

Published August 11, 2022
Matillion is a great ETL tool for bringing over data from disparate sources into one central location (Snowflake, for example). Matillion provides a number of tools and components that will help you ingest and transform your data, but one of the most valuable assets would have to be its concept of Job and Grid Variables. With these, you will be able to add a level of dynamism that simply cannot be achieved any other way. Let’s take a look at an example.
Bring In a Set List Of Tables
In this example we’ll have a set list of tables that we know we would like to bring into Snowflake. One option we could do is create a table on Snowflake that can hold these values for us to use within Matillion.
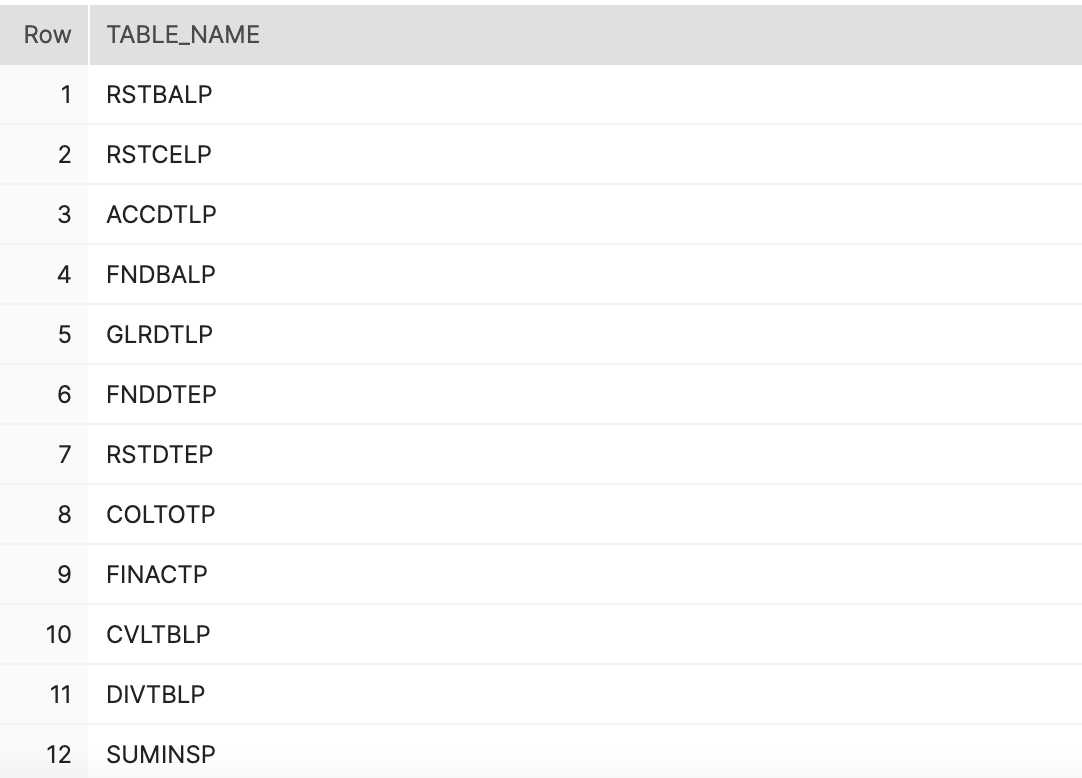
We can then take these values and assign them to variables within our Matillion job and have our ingestion process be driven dynamically with the values found in this table.
Now it’s time to set up our Matillion orchestration job and define a variable we can use there.
Set up a Variable in Matillion
There are two types of variables in Matillion - Job and Grid variables. A Job variable can hold a single value, whereas a Grid variable can be thought of as an array holding multiple values. For our example, we’ll be using a Job variable.
Within our orchestration job, right-click and select 'Manage Job Variables'.
On the next screen, click the '+' sign at the bottom to add a new variable. In this case, we’ll name our new Job variable 'table_name'.
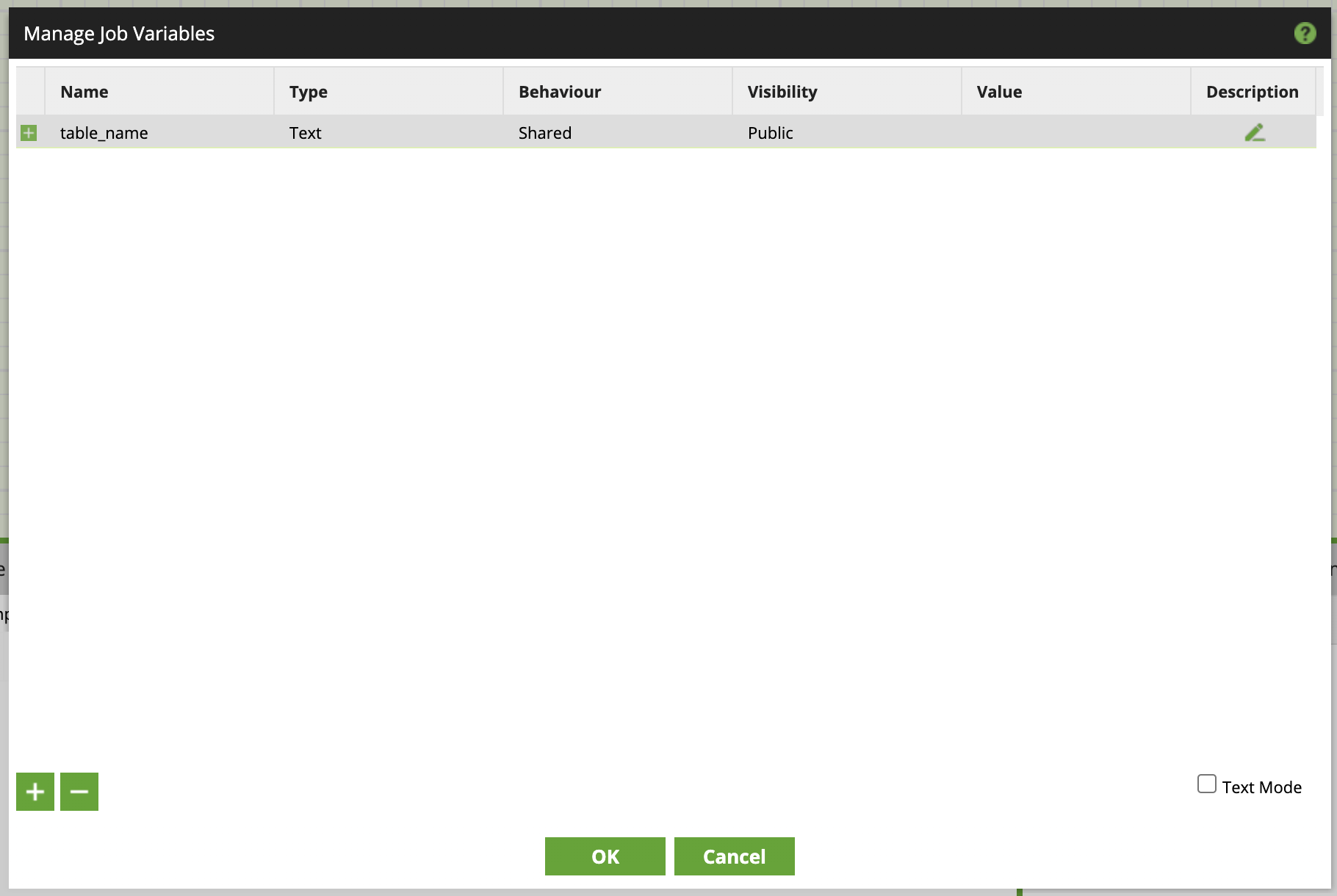
We’re now ready to use this new variable to help us cycle through our list of tables.
Build the Orchestration Job
Within our Matillion orchestration job we’re going to use a couple of components: Database Query and Table Iterator. The Table Iterator will allow us to iterate over our Snowflake table and assign each table name to our Job variable.
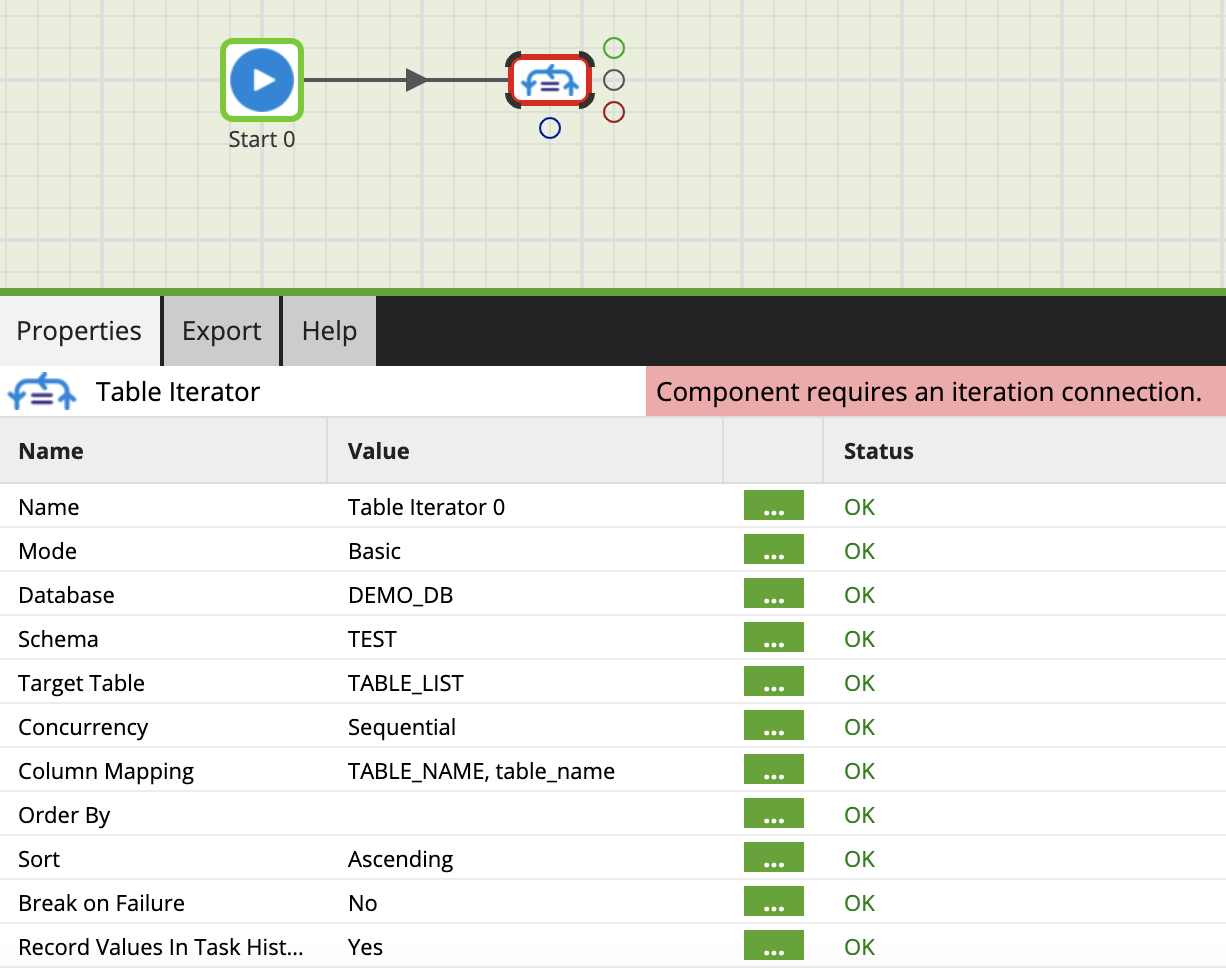
Point the Table Iterator to the Snowflake table holding your list of table names by filling in the Database, Schema, and Target Table values. The Column Mapping entry is where we link the values in our table to the Job Variable we created earlier. Now on each iteration our table_name variable will be updated with a new table name from our list.
This is great so far, but we need our job to actually do something over each iteration, namely load our tables into Snowflake. We’ll pull in a Database Query component and instead of only loading one table, we’ll connect it to our Table Iterator to load all tables on our list.
Now here is where our Job variable will tie everything together. Within our Database Query component, we’ll enter the required info such as Connection URL, Username, and Password, but we’ll also be using our Job Variable when we fill out the SQL Query and Target Table values.
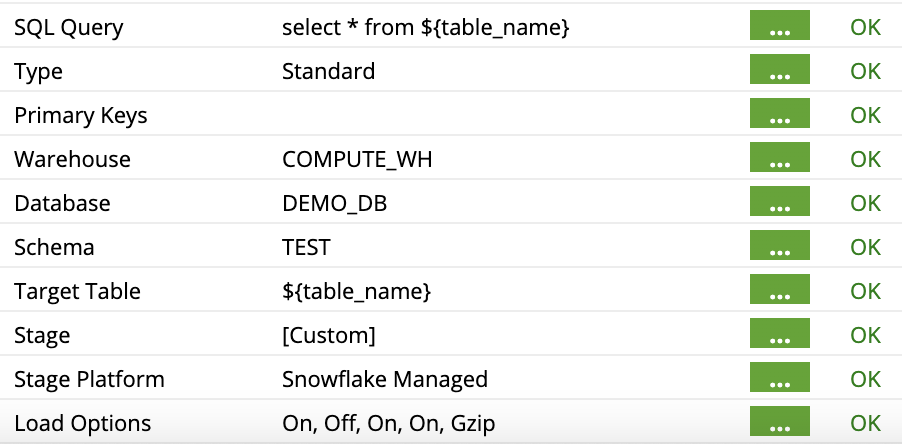
Here we’ll use ${table_name} to signify that we want to use the value found in our Job variable. Since the Table Iterator will make sure we go through each entry in our list of tables, we’ll be able to bring in each table by simply using these two components and one Job variable.
Conclusion
Matillion variables make it easy to create dynamically driven jobs that can rely on data found outside of Matillion itself. This can allow anyone to update jobs without having to go into Matillion at all, in this case adding new data to bring into Snowflake by simply updating a table that contains table names.
Need help using Matillion? Need help designing and implementing your future Data Warehouse? Ippon can help! Send us a line at contact@ippon.tech.

.png?width=520&height=294&name=Ippon%20(3).png)
-1.png?width=520&height=294&name=Ippon%20(2)-1.png)

Comments