
The Models Are More Capable Than You Think - Using Them Well Is Another Story.


There's a lot of excitement in AI right now around chatbots and image generators, and rightly so. But some of the most interesting work happening in machine learning sits a bit further from the spotlight, and it's particularly relevant if you work in financial services. It's about prediction: getting AI to look at historical patterns in data and make reliable forecasts about what comes next.
I was interested in this, and it was a bit of a deep dive in terms of comparing models for forecasting using two decades of air quality data from the U.S. Environmental Protection Agency. The application was quite interesting. It was about predicting levels of air pollution in hundreds of American cities. But really, it was about the AI itself. What are the best tools for this kind of work? How do they work? And how do you go from a good model to a good model?
The Problem
The difficulty with forecasting air quality is that the levels of pollution aren't driven by a single factor, like a single type of input signal. Instead, they're driven by a bunch of different signals, all of which overlap with one another, and all of which operate on completely different timescales: daily, seasonal, industrial, and episodic, like a wildfire that can happen in a matter of hours. A good model has to contain all of that, and figure out which signals are actually relevant to any given prediction.
If you work in financial services, you probably recognize that description from your own work in fraud detection, credit risk, liquidity forecasting, customer churn, or any of the other problems that have a similar shape to air quality forecasting. The signal you need may be in the data from last week, or it may be a pattern from two years ago that rhymes with the current situation. The difficulty with traditional forecasting models is that they work in a fundamentally sequential manner: they take the past, work their way through it step by step, and by the time they get to the present, the past is no longer relevant to them.
This is the issue that a new type of AI model, or set of models, referred to as “transformers” was designed to solve. Rather than scanning history one step at a time, a transformer model looks at the entire history all at once and is able to determine which history is relevant to its prediction right now and which isn’t. It weighs the signals appropriately and ignores the signals that are not relevant to its prediction. The technology behind the popular language-based tools like ChatGPT is the same technology that makes it so effective in structured data scenarios.
The Exploration
I implemented and compared three different models to see where this generation of models truly brings value and where simpler models still hold their own.
The first was a simple sequential model called LSTM(Long Short-Term Memory), which has been the workhorse in time series forecasting for years. It’s reliable, fast, and everyone knows how it works. Then there was a more advanced, hybrid model known as the Temporal Fusion Transformer, which has the ability to identify both short-range and long-range patterns, and also learn which data points are actually relevant to each given prediction. Finally, there was a lighter variant called the Informer, optimized for extremely long historical windows - useful when you need to look back over many years rather than just weeks.
I used all three models on the same data and, perhaps most importantly, also broke out results on a city-by-city basis rather than just looking at aggregate results. This turned out to be perhaps the most important aspect, as some models looked great overall but fell apart on individual cities with unusual patterns. In financial terms, unusual patterns are never unusual patterns. They're your riskiest customers, your most unusual transactions, your most volatile periods - exactly when you want your model to perform best.
What Stood Out
Two results were noteworthy and warranted exploration.
The first was “explainability.” AI models are, for the most part, black boxes – meaning that while an AI model can provide an answer, it cannot provide any context for how it arrived at that answer. This is not true with the Temporal Fusion Transformer model. This model does provide context for how it arrived at an answer, including which part of history it drew on to provide that answer. I found that when I examined how it was working on air quality data, it was looking at the correct data - seasonal windows in different cities, and so on. This is appealing from a research perspective, but it is more than that in financial services. A risk model or lending model that cannot provide an “explainability” is not only technically deficient. It is often also legally deficient.
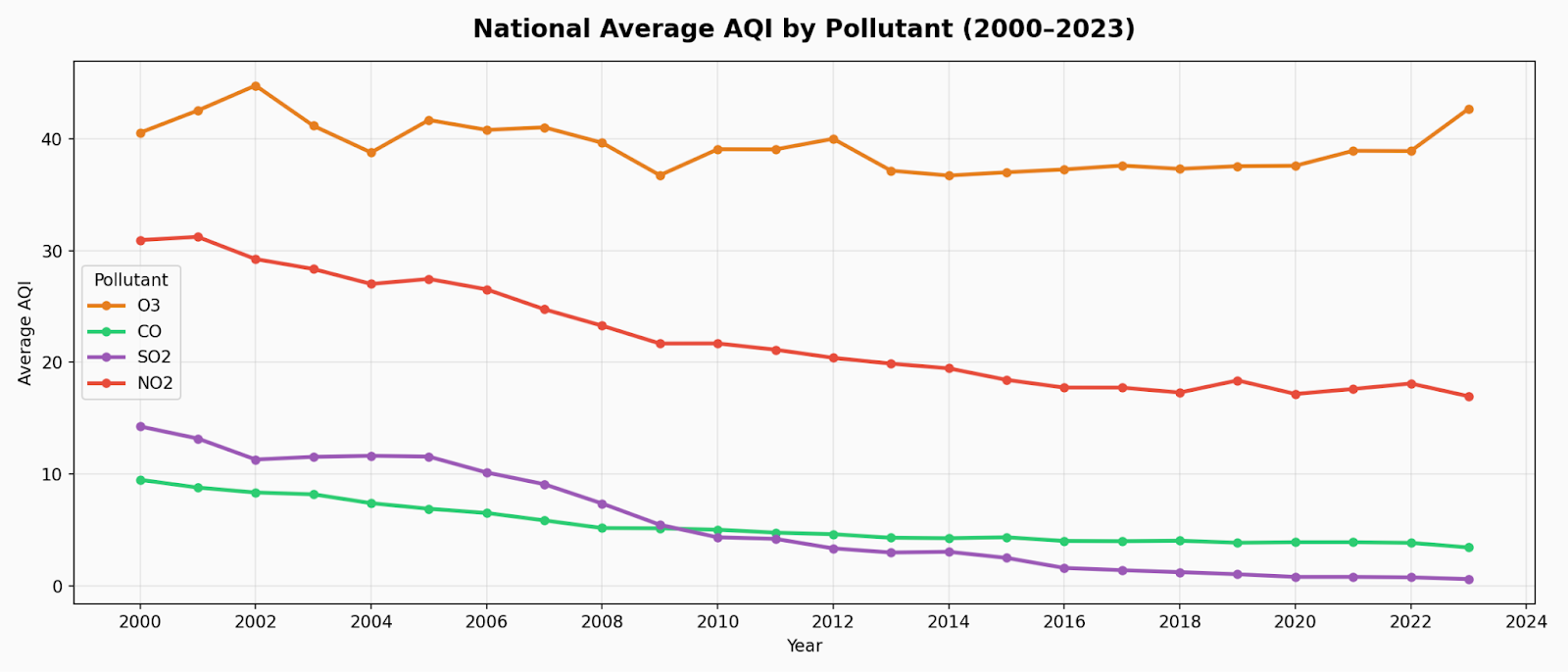
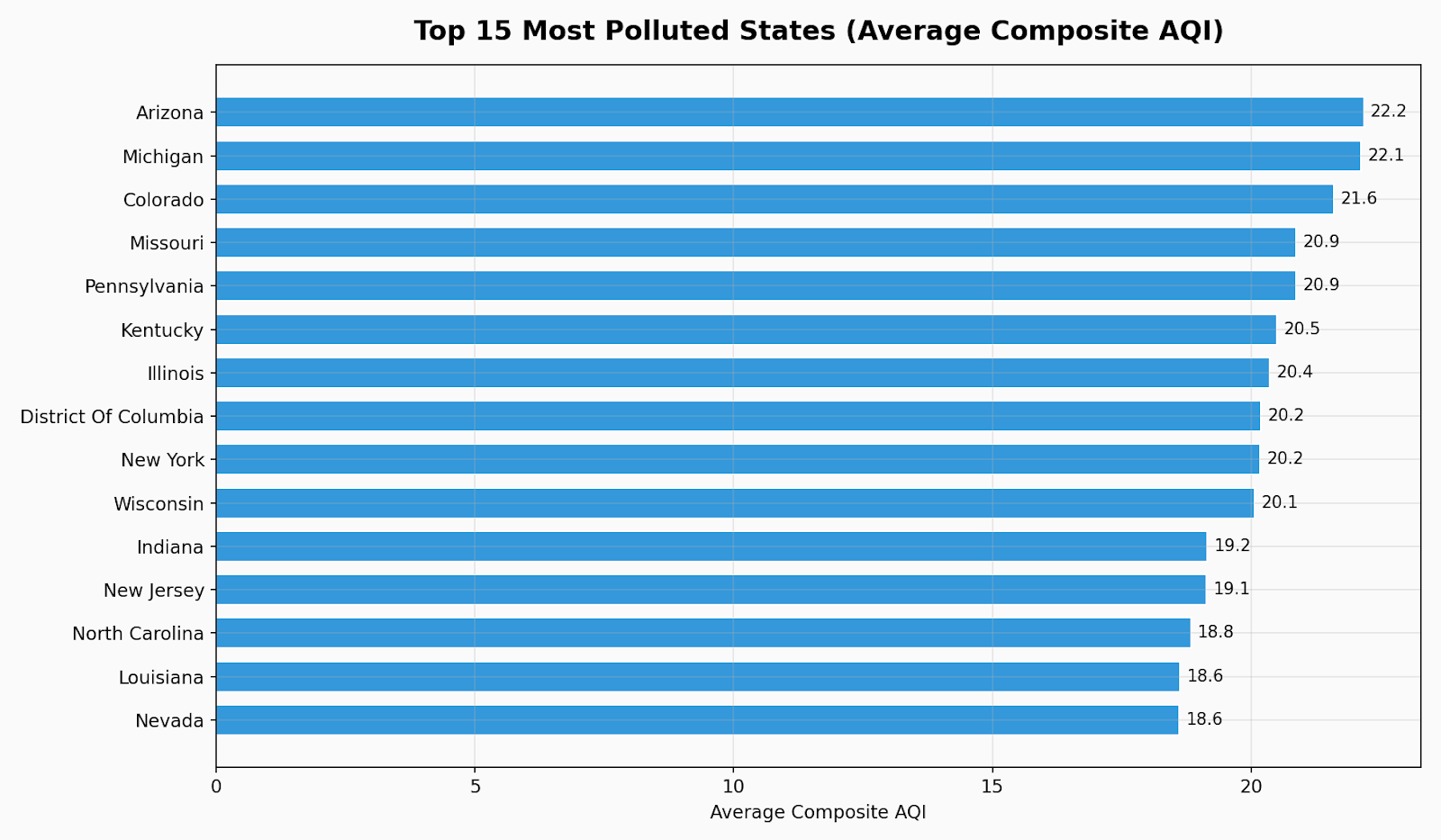
The second discovery was how well the simple model performed on its own. The well-tuned traditional model was a serious contender for short-range predictions, where recent history actually means something. That's a good practical thing to think about for a moment. The most sophisticated model isn't always the best model to use. The ability to recognize that, rather than trying to use a more complex model, is one of the most common mistakes with significant cost, and the choice of which is better is as important as how you use it.
The Lessons
A few things became clear that I think transfer directly to how organizations should be thinking about AI forecasting, particularly in data-intensive industries such as financial services.
Your data is the foundation. Before any serious AI initiative, the only question worth answering isn't which model to utilize, but rather if your data infrastructure is able to support any sort of model at all. The best model in the world isn't going to help you if your data history is incomplete, your data is inconsistent, or your data is siloed across different systems that don't speak to each other. This is particularly the case in fintech, and it is almost always discovered too late.
Aggregate accuracy metrics can lie. A model might be 95% accurate, but completely wrong in all ways that actually matter for your business. The ways in which you cut and analyze this sort of performance are at least as important as the actual numbers. The only question worth answering is where this particular model is actually working, and where it is not.
The transition from prototype to production is harder than it seems. You might be able to get your model working well in an experiment, but it's much tougher to get it working well over time, in the real world, with proper monitoring and auditability. The model is rarely the reason AI projects fail. The infrastructure around it usually is.
The Broader Point
Air quality and financial services are obviously different domains. But the underlying problem is the same: how to make good predictions on something that actually matters, using historical data as input. The patterns I encountered here show up in fraud detection, credit modeling, demand forecasting, and risk management. Most organizations aren't getting nearly as much from these models as they could be, and that gap is fixable. But not by choosing the right model. It gets fixed by getting the data right, being realistic instead of optimistic in evaluation, and engineering the model into something that an organization can actually depend on.
What getting the data right looks like varies by organization, but a few things come up consistently. You need a single source of truth. Fragmented data spread across systems that don't talk to each other is the most common reason AI initiatives stall before they deliver anything useful. You need a clean historical record, because gaps and inconsistencies in the past translate directly into unreliable predictions about the future. And you need the right infrastructure to bring it all together - tools like Snowflake have become the standard for organizations serious about this, and it's far more tractable than it used to be.
That combination is harder to find than the models themselves. But it's where the real value is.
Working on a prediction problem that feels like it should be solvable but isn't yet? That's exactly the kind of challenge we like at Ippon Technologies. As a Snowflake Premier Partner, we have a dedicated concierge program that puts certified Snowflake engineers in your corner helping you get your data foundation right, optimize costs, and actually start doing interesting things with AI.
You can learn more about our Snowflake work here: https://ipponusa.com/partners/snowflake/ and explore our broader AI and data capabilities here: https://ipponusa.com/service/artificial-intelligence/ and https://ipponusa.com/service/data-analytics/.
If you'd prefer to talk it through, feel free to reach out at sales@ipponusa.com

Comments