


The previous article Serverless architectures contained a definition and the promise that Serverless architectures could offer. In this article we will see concretely what technologies are available today to develop the serverless architecture of tomorrow.
FaaS, What else !
Previously we have seen what FaaS is all about. But let's dig a little deeper into this. I was inspired by Mike Roberts' blog article, which seems very clear to me and which correctly treats each of the layers of FaaS. But first let's go back to the official AWS definition of the AWS Lambda product and then let's look at each concept one by one.
AWS Lambda lets you run code without provisioning or managing servers (1). You pay only for the compute time you consume - there is no charge when your code is not running. With Lambda, you can run code for virtually any type of application or backend service (2) - all with zero administration. Just upload your code and Lambda takes care of everything required to run (3) and scale (4) your code with high availability. You can set up your code to automatically trigger from other AWS services (5) or call it directly from any web or mobile app (6).
-
Fundamentally, FaaS refers to the execution of back-end code without managing server systems or application servers. This second "application server" clause is the key difference when comparing this technology with other modern architectural trends such as PaaS or containers.
-
The FaaS offering does not require coding through a specific framework or library. The only environmental dependency that one can have is related to the possibilities offered by the service according to the provider. For example, today the AWS Lambda functions can be implemented in JavaScript, Python or any other language running on the JVM (Java, Clojure, Scala,...) whereas Google Cloud Platform offers only JavaScript (mainly due to the very high performance of its JavaScript engine). However, this execution environment is not resolved because of our ability to execute other processes. As a result, it is possible to use all the languages provided as long as they can be compiled by a Unix process (e.g. Golang). We can, however, find architectural restrictions mainly when we talk about state or runtime, but we will come back to these points later.
-
Since we don't have application servers to host the code, the execution is very different from traditional systems. The update process begins with uploading the code to the service provider and then calling a provider API to notify the provider of the update.
-
Horizontal scaling (increasing the number of instances) is fully automatic, elastic and managed by the service provider. If your system needs to respond to twice the number of requests it was previously handling, the service provider will add instances to do so without any intervention or configuration from your side.
-
FaaS is an event-driven service. This means that the functions are triggered by events. We may have different types of events such as those from the provider's services. Among these we have events when updating a file on a bucket, scheduled events (cron) or even receiving messages via a publisher / subscriber system. Your function might then have to provide an answer for the event’s emitter depending on your use case.
You will also be able to trigger functions in response to incoming HTTP requests, usually through an API gateway (API Gateway, WebTask, Cloud endpoints).
Lifecycle
FaaS functions have significant restrictions on their lifecycles. The main one is their "Stateless" nature; no persistent state will be available on another invocation, this includes the data in memory or that you could have written locally on the disk. This can have a huge impact on your application architecture, but it does align with The twelve-factor App.
Execution time
FaaS functions are limited in execution time. For example, AWS Lambdas are not allowed to run for more than 5 minutes and if they do, they will automatically be killed regardless of what you are currently doing.
This emphasizes that FaaS functions are not suitable for all use cases or at least will have to be adapted to overcome these constraints. For example, in a traditional application you may have a single service that performs a long task, whereas in FaaS you will probably have to separate it into different functions that are independent of each other but may be sequenced.
Cold start
The response time of your FaaS function to a request depends on a large number of factors and can range from 10ms to more. Let's be a little more precise, using an AWS Lambda as an example.
You can split your execution process into 2 phases :
- Cold start: time spent by the provider to initialize your function.
- Execution time: time spent executing your core function (Handler).
Basically, the execution time should remain stable for core execution. However, initialization may vary depending on your configuration. For your information, the initialization time is not billed if it does not exceed 10s.
If your function is implemented in JavaScript or Python, which are interpreted languages with simple content (less than a thousand lines of code), the cold start should be between 10 to 100ms. More complex functions may occasionally see this time increase.
If your Lambda function is executed in a JVM (Java, Scala, Kotlin,...), you can have a dramatically longer startup time (> 10 seconds) just to load the JVM. However, this only occurs in one of the following scenarios:
- Your function rarely handles events (more than 10 minutes between invocations)
- You have very sudden peaks in traffic, for example: you process 10 queries per second, but this speeds up to 100 queries per second in less than 10 seconds.
It is possible to avoid the first situation by keeping your function “alive” using some sort of a ping every N seconds or so.
Below is a graph of the different boot times according to the language used
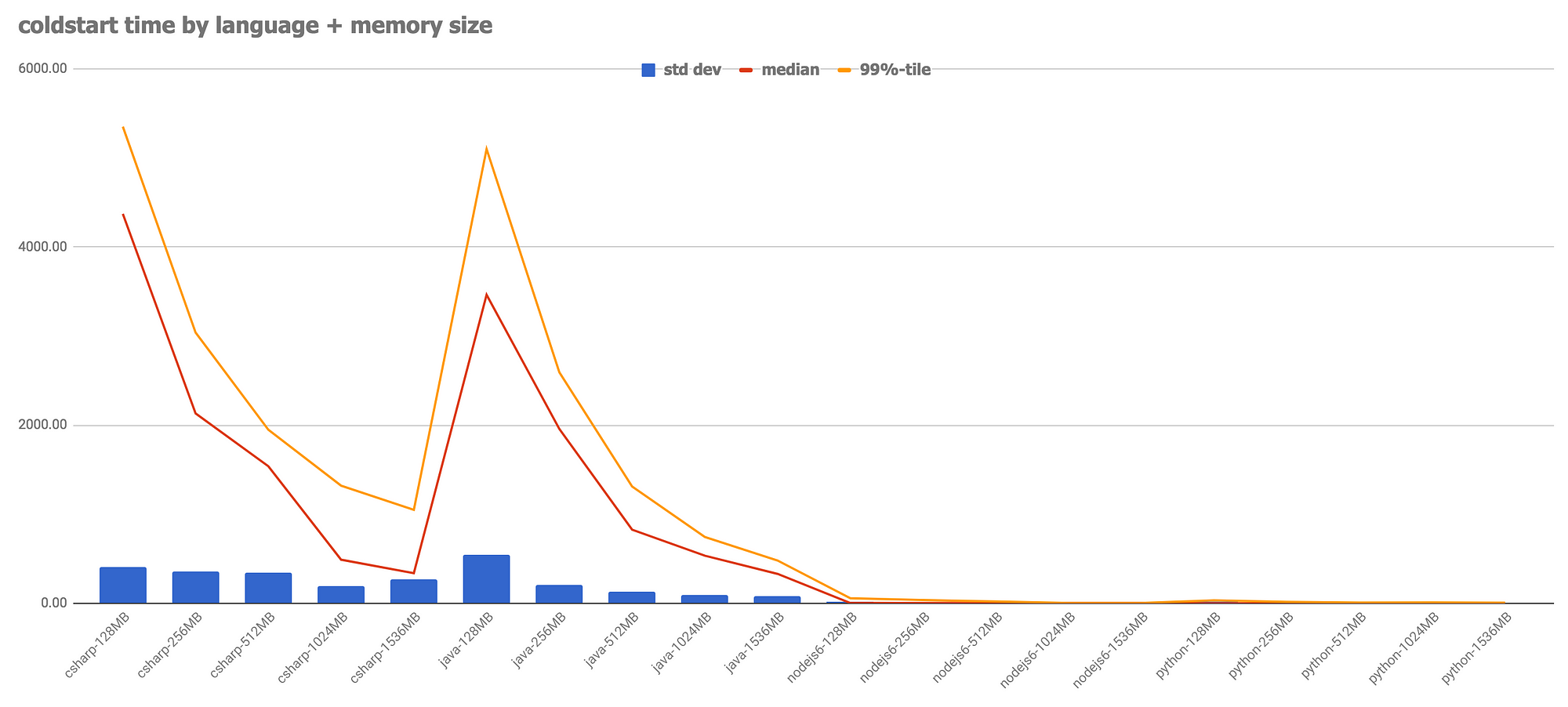
Are these issues of concern? This depends on the style and form of your application's traffic and the maintenance of your features. That being said, if you were writing an application with low latency, you probably wouldn't want to use FaaS systems at that time, no matter what language you use for implementation.
If you think your application may have problems like this one, you should test with a relevant production load to benchmark performance. If your use case doesn't work now, keep in mind that this is a major area of development for FaaS providers.
Write contract and provide API
So far we have discussed many concepts and services related to FaaS. But I particularly want to focus on one of them which is the API Gateway. An API Gateway is an HTTP server where contracts / endpoints are defined through a configuration. These will then generate an event that can be used through a FaaS function. As a general rule, API Gateways allow mapping parameters from an HTTP request to the input arguments of a FaaS function, then transform the result of the function call into an HTTP response and return it to the original caller. In addition to simply routing requests, this service also allows you to have functionality like authentication or even parameter validation, rate throttling etc.
The combined use of the Gateway + FaaS APIs can lead to the creation of a serverless HTTP frontend, in a microservices way, with all its advantages such as automatic scaling.
At the time of this writing, the API gateway tooling is immature and has many shortcomings when it comes to applying development processes (versioning, etc.).
Development Tools
This lack of maturity of the tools related to API Gateway services unfortunately also applies to FaaS services. However, there are exceptions: an example is Auth0 WebTask which gives significant priority to the development of user-oriented interfaces.
Among these shortcomings, we find a lack of debugging, versioning or logging features, even if these are beginning to be overcome little by little (e.g. X-Ray at AWS).
Going Serverless
After explaining why and when, let’s see How.
Today FaaS is difficult to adopt in companies and only some use cases are currently applicable. The main reason comes from the fact that it is still difficult to simulate internally all BaaS and FaaS parts and then certify that a solution will work exactly the same way once it goes into a production environment.
However, many solutions are being developed by both the open source community and the Cloud Providers to give Serverless applications the level of services and maturity needed to increase public adoption.
I will not be able to detail all the Serverless services available here but I invite you to go to the following page which contains an exhaustive list: Awesome Serverless
BaaS and our Cloud Provider friends
As detailed in the architectures previously discussed, there is no FaaS without BaaS. The main providers of these "turnkey" managed services are of course our friends the Cloud Providers. We can list 3 major players today. Of course, there are the giants: Amazon Web Services, Google Cloud Platform and Microsoft Azure, but solutions like Auth0 and Iron are starting to make a name for themselves.
Below is a summary of the primary 100% managed solutions available in the Cloud.
| Amazon Web Services | Google Cloud Platform | Microsoft Azure Services |
| Compute | ||
| AWS Lambda | Google Cloud Functions | Azure Functions |
| Storage | ||
| Amazon Glacier and Amazon S3 Standard - Infrequent Access | Google Cloud Storage Nearline | Azure Cool Block Storage |
| Amazon S3 | Google Cloud Storage Standard | Azure Block Storage |
| Amazon EC2 Container Registry | Google Container Registry | Azure Container Registry |
| Database | ||
| Amazon DynamoDB | Google Cloud Datastore or Google Cloud Bigtable | Azure DocumentDB |
| Big data | ||
| AWS Data Pipeline | Google Cloud Dataflow and Google Cloud Dataproc | Azure HD Insight |
| Amazon Kinesis and Amazon Simple Queue Service (SQS) | Google Cloud Pub/Sub | Azure Event Hubs and Azure Service Bus |
| Amazon Redshift | Google BigQuery | Azure SQL Data Warehouse and Azure Data Lake Analytics |
| Monitoring | ||
| Amazon CloudWatch | Google Cloud Monitoring and Google Cloud Logging | Azure Application Insights and Azure Operational Insights |
What about FaaS now ?
Integrating a function is relatively simple. It is generally a piece of code in a language compatible with the service provider (usually Javascript, Java, C#, Go and Python) that is compiled, zipped and deployed. The complex part resides in the configuration of the interaction between functions and other services (API Gateway, DB, Storage,...).
That is why we now have two approaches that are emerging within Open Source frameworks. The first one, mostly infrastructure oriented, will allow you to manage relatively easily the integration of your functions and all the resources related to them. These frameworks are usually based on APIs provided by Cloud Providers or DevOps services (e.g. CloudFormation for AWS).
The second way, is more API and Web-based resource oriented, it is the best match to the current vision of solution developers with a simple abstraction of the communication between an API Gateway and a function.
Infrastructure Way
Today, the development trend of the Open Source community is moving towards an Infra As Code vision. They make it quite simple, using CLI and configuration files, to interact with all Cloud services and manage the full technical stack associated with developing functions.
One of the actual best known implementations is the Serverless framework. It is compatible with the following Cloud solutions: AWS, IBM OpenWhisk, Microsoft Azure, GCP, Kubeless, Spotinst, Webtask.
To give you a first glimpse of what you can do, here is a little “Getting Started Guide” that you can do pretty quickly and see the power of these serverless features.
Requirement : AWS CLI with a valid AWS Account
$ mkdir my-first-function && cd my-first-function
$ serverless create --template aws-nodejs
Then change the serverless.yml file as follows:
service: aws-nodejs
provider:
name: aws
runtime: nodejs6.10
region: eu-central-1
functions:
hello:
handler: handler.hello
events:
- http:
path: users
method: get
Then run the following commands to test your new function:
$ serverless deploy [--stage stage_name]
$ serverless invoke [local] --function function_name
$ serverless info
$ curl $URL
$ serverless remove
API Way
One example of how to implement this approach is the Chalice framework. For history's sake, this framework was initially developed by AWS in order to reconcile and simplify the implementation for developers. It is currently in version 1.0.4 and is evolving very quickly.
It will allow you to develop your function more like a developer (as if you are developing using Spring framework) with no real need of knowledge about cloud services or infrastructure.
Just like the example on the Serverless framework, here is a quick overview of it:
Requirement : AWS CLI with a functional AWS account
$ chalice new-project s3test && cd s3test
Replace the contents of the app.py file with this one. It will allow you to create a REST /objects/{key} contract accessible through GET and PUT for getting or putting content on a S3 bucket.
import json
import boto3
from botocore.exceptions import ClientError
from chalice import Chalice
from chalice import NotFoundError
app = Chalice(app_name='s3test')
S3 = boto3.client('s3', region_name='eu-west-1')
BUCKET = 'ippevent-public'
@app.route('/objects/{key}', methods=['GET', 'PUT'])
def s3objects(key):
request = app.current_request
if request.method == 'PUT':
S3.put_object(Bucket=BUCKET, Key=key,
Body=json.dumps(request.json_body))
elif request.method == 'GET':
try:
response = S3.get_object(Bucket=BUCKET, Key=key)
return json.loads(response['Body'].read())
except ClientError as e:
raise NotFoundError(key)
Then run the following commands:
$ chalice local
$ http put http://localhost:8000/objects/document.json value1=123
$ http get http://localhost:8000/objects/document.json
$ chalice deploy
$ chalice url
In a few lines you can accomplish a task that would take much more if you had to manage the startup or to manage a server.
To conclude
Automatic scaling, pay-as-you-go, and automatic management of your services are all key concepts that characterize Serverless. Using this type of service requires careful consideration in order to understand your use cases and validate its applicability. This architecture may not suit certain use cases for several reasons, such as the need for synchronization in your communications. However, it can, in essence, provide you with guarantees of high availability, data resilience and automatic scalability of your services without additional effort on your part.
Remember, this is not a solution that can be adapted to all applications. Many constraints on FaaS, related to its event-driven nature of communication, can quickly become blocking and add complexity to the sequencing of your exchanges. On the other hand, these services can quickly bring you its financial benefits as well as scalability and adaptability.
The last issue, at the time of this writing, is the lack of maturity in terms of both tools and processes. Some technological components are still recent (3 years for AWS Lambda). You will therefore have to take into account the technical debt generated by this type of solution due to the rapid rate of change.
Regardless of the many constraints, it offers numerous opportunities. Many companies are already starting to use it and we are starting to have our first case studies presented at conferences.
Finally, this type of service is rapidly evolving and the catalog of 100% managed products is growing. Each of the parties (Cloud Providers and users) are winners in the use of such services and thus guarantee a flourishing future that will bring homogeneity and security to the world of IT infrastructure and hosting.




Comments