is more recent and is most at odds with the vision of a traditional technical architecture (it is simply more hyped!).
Serverless is made of servers!
The term "Serverless" is confusing because regardless of the implementation, there is still inevitably a server involved. The main difference is that the company creating and supporting an application, running on a Serverless platform, effectively outsources the server management aspects to a provider (AWS, Google, Azure,...), and so can focus only on the functional part of the application.
Some use cases
Let's now study concrete cases of using Serverless. You can find more details on these architectures and even real examples by visiting Amazon Web Services - Labs.
Real-time file processing
The first architecture we will see is about file processing. This architecture works very well when you need to have several transformations of a datasource before you can generate different output formats.
Therefore, we can use a concatenation of many functions to carry out our entire data processing process.
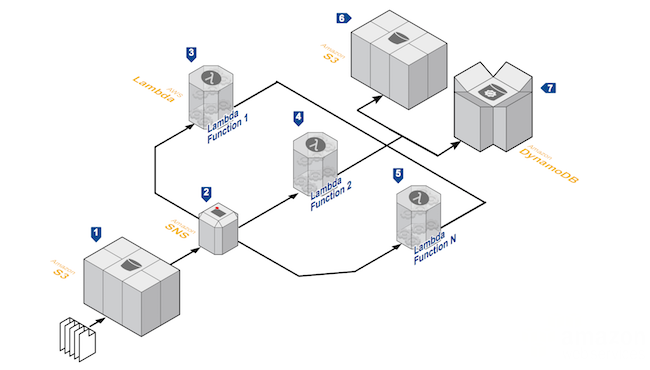
Web Application
By combining FaaS with other managed services, developers can create powerful Web applications that automatically evolve in a highly available configuration across multiple data centers, without the administrative effort required for scalability, backup or data redundancy.
This architecture is an example of a dynamic voting web application, receiving information through SMS (using a BaaS service like Twilio or Amazon Pinpoint), aggregates the totals in a database and uses a file manager (S3 Bucket) to make the results available in real time.
This architecture can be quickly generated using Infrastructure As Code technologies (CloudFormation, Terraform).
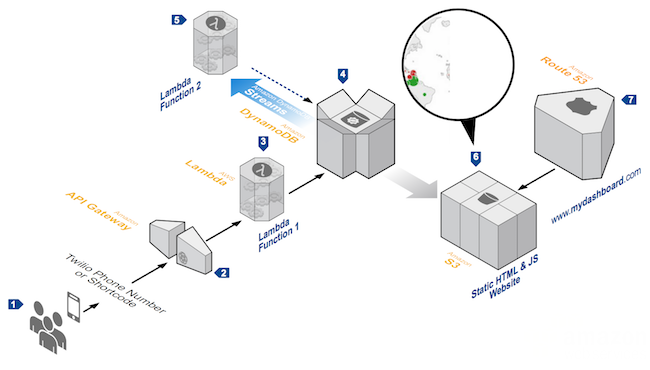
IoT Backend
This example based on IoT illustrates how data from connected devices can be retrieved and processed using Serverless architecture. By leveraging these services, you can create cost-effective applications that can meet and adapt to the massive demands generated by connected objects and have a near real-time processing architecture.
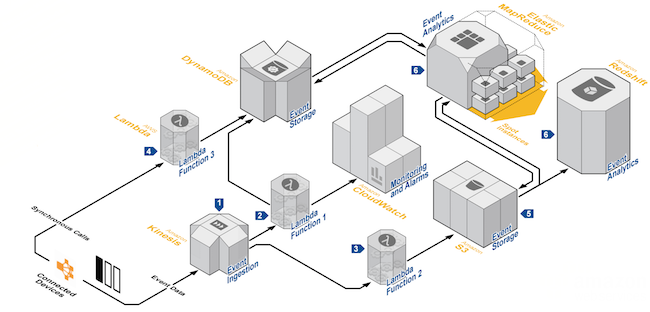
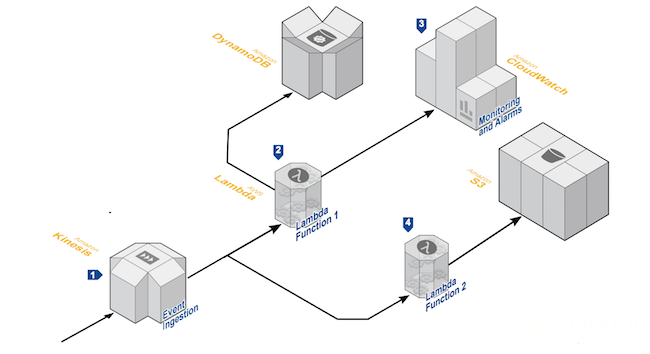
Processing a real-time data stream
You can use functions and data flow management services to process many use cases such as activity tracking, click analysis on a web application or even social media analysis.
Be careful, not everything is Serverless
So far, I have defined the term Serverless as the union of 2 principles - "Backend as a Service" and "Functions as a Service".
Before I start looking at what Serverless can do for you and what it can offer, I would like to explain what Serverless is not; at the moment, there are many incorrect definitions on the internet.
PaaS (Platform as a Service)
We can indeed find similarities between some PaaS services, such as Heroku, which offers on the fly deployments of our application, triggered by a simple command execution. However, these do not yet provide the abstraction level necessary to be considered Serverless. We always need to overallocate resources to ensure the healthy execution of our application or system.
Containers
Containers are becoming increasingly popular these days, especially since Docker. We can indeed find some similarities between FaaS and containers. But remember, FaaS offers a layer of abstraction so that we no longer have the notion of a system process, as opposed to Docker which is based on the notion of an unique process.
Among these similarities, we find the argument of scaling up. This functionality is readily available at the container level with systems such as Kubernetes, Rancher or Mesos. In this case we can ask ourselves the question of why use FaaS when we can use containers?
It is important to know that despite the buzz surrounding them, it is still immature and many companies are still struggling to shift their containers infrastructure into production. In addition, container-level scaling systems are still far from reaching the maturity of the FaaS, even if this gap tends to narrow itself with the introduction of new services such as Horizontal Pod Auto Scaling for Kubernetes or systems like AWS ECS (Elastic Container Service).
Finally, the choice of technology will depend on the use case.
#NoOps
Serverless should not be confused with NoOps. If we define the work Ops (Operations) this does not only mean system administration operations. It also means at least execution tracking, deployment, security, networking and also often a certain amount of production and system scale-up debugging. These problems still exist with Serverless applications, I should even say that they are more complicated given the youth of technology and the new features and parameters to be taken into account.
Serverless: Unicorn or fake
Serverless technologies are often compared to the land of unicorns because the promise they offer makes you dream and believe that unicorns exist. Let's take a closer look at this and see the benefits and drawbacks of this technology.
Benefits
Reduced operational cost
Serverless is a simple outsourcing solution. It allows you to pay a provider to manage servers, databases and even application logic. Since your service is part of a set of similar services, the concept of economies of scale will apply - you pay less for your infrastructure costs because the same service is used by many others, which reduces costs.
Reduced costs are the result of reducing:
- the cost of infrastructure
- the cost of employees (operations / development).
While some shared infrastructure (hardware, network) can result in direct cost savings, the goal is to go further and also reduce operating staff expenses, thanks to managed technologies.
This advantage, however, is not too different from what you will get by using technologies such as Infrastructure as a Service (IaaS) or Platform as a Service (PaaS).
Reduced development cost
To illustrate this point, let us take the case of authentication as an example. Many applications develop their own authentication and user management services, thereby implementing their own security levels. This functionality often includes:
- User registration and validation (Registration Deletion)
- Password recovery
- Connection and access to services
We find these features in most applications today. Even if application-generating solutions such as JHipster allow you to quickly generate several types of authentication implementations, it is still up to the developer to maintain this code and evolve it. Today, we are seeing the emergence of services such as Auth0 that provide "plug-and-play" authentication functionality so that the application can directly use these features while shifting the maintenance responsibility to the service provider.
Another example that lends itself to reducing costs is the use of synchronized database services such as Firebase. These use cases are common in mobile architectures that would favor direct communication between the client (mobile) and the database. These hosted services effectively eliminate the need for a backend database and associated administrative costs. This system also provides a new security layer that brings fine grained data access management controls associated with individual user profiles.
Autoscaling
For me, one of the most important advantages of Serverless is the automatic, elastic, and above all supplier-managed horizontal scaling. This can translate into several advantages, mainly at the infrastructure level, but above all it allows you to only pay for what you really need. You can get billed for the amount of computation time used (as fine grained as 100 ms for AWS Lambda) or for the amount of data recovered or analyzed. Depending on your architecture and Use Cases, this can generate huge savings for you.
One example of cost optimization is the occasional use of a function. For instance, let's say you run a server application that processes only 1 request every minute, takes 50 ms to process a request, and your average CPU usage for one hour is 0.1%. From a server workload perspective, this is extremely inefficient.
FaaS technology captures this inefficiency and allows you to pay only for what you consume, i.e. 100ms (minimum value) per minute, less than 0.5% of the total time.
Be a better developer, think about optimization
While this new architecture offers new features such as scalability, it still faces the constraints of application development. In this way, the function optimization phase takes on even more value as it not only improves the response time for users, but also saves money on the bill. For example, for an operation that initially takes 1 second and after optimization takes 200ms, we will have an immediate 80% invoice discount.
Being and Thinking Green IT
We have seen the number of datacenters rapidly growing year after year . The resulting energy consumption is enormous and cloud providers are taking this into consideration by building and hosting some of their Datacenters in areas with high renewable energy potential, to reduce the environmental impact of these sites.
With traditional servers, there is inevitably waste in terms of maintenance and consumption of "inactive" servers. These kinds of servers are not only inefficient but they also have a significant environmental impact. These unused expenses are mainly the result of decisions made by companies on the capacity required to run an application and the so called "over-provisioning for safety". With a Serverless approach, we no longer have to decide how much compute or storage capacity we need, because the service provider will automatically allocate those for us, in a cost effective way..
Drawbacks
As unicorns do not exist, Serverless also comes with its share of inconveniences and constraints that are not to be taken lightly, as these could become your worst nightmare depending on your use cases.
However, these drawbacks can be separated into two categories: those inherent with this new kind of architecture, and those that result from its youth and its lack of tools and solutions.
Cloud provider lock-in
The first, and not the least for me, is the strong dependency we create with the service provider. At the time of this writing, no specification has been released in order to adopt a common language between suppliers. Even if some frameworks (like serverless.com) try to break these limitations, when designing your solution and choosing the functionality, you will have to choose a single supplier to guarantee a certain homogeneity of communication between the different layers and to overcome the locking that the suppliers make of their services. For example, for the API Gateway to AWS Lambda connection, you need to use both AWS services to guarantee it will work. You will still be able to find gateways to use multiple service providers (Authentication through Auth0, DB with Firebase and API + Lambda on AWS) but in this case, it will make administration and billing estimation for your solution very difficult.
The same goes for the code used to write the functions, as it is specific to each supplier and you will therefore have to foresee a rewriting cost when moving to another supplier.
Server-side optimizations
From the moment you decide to use Serverless technologies, you therefore give up control over certain third-party systems and their configuration. Even if 99% of the time this kind of management by the provider will suit your needs, 1% will still need a specific service configuration to improve its performance or its quality of service.
Security
I couldn't write an article about Serverless without mentioning the security of this technology. Many companies are becoming increasingly aware of the security of their applications and access to their data (especially since HIPAA). Serverless services will not escape the rule and will bring their own questions. I will try to focus on 3 of them, but there are many others to consider.
- When it comes to security, we often talk about the perimeter or area of action of a solution. This corresponds to the footprint one has on the Internet. The larger the footprint is, the larger the area of attack will be. Using multiple Serverless service providers will increase your footprint and creates a certain heterogeneity in your security policies. In this way you will increase your probability of malicious intent against your solution and the likelihood that one of these attacks will be successful.
- If you use a BaaS database service and allow direct access to your data through a REST API, you will lose the protection barrier that a traditional server application can provide because of its network configuration or server access restrictions. However, even if this problem is not a dead end, it should be taken into account when designing your application.
- Because the services you use are shared, you inherit the security issues inherent in the multi-holder service. For example, access to other client data through process sharing.
Implementation Drawbacks
Let us now turn to the drawbacks inherent in the currently available solutions. Let's keep in mind that this should evolve quickly given its rapid growth.
Execution time
A current limitation is maximum execution time for FaaS. Currently there is a 5 minute limit AWS Lambda, and a 9 minute limit for Google Cloud Functions. This constraint restricts the scope of Use Cases such as video processing or some batch work.
Function warm up
Another disadvantage that some FaaS implementations cause is the latency at startup (named cold start). In addition to the function's execution time, there is also up to a 10 second warming latency depending on the context (example when using a JVM). This is why some suppliers like Google restrict the number of compatible languages for their functions and thus allow only the use of Javascript (which is understandable given the performance of their engine).
Similarly we can observe network latencies when several lambda functions are created in series. We will detail this in more detail in the next paragraph.
Tests
There is a lot to say about development, and the same goes for tests. Even if some people think that "Testing is doubting", we have to deal with this point, especially since it is a serious drawback when using this type of service.
Some may think that because of the isolation of each function, it may be relatively easy to test them. Those people are right when speaking about unit tests because it's just a piece of code, but when we talk about integration tests it is not as straightforward. New questions arise, due to dependencies on external services (database, authentication). In these cases we need to think about their scope, and the relevance of carrying out these end-to-end tests. The majority of service providers don't offer testing specific functionality, such as easy before and after state management, or specific costing rules for tests.
When attempting to develop and test locally, you will need local stub systems that are not necessarily provided. On this point, Google differentiates itself from others by the fact that all its solutions are generally based on Open Source systems, so the community is quickly developing stubs for those services.
The same applies to the integration of FaaS services. It is still difficult to find a local implementation of the structure that embeds the functions. We will therefore have to use the final environment directly. Although staging concepts separate test use from production use, unfortunately this does not apply to all services.
Deployment & versioning
Currently, no successful pattern has been established for the packaging and deployment phases. That's why we are rapidly facing constraints on atomic function deployment. Take the case of a series of functions that run, to ensure a consistent deployment, you will have to stop your service at the origin of the triggering events, then deploy all your functions and then activate the service again. This can be a major problem for applications requiring high availability. The same goes for the application versioning and rollback phase.
Supervision
To date, the only possible solutions for monitoring and debugging your functions in detail are those provided by the service provider and are generally relatively immature. Even though enormous efforts are being made as with the release of AWS X-Ray, there is still a long way to go in order to have a complete and specific FaaS solution.
To conclude
We have seen in this article that Serverless technologies can bring a lot of automation and benefits, but it's not the only and best solution for your future architecture. You first need to think about your constraints before to choose this kind of services.
You should also remember that Serverless is still young. For your information, AWS Lambda technology launched 2 years ago and Google Functions have just been released to Beta phase. We still have few real case studies on massive serverless architectures, the first official one was during AWS re:Invent event in November 2017. But we can guarantee a good future for this technology given the way it evolves.



Comments