
There are core basics that every organization needs that leads to a basic standard implementation of a Big Data solution. However, that basic implementation will not provide the best performance for the user in all use cases and situations. There are so many different options now that choosing between all of them can be complicated. There is Apache Cassandra, HBase, Accumulo, MongoDB or the typical relational databases such as MySQL. Knowing when to use which technology can be tricky. The basic implementation that I have seen is the Lambda Architecture with a batch layer, speed layer and view layer. Hadoop is primarily used as the storage in the batch layer and Cassandra for the view layer. In many cases this architecture will provide the user with the best performance but some analysis should always be done on the overall use case and business needs to determine what Big Data database is best or if a relational database will be best.
Cap Theorem
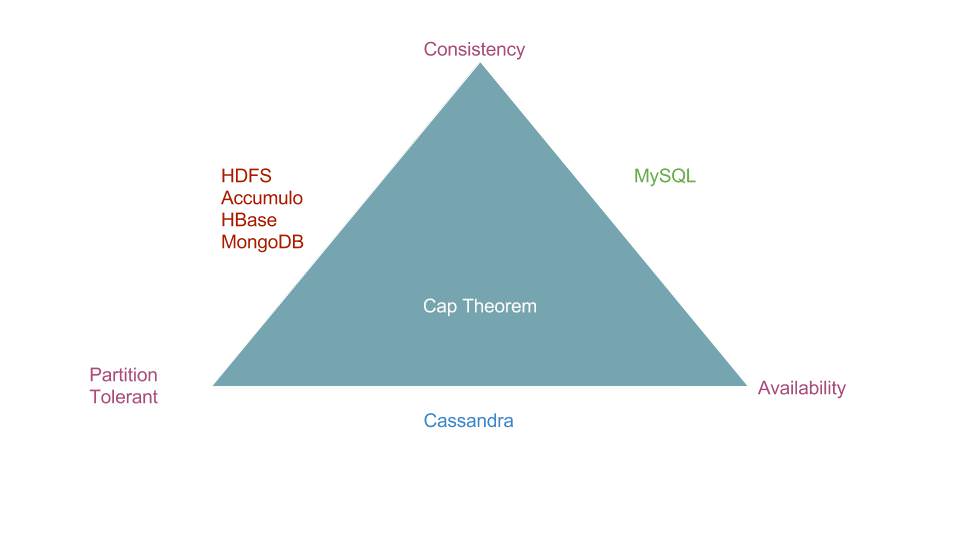
When examining Big Data solutions that will work for your organization one of the most important theorem to use is the CAP theorem. The CAP theorem explains that there needs to be trade offs between consistency, availability and partition tolerance in a system. Normally it is said that only two can be achieved. However, in truth levels of all three can in fact be achieved but high levels of all three is impossible. When a query is executed against all the nodes of a system simultaneously and the same data will be returned, the system is considered consistent. Availability is achieved when a request to write to the system will always succeed. The final trade off is for partition tolerance, where the system will be able to operate as normal in case of a network failure. A partition tolerant system is one that scales horizontally by adding more nodes to the system, versus scaling vertically by adding more hardware to the system such as increased memory or storage. This system will be able to recover if there are more partitions added and data is further split between nodes.
If consistency and availability are the two most important aspects to your application for a database, a typical relational database such as MySQL would be best. This choice is good when a low amount of complex queries are necessary. Relational databases can be slow to respond when running complex queries due to the hardware cost of running. For example queries that aren’t written properly can be slow if joins are performed over a non filtered dataset because the dataset is too large. Lookup tables are an excellent use case for a relational database because typically lookups are simple queries where extra information is needed based on one or two specific values. An example of this can be looking up the address for an individual based on their unique identifier for the system.
All databases that are Big Data solutions are partition tolerant and therefore must balance between being consistent and available. Choosing between availability and consistency is not necessarily a one to one choice. Most solutions have high availability and low consistency or vice versa. Therefore, the main choice is what do you need more, a system that has high availability and eventual consistency or a very consistent application that is mostly available.
One example of a highly available and eventually consistent application is Apache Cassandra. Apache Cassandra is a column oriented structured database. You can choose the consistency level for the Cassandra nodes. The less nodes need to be consistent on a write the more available the system is. When you choose to write and read to only one node for a success which provides the highest level of availability, there is a concept in Cassandra of a read repair. When a read happens in Cassandra there is a background process that determines if the replication has the most current data. If the data is incorrect this process will correct the replication so it has the correct data which will allow the nodes to become consistent with the others. For users this means that if each node is queried after an update different data may be returned as not all the nodes were updated. If one of these nodes goes down, outdated data could be returned to the application. However, there will always be a response from the application which makes Cassandra highly available. A good example of a use case for this would be a historical summary view of data where the data is not likely to change often. Many times a Cassandra database will also be consistent but there are also times where Cassandra won’t be.
There are many databases that are considered to be highly consistent but not highly available. HDFS is an example of storage that is highly consistent but not highly available. If a server with the NameNode was to experience network failure then all jobs that are currently in progress or the ability to access the data for a MapReduce job will fail. This causes HDFS to have a lower availability than other databases such as Cassandra. Having multiple NameNodes can mitigate this risk and have higher availability. If HDFS is queried when there is a network issue to the NameNode, no response will be given to the user. There will only be a timeout.
Other examples of highly consistent but not highly available databases are Apache Accumulo and Apache HBase. Apache Accumulo and HBase are solutions that are based on Google’s BigTable. These types of implementation are built on top of HDFS and use HDFS to store the data. Therefore, these databases are constricted by the availability of HDFS.
A final database solution that is highly consistent but not highly available that is used a lot is MongoDB. MongoDB operates in a primary, secondary architecture. When the primary nodes goes down, the system will choose another secondary to operate as the primary. The primary is the first to receive any writes to the system so to maintain consistency when the primary node fails any writes to the system will not be accepted causing the system to appear unavailable. This protects the system against a secondary having data that the primary node does not have once the primary comes back on. Primary generally restores from outages in a few seconds.
However, the CAP Theorem is just one aspect to determining what database is best for your application. If the database design involves a high amount of relations between objects, a relational database like MySQL may still be applicable. Also lookup information can still be valuable in MySQL or a similar database where the queries can be written with less joining on the large tables. If filtering can not be done prior to the joins, that increases the cost of the query. Also if the data that needs to be stored is minimal, SQL is still the standard that many developers and database individuals know. While NoSQL and Big Data technologies are being learned by many people, in some ways it is still a specialized skill. If your application does not have large amounts of data then the processing advantages of a Big Data solution are not being used. This makes it less important to implement this type of solution.
Why HDFS?
Assuming that the data that will be entering into the system is at a large enough amount to warrant a Big Data solution, the other Partition Tolerant systems should be examined. HDFS can be schema-less when used on its own as a database which is helpful to store multiple different types of files that have different structures. There are also ways to store data in a particular schema format such as using Apache Avro. HDFS is an important storage aspect in the Lambda architecture where all data elements are stored so as to not lose data. If a solution requires reprocessing of historical data, and a requirement to store all messages in a raw format, HDFS should be part of the solution. For more information on Hadoop and HDFS check out the documentation.
Why HBase or Accumulo?
HBase and Accumulo are column oriented databases that are schema-less. Databases such as HBase and Accumulo are best at performing multiple row queries and row scans. HBase and Accumulo allow the database to be queried by ranges and not just matching columns values. If the business case involves querying information based on ranges, these databases may fit the needs. One such business case could be finding all items that fall within a particular price range. Accumulo and HBase, unlike Cassandra, are built on top of HDFS which allows it to integrate with a cluster that already has a Hadoop cluster.
One of the advantages Accumulo has over other databases is its use of cell level security. Most of the other databases have only column level security so a user can either see a value for a key or not. Having the security down to the cell level will allow a user to see different values as appropriate based on the row. For more information on HBase go to the documentation here and for Accumulo the documentation here.
Why Cassandra?
Cassandra is a column oriented database that is incredibly powerful when the database is designed in a way that allows the queries to be executed. One of the drawbacks is that the way the data will be queried is important to know when designing the database because an improperly designed database will not have the high performance. This is why Cassandra can be implemented in the view layer of the Lambda architecture, since query to the view is known in advance and the Cassandra column family can be structured in the optimal way. However, Cassandra is the fastest database in relation to writes to the database because of the high level of attention that is spent with respect to how the data is stored on disk when the database has been properly designed. Cassandra is therefore the correct choice for a database where a high volume of writes will take place. One common example is to use Cassandra for logs. Logs have a high volume of writes so having better performance for writes is ideal. The documentation for Cassandra is located here.
Why MongoDB?
The last option we’ll be covering for your database is MongoDB. MongoDB is different from the other databases discussed because it is document-oriented versus column-oriented. When the data fields to be stored may vary between the different elements, a relational or column oriented storage may not be best as there would be a lot of empty columns. This is not necessarily bad to have many empty columns but MongoDB provides a way to just store the only fields that are necessary for the document. For example, this would be a good option for interview data where, depending on what you ask, fields may become required or other questions may be asked based on that answer. That way there doesn’t need to be a field for each question in the interview but instead one document that represents the entire interview and one can add fields when new questions are asked. For more information look at the MongoDB documentation.
Conclusion
There are many different reasons to choose a different database and this is just a summary of the most important aspects that I use to examine the needs of my client before making any recommendations on a Big Data solution. Using the Cap Theorem is one way to, based on the availability needs or consistency needs of the client, decide if a Big Data solution or if a relational database is needed. Other choices to make are between a relational database like MySQL, column oriented databases like HBase, Accumulo or Cassandra, or document oriented like MongoDB. If security is a concern something like Accumulo with its cell level security may be the best option. Lastly, the amount of writes, and the type of queries should be considered to determine if range-based queries are needed or if fast writes are needed. Answering these questions can help navigate the many different options that are out there to come up with a solution that is right for your specific needs.



Comments