
Vector Databases Quietly Powering GenAI

 AI's Hidden Plumbing: Why Vector Databases Are Quietly Powering the AI Boom
AI's Hidden Plumbing: Why Vector Databases Are Quietly Powering the AI Boom
When most people think about generative AI, they think about a question-answering chatbot or a recommendation engine showcasing the perfect product. They don't imagine the out-of-sight pipes that make these systems work at scale. At the heart of those pipes is a crucial but underrated piece of plumbing: the vector database.
Lessons From My First Recommendation Engine
I first came across this reality when I was developing a retail recommendation engine with a few friends of mine. We worked with the Online Retail dataset (281,000+ transactions) and implemented a system based on association rule mining algorithms like Apriori, FP-Growth, and Eclat. The goal was simple: improve cross-sell (products usually bought together) and upsell (expensive variations of products in the same category)
And it worked. Our models discovered fascinating patterns:
- Customers would buy teacups in a pack of two (cross-sell).
- Customers upgraded from an ordinary snack box to an upgraded pack (upsell).
We stored data in AWS RDS, connected it to Tableau dashboards, and created intuitive recommendations that yielded more revenue. It was proof that intelligent recommendations could drive more revenue.
But what was fascinating was that association rule mining worked well on that dataset, though it doesn’t scale to the personalization needs of today. When you must compare millions of products, customers, and scenarios in real time and not just find co-occurring items but semantically related ones, old-school methods don't hold up. That's where vector databases enter the stage.
Why Traditional Databases Weren't Enough
Embeddings are the "vocabulary" of modern AI. Unlike a traditional database, where product IDs, names, or categories are stored in raw text or numbers, embeddings map data to high-dimensional vectors that encode relationships. For example, while "dress" and "skirt" are different strings in a table, their embeddings are close to one another in vector space because humans use and buy them in similar contexts. That is the strength of embeddings: they don't just store labels but store meaning.
Now scale that. You have 100,000 products, each represented by a 768-dimensional vector, and a million customers, each represented by a preference embedding. To search for "nearest neighbors" in this space means comparing billions of numbers. SQL or NoSQL databases perform well with exact lookups (e.g., "return customer ID 123"), but they are not made to return the most similar vectors in high-dimensional space.
This is exactly where most companies hit a roadblock: they have no issue generating embeddings with something like OpenAI or Hugging Face, but when they try to store and query them in Postgres or Elasticsearch, performance comes crashing down at scale. That's why vector databases were invented—to make semantic similarity search fast and viable in production environments.
Vector Databases: The Missing Layer
Vector databases such as Milvus, Pinecone, Weaviate, or Redis Vector address this. They are experts in approximate nearest-neighbor (ANN) search, i.e., they can retrieve the most useful embeddings in milliseconds even at a huge scale.
It is like the distinction between looking for a needle in a haystack one straw at a time (brute force) versus having a magnet that will pull out the needle immediately.
I experienced it myself in subsequent projects:
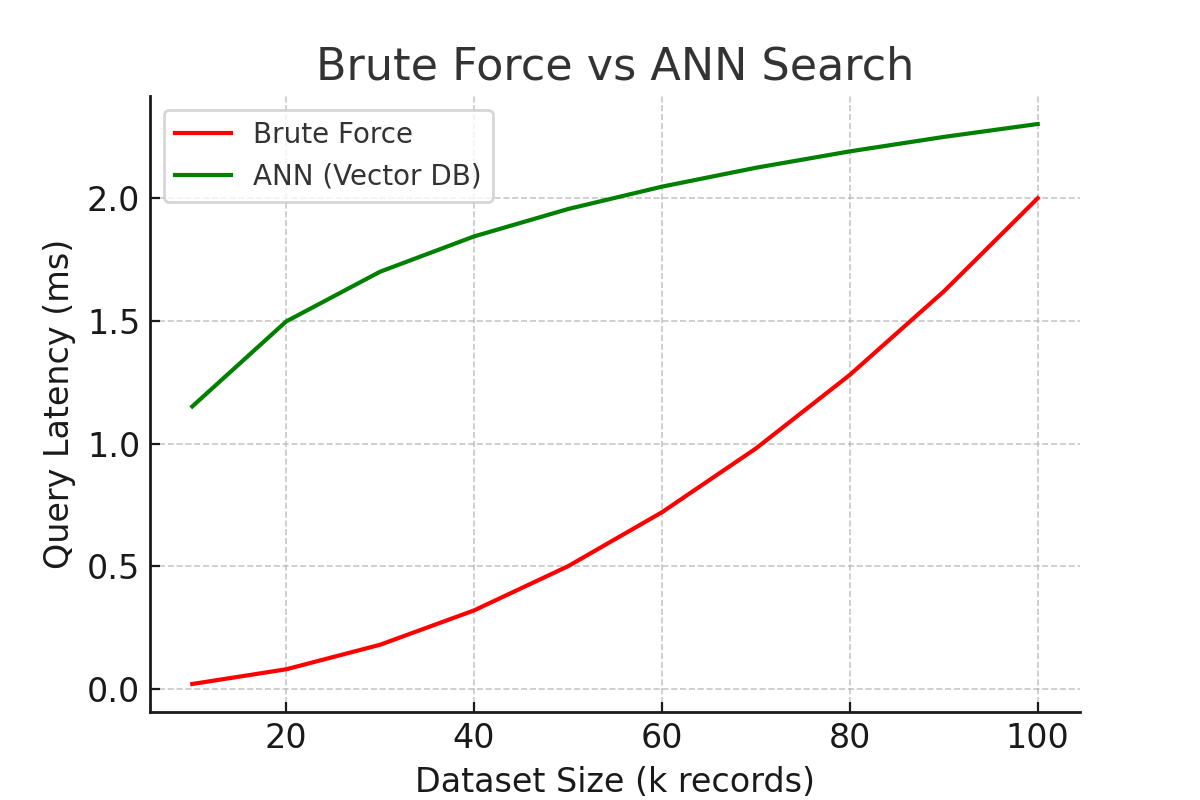
- Building demos with Milvus showed how query latency dropped dramatically compared to brute force.
- Blending Neo4j graphs with embeddings (LastFM dataset) shed light on how hybrid search—graph relationships + semantic similarity—produced more interesting, worthwhile recommendations.
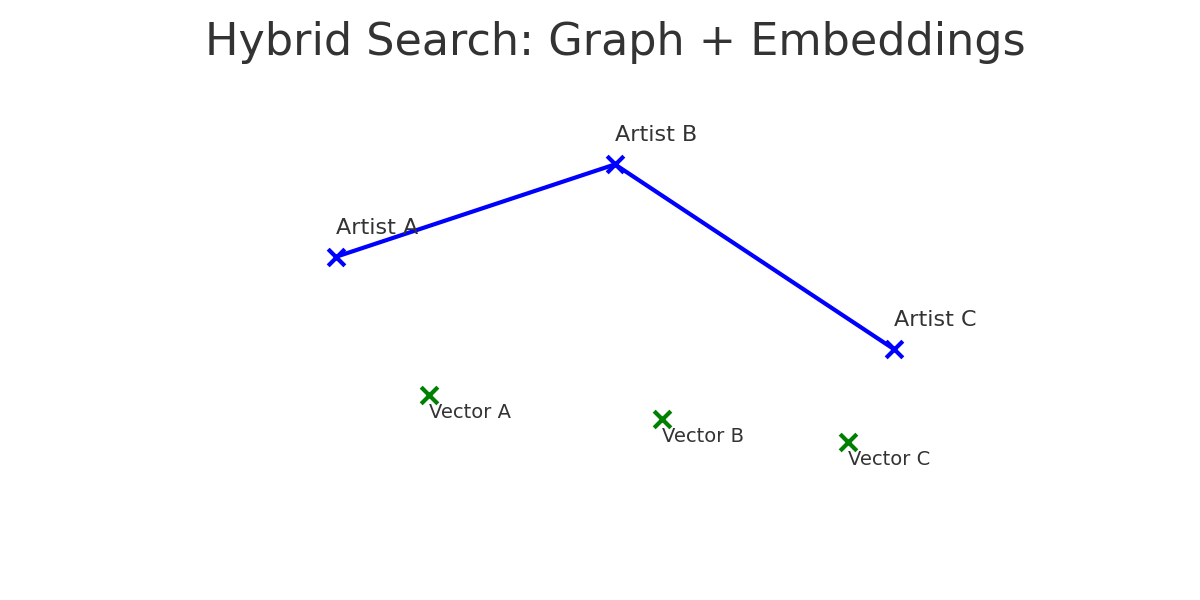 Together, these projects illustrated the same principle: with vector databases, embedding-based systems reached their limit far too quickly. In Milvus, the contrast between brute force and ANN search was stunning—queries taking seconds were being run in milliseconds, and real-time performance became a reality. In Neo4j and LastFM, adding embeddings to graph relationships illustrated how hybrid search can transcend connection to uncover truly significant recommendations.
Together, these projects illustrated the same principle: with vector databases, embedding-based systems reached their limit far too quickly. In Milvus, the contrast between brute force and ANN search was stunning—queries taking seconds were being run in milliseconds, and real-time performance became a reality. In Neo4j and LastFM, adding embeddings to graph relationships illustrated how hybrid search can transcend connection to uncover truly significant recommendations.
The moral of the story was not ambiguous: vector databases are no optimization layer. They are the tech enabler that makes an AI system a production-ready one from a prototype level.
Why This Matters for Enterprises
For businesses, vector databases are not a "nice to have." They're quickly becoming the foundation of applied AI.
- Knowledge Retrieval (RAG): Consider an international law firm that employs a chatbot to aid lawyers with research. Without vector databases, the system cannot search through millions of contracts, case files, and compliance documents in real time. With embeddings stored in a vector database, the bot can extract the right passages within milliseconds, reducing hallucinations and keeping answers rooted in company knowledge.
- Personalization: Personalization in e-commerce can't be based solely on the history of co-purchases. A mountain climber looking for hiking boots might also need a waterproof jacket, even if that pair isn't in the transaction history. Vector databases enable recommendation engines to bring to the surface items that are semantically similar, so recommendations don't feel forced.
- Fraud Detection: Fraud rarely follows hardened rules. Through injection of transaction patterns, banks can use vector search to tag anomalies that show up suspiciously in high-dimensional space, even if the strategy has never been seen before. This enables proactive, real-time fraud prevention.
- Multimodal Search: Companies now manage different types of data—text, images, voice, and video. Cross-modal retrieval is possible with vector databases. A media company can enable search by a user uploading a photo, and a medical company can enable doctors to search patient files by voice. In both cases, embeddings of different modalities are stored in a vector database to enable fast and accurate search.
Just as relational databases became synonymous with enterprise software in the last generation, vector databases are becoming synonymous with enterprise AI in this generation.
Looking Ahead
Scaling personalization quickly exposes the limits of rule-based techniques like Apriori or FP-Growth. That's where embeddings and vector databases fill the gap. Businesses that would like their AI systems to transcend trivial demos and deliver real value will need to spend money on this invisible layer of plumbing. Just as SQL emerged as a necessary backbone for business software in the last generation, vector databases are becoming the backbone for AI.
The next time you see a smooth AI demo, remember: it’s not the model’s work alone. Behind the scenes, a vector database is working quietly to make it possible. If you’re interested in learning how your company could benefit from vector databases and other AI-driven solutions, reach out to Ippon Technologies to explore how we can help.
Github Repo: https://github.com/swati-0308/retail_recommendation_system




Comments