


Published August 31, 2020
This post is part of a series of posts on Data Quality Management. The focus of this series is on strategies for acquiring data to be used to ensure the quality of data. Briefly, the five aspects of Data Quality Management are
- Accuracy
- Consistency
- Completeness
- Integrity
- Timeliness
For more information on these concepts, check out this article written by my colleague Pooja Krishnan. There she describes in detail these five components of Data Quality Management and why those components are important to maintaining high quality ETL pipelines and data processes.
In this article, we will introduce the ABC Framework of Data Quality Management. We will focus on A as in Audit, and how the Audit process applied to ETL pipelines lays the groundwork for ensuring high-quality data across your business.
ABC Framework of DQM
The ABC Framework for Data Quality Management (DQM) combines three processes that, when implemented, should ensure your data warehouse is accurate, consistent, complete, integrous, and timely. These processes are typically applied to ETL operations on a data warehouse. ABC stands for
- Audit
- Balance
- Control
Audit is the process of identifying what happened during an ETL operation. Balance is the process of confirming if what happened was correct or not. Control is the process of identifying and resolving errors that may have happened during the ETL process. The Audit process helps to inform the Balance process, which in turn helps to inform the Control process. The Data Warehouse Institute published a great paper on this topic in 2008. The following graphic is from this paper and it shows how your Audit, Balance, and Control processes work together to ensure high-quality data.
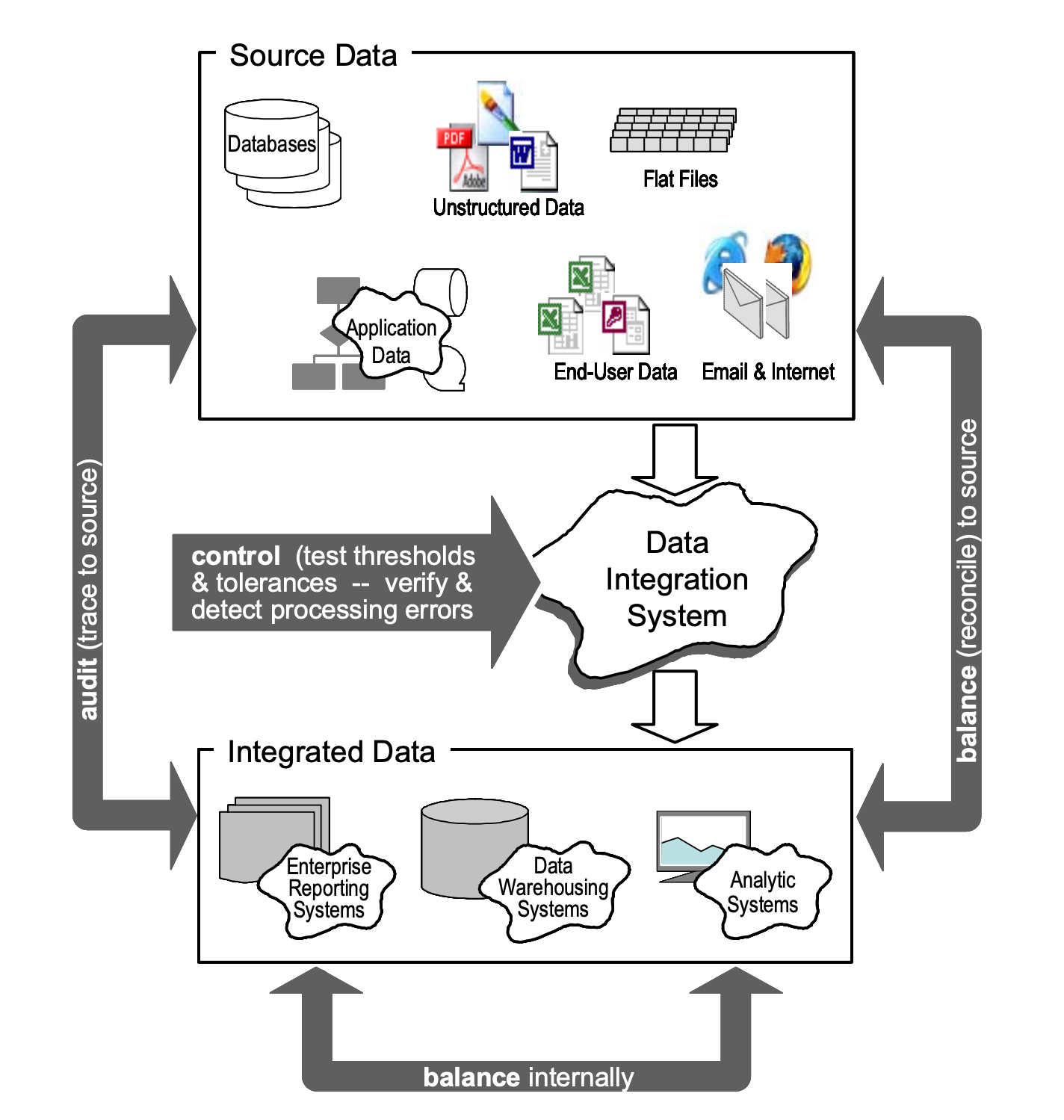
The ABC Framework wraps around the Data Integration System (2008 called, they want their term for ETL/ELT back). In this post we'll be addressing Audit, or Tracing to Source. We'll address Balance and Control in future posts. For some additional reading on the ABC framework, check out this white paper on the subject published in 2016, which outlines an MVP data model for a bare-bones implementation of this framework.
Audit & Why SDLC Doesn't Cut It
A common misconception about the Audit process is that it confirms your ETL pipelines run as well-crafted pieces of software. (By well-crafted I mean thoroughly tested, self-documenting, bug-resistant, concise, and maintainable.). This is not the case. ETL pipelines should be held to the same standards of testing and development that any other piece of software is held to, don't rely on Audit to assure proper ETL execution after releasing to production. Audit, and the wider ABC framework is about the data you work with, not about the application that touched the data. It's about how the ETL job moved the data, not how the ETL job executed.
That being said, your Audit process can certainly capture meta-data about your ETL jobs. You can capture data like execution time, input parameters, log location, etc. Just be sure that when you capture data for your Audit process pertaining to your ETL job, you capture that data with the intent to inform downstream processes about your data quality. For example, capturing execution time may be helpful in the scenario where your ETL job relies on asynchronous API calls to third party services. A high execution time suggests your ETL pipeline is being held-up, and there may be a way to improve its execution speed (recall Timeliness is a factor of DQM). Additionally, if you capture log location in your Audit process, you could conduct forensic analysis on your ETL job at a later date. This could come in handy for the Balance and Control processes in particular.
What Are We Auditing?
This is a sample data model for a record created by an Audit process using a data modeling tool called SQLDBM:
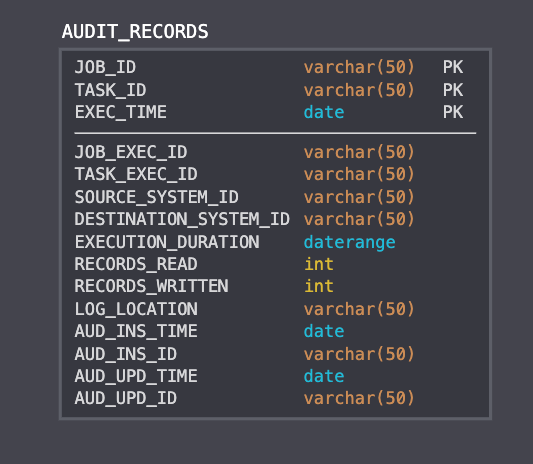
Looking at this data model, it seems quite comprehensive. We have a composite key made from the ETL Job ID, Task ID, and execution time. This suggests we're storing time-series data as well as component/task records for each job. In the other parts of the table, we're storing lineage data by identifying source and destination IDs. We also store the count of logs written, some audit fields to keep track of changes to this record specifically, and a field for log data in case we want to scrape that at a later date. This seems pretty comprehensive, we can confidently move forward in our DQM endeavors, knowing we are tracking lineage data for our ETL pipeline. We know how each job ran, we know where those job's records came from and were stored to, and we can troubleshoot individual runs at a later date if need be.
But what about the case where we're pulling from several upstream sources? Or dropping into several downstream sources? What happens if you don't distinguish between a job and a task? These are all valid questions, and there are several answers to them. The data model above is not definitive, every business will have a unique DQM process informed by their unique ETL needs. So how do you generalize your Audit process? In terms of data models, you really can't. However, you can make sure that every piece of data collected by your Audit process informs your larger DQM ecosystem. Make sure you can tie every piece of data collected by your Audit process to a question that you want answered by DQM. The questions can be domain-specific:
- Which Widgets were selected for additional QA Control & Testing? Are we testing enough Widgets to reduce returns and bad customer reviews?
- Which Widgets were produced by our production lines with defects? Do we need to replace production line equipment or invest in higher quality raw materials?
- How many shipments of Widgets were shipped to a certain geographical region? Can we justify opening a new distribution center in this area?
Or these questions could be focused on your data processes as a whole:
- What ETL job ran? What tasks were associated with that job? Did they all run successfully? Were there errors that did not halt execution?
- What were the input parameters for the process? Are these parameter general or specific to the process itself? Do these parameters change based on time of day or affected systems of record?
- How many records were extracted? From where were they extracted? How many records were transformed? What transformations were conducted? How many records were loaded? Where were those records loaded?
- When did it all start? What/Who started this process? When did it all end?
- What was started as a result of this pipeline finishing? Did this particular job's execution improve or hurt your environment's overall data quality rating?
As you can see, there's no one-size fits all Audit process. Just as a tax audits will differ across organizations or people, DQM Audits will change as to reflect the organization's use of data. If your organization suffers from data quality issues, you need to start with auditing your ETL pipelines for the proper pieces of information. Don't be afraid to spend some time coming up with domain-specific and data-specific questions like the ones outlined above before finalizing your DQM system.
Tightly Coupled Architecture
Keen readers may notice an architectural issue associated with DQM and the stateful nature of their task. Let's break this issue down.
You have a data warehouse that is populated with streaming data ingest, batch data loads, or both. The pipelines that facilitate the population of your data warehouse are stateful. Every run takes the same sequence of steps, and the parameters that initialize each ETL job are more or less the same, what changes is the data itself. You may have hundreds of thousands of records manipulated, or just one. Enter DQM, now you have a framework that provides an audit trail of your ETL pipeline's performance, with built-in, self-correcting, mini-ETL pipelines (see the articles on Balance and Control) that ensure data quality is maintained. The problem here is that DQM relies on ETL to work. The upstream to DQM is ETL and if something goes wrong with your ETL process, your DQM process will suffer from the same issue, thus affecting your overall data quality.
One approach to resolving this could be to tightly couple your ETL process with built-in DQM processes. After all, what's the harm in collecting meta-data about your extract and loading processes and then executing some code that represents your audit? The issue here is that you still have two different processes running in a tightly coupled fashion. At the end of the day, ETL and DQM are different processes and should be treated as such. So how do you decouple these two distinct processes, while maintaining the upstream-downstream relationship that allows DQM to be effective? One approach is to use events.
Events and the Decoupled Approach
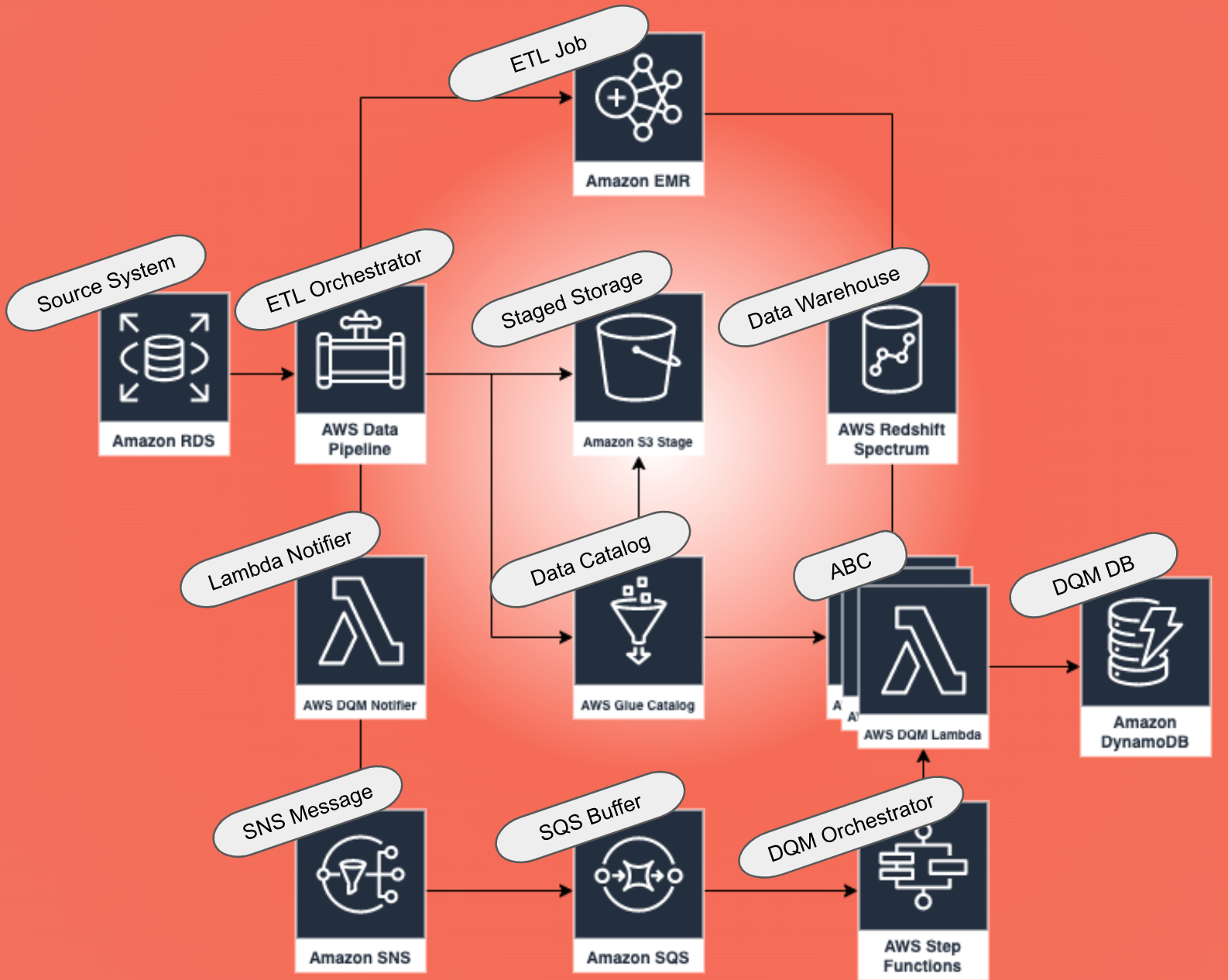
The above image shows a sample architecture that decouples ETL pipelines and DQM pipelines using events with AWS services. Events allow us to send information asynchronously from one application stack to another. In the above image, we describe an ETL pipeline constructed using AWS Data Pipeline and EMR. This pipeline connects an RDS data base to an S3 data lake, fully equipped with Redshift Spectrum for data warehousing queries, and a Glue Data Catalog. Where does DQM fit into this ETL pipeline? That's where the lambda function comes in. The lambda publishes a custom event to SNS/SQS. This event triggers an execution of AWS Step Functions which contains the logic for your DQM pipeline. One of the functions in that step function stack would contain the logic needed to trigger an audit job.
What is the benefit to using events in this fashion? The first benefit comes from the nature of event-driven architectures. Events decouple disparate application components. They allow for asynchronous processing of multiple related, but independent components. Second, this architecture implies that everything your audit process needs to start is contained within the body of the event. The inputs to your audit process could be explicitly defined as key-value pairs in your JSON body. This is an obvious approach, but explicitly defining your job's inputs in an event may not scale to additional audit jobs down the line. If you have a particularly complicated audit job, you could implicitly pass an S3 file location or pre-defined SQL queries to a DynamoDB parameters table containing pre-defined parameters for your specific job.
Additional benefits to adopting this kind of architecture become dependent on the message bus you adopt. For example, if you use Kafka as an event-bus, you can craft your messages in such a way that streaming analytics can be used to describe your systems overall data quality. For example, you could run KSQL commands over the event log to see the messages flowing over the bus pertaining to all of the DQM jobs that have run in the last 12 hours. If you use RabbitMQ or SQS, you can queue your DQM messages over the course of a day or a week and run batch data quality jobs on a schedule. If you use EventBridge, you can use pattern matching to route messages to specific AWS services based on the contents of the message itself. By selecting your message bus appropriately, you allow for additional benefits, or pitfalls, to event-driven DQM that you may not have anticipated. Choose your message bus wisely!




Comments