


Apache Spark Streaming applications need to be monitored frequently to be certain that they are performing appropriately, due to the nature that they are long-running processes. There are many different configurations that can be optimized to achieve a higher performing application.
Batch Size
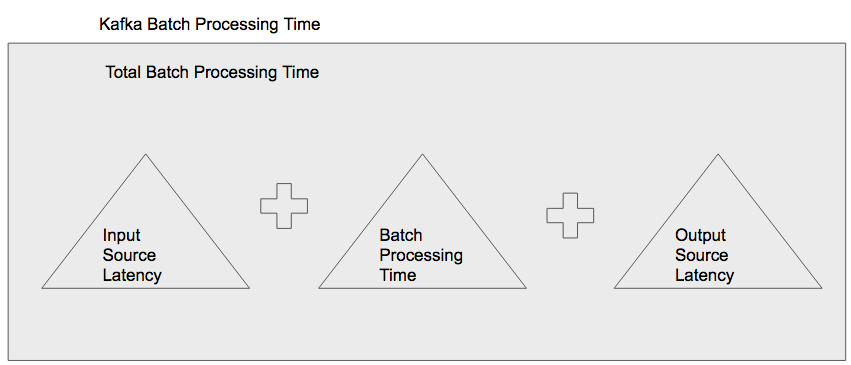
Batch size is a very important element to a streaming job. This is the amount of time between either polling a streaming source such as Kafka, or collecting messages from a custom source using a custom receiver. Other than your application’s use case requirements, there are three elements that impact the appropriate batch size: the average amount of data streamed in that period of time, the average connection time between Spark and the input source, and the average connection time between Spark and the output source.
There is a network cost to connect between your Spark Streaming Application and your input source that is out of the control of your application. For example, if you have a known latency between your Application server and the input source server, you should make sure that the batch size is longer than the latency. This is especially true if you are using Kafka as an input source, because pulling the data takes place within the batch processing time. With a custom receiver, the data is pulled on receipt of the message; in many cases, the connection latency will impact the message being received by Apache Spark and not the batch processing time. However, this will impact the optimal batch size if you already have a large latency connecting to receive each message. In this case, you will want to have a small batch interval so as to not increase the overall latency of the message delivery.
The data processing time is another influencer of your batch size. This is the amount of time it actually takes to execute the transformations and actions in your code. The data processing time depends on the data and transformation complexity; some trial and error testing is suggested to find the best possible batch size. Some large data sets can be processed rather quickly, so a small batch size is fine. With some data sets, the transformations will always take a long time regardless of data size, and so a larger batch size is needed. In short, the batch size must be greater than the total of the data processing time and the input latency.
Finally, the connection time between your Spark application and the output source needs to be taken into account if this output cannot be done asynchronously. If you can write the output asynchronously, you do not need to take into account any latency associated with the output source into the batch size. If the data needs to be saved before the next batch is processed, then the save needs to be synchronous, and so the connection latency needs to be taken into account. In total, the batch size needs to be larger than the total of input and output latency, and data processing time so that there is no scheduling delay between batches.
Performance of Custom Receivers
Sometimes, the source of your data needs to be a messaging queue or a socket connection which needs custom receivers. When writing a custom receiver, please keep in mind that there will be only one receiver per source by default. To avoid performance issues, application logic needs to be coded such that there can be redundancy with the connector. For instance, when connecting to a messaging queue that has multiple servers in the cluster, each receiver will be responsible for one server in the cluster. If the server running the receiver is having an issue, Spark will not always immediately move the receiver to another server, and without redundancy, data could be not read off that message queue. Having a second executor that is also running the same receiver could help mitigate this issue and hold off any performance issues.
Another possible issue with custom receivers is that the receiver takes the entire processing power of the executor, and so no data processing will happen on that executor. This should be taken into account when determining the cluster size and number of executors since you need an executor available to process the data. If you need to have 3 custom receivers, and you need 2 redundant connections to make sure there are no performance impacts, the cluster will need to have at least 8 executors; 6 will be needed for the custom receivers, 1 for the driver, and 1 for running the batch logic. If an application is ran with no available executors for data processing, the application will appear to be running, but the first batch will never finish processing. If you examine logs you can see logs associated to reading the data from the data source but no logs will be written that are associated with the transformations and actions.
Increasing the Batch Performance
Another potential performance issue occurs when the data cannot be spread across enough executors because there are not enough allocated to the application. You can increase the performance power by either adding in a new worker to the cluster, or putting more executors on each worker. This will increase performance power, and also allocate less data partitions to each executor since there are more to divide the data between. By default, there will be one executor per worker, and all the cores will be allocated to that executor. If the processing power of the executor could be lowered without slowing down the processing, you can change the worker to have one executor per core on each worker by changing the spark.executors.core property. When this variable is set to 1, each executor will only take 1 core; if your worker has 3 cores, there will be 3 executors per worker. If the executors need to have all the cores for the necessary processing but more parallelization is needed, then more workers can be added. These workers can be added on the fly without restarting the application. Auto scaling can also be configured so when certain conditions are met, more workers can be dynamically added.
Another way to examine the performance of the batch processing is to examine the code to make sure that there is not too much data being executed on the driver, rather than the workers. If you perform a collect or other actions that pull the data back to the driver before a filter, this will slow performance. If there are ways that the logic can be altered so filters are performed first, then there is not as much cost to pulling the data back to the driver for processing.
Limiting the amount of data
Sometimes you become aware of a streaming source that may have batch data being pushed through to the streaming source. This creates a large amount of back pressure onto the Streaming Application. The issue could be because of a batch analytic job that sends a message or by a backup of data in the input source where hours worth of data is sent at once. One example of how this could have happened is if there was application maintenance; all the messages that would have been streaming during maintenance could be sent all at once. This may end up causing issues with the downstream system depending on what the output source might be. You could be writing to an API that has a limit on how many times it could be triggered in a second or a database that has an issue with too many concurrent writes happening at once.
If your application has these kinds of limitations to prevent them from causing performance issues, you can limit the amount of data that is pulled in one batch while using the Kafka connector to mitigate issues. When you submit a Spark application, you can pass the variable spark.streaming.kafka.maxRatePerPartition to limit the amount of messages that can be pulled per partition. For example, if your database only allows 1000 writes per second and the application reads from 10 Kafka partitions, the variable should be set at 100 so only 1000 messages are pulled in each batch.
There are other ways to tweak a Spark Streaming application but these are the most common solutions that my team and I have used to speed up the performance of our applications. Happy Coding!



Comments