


Big Data is one of the industry’s new frontiers. Organizations have applied batch intelligence against larger and larger amounts of data; much of which is unstructured and previously thought to be throwaway (log files fit this category). But an application that uses logs in an intelligent way can do much more than debug production bugs with the files. It’s an event by event record of everything that is occurring in your software system and with intelligence applied can show patterns and behaviors to give a competitive advantage in improving the product, knowing more about your customer, and so on.
Now that we have been using Hadoop and Map-Reduce procedures for a few years, the question has become: how can we be proactive and gain the intelligence in real-time vs. waiting for a server cluster to run some batch processes? This enters into the domain of complex even processing. Such products have been around for some time but to my knowledge have all been proprietary/commercially licensed. I have some experience in Event Insight – owned by SAP, originally Sybase CEP. But as so often is the case, it takes open source to really get a technology vertical moving forward at an aggressive pace. Enter the frame Apache Spark, Apache Storm and Spring XD (extreme data).
The following matrix takes a side by side look at all three. Please remember that this is a point-in-time reference from near the publication time of this post and might be slightly dated as you are reading.
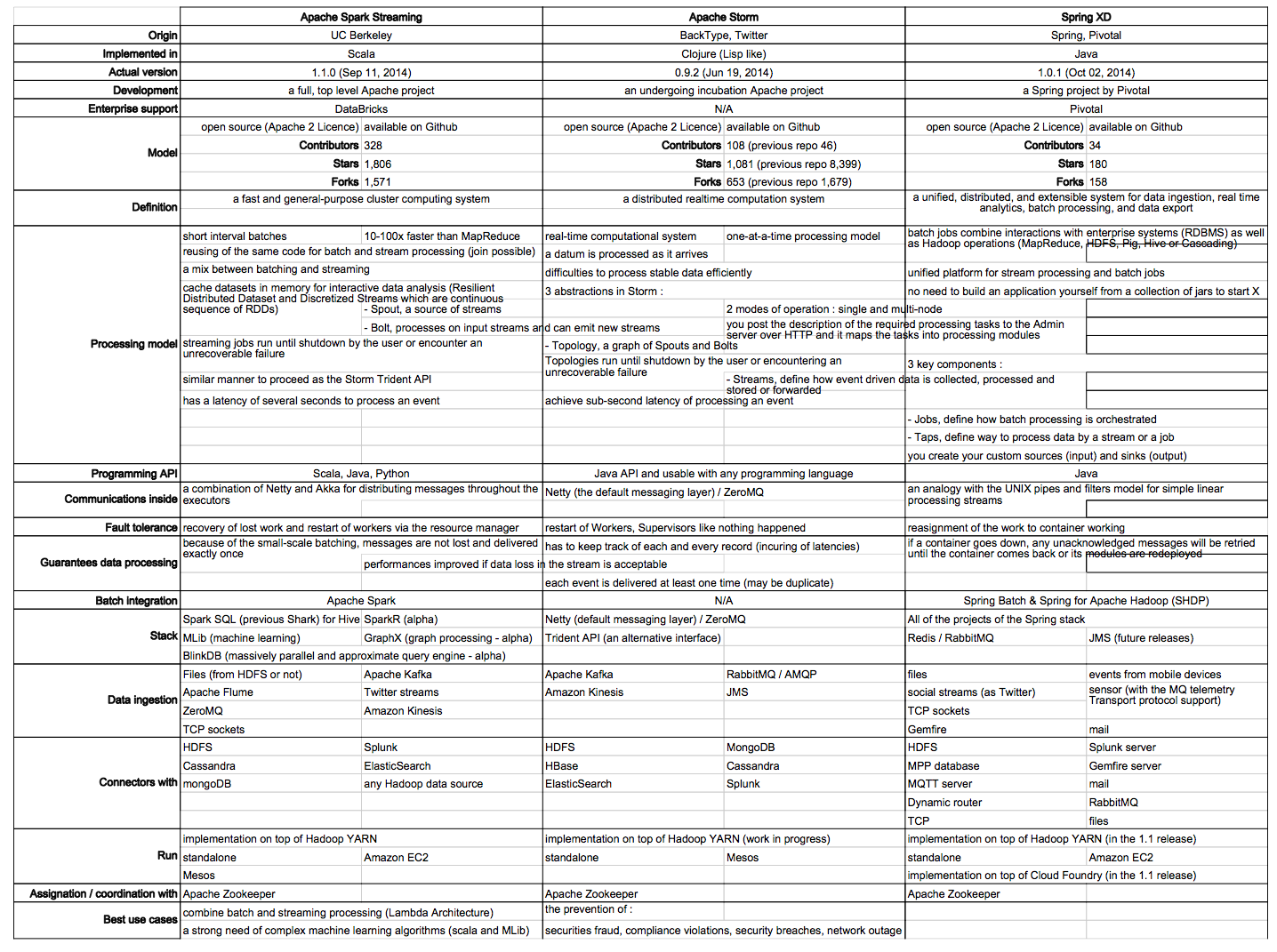

Matrix courtesy of Antoine Hars, Ippon.
That’s a lot to digest, so what stands out? Apache Spark is the most active project in the open source community based on GitHub metrics with Storm second most active. Spark Streaming and Storm is probably the closest comparison to actually make. Spark Streaming is one component of the project focused on the real-time aspect. Storm is strictly a real-time computational system and does not have a batch component (definition note: a Big Data architecture that combines both batch and stream-processing components is known as a “lambda architecture”). The difference here are that Spark Streaming is actually processing in short interval batches and Storm is computing in real time. This yields at least two key points: Spark Streaming will have a latency (reported to be a few seconds) while Storm can achieve a sub-second latency and then that Spark Streaming will guarantee that each event is processed once and only once where Storm’s fault tolerance model guarantees that events are processed at least once. A nice inherent effect for Spark in this way is that code can theoretically be re-used for streaming and for batch.
Here are two similar architecture diagrams that I came up with while doing some proof of concept work for each:
Architecture diagram 1. Apache Spark with Kafka, Cassandra and ElasticSearch. Ippon USA.
Architecture diagram 2. Apache Storm with Kafka, Redis, NodeJS. Ippon USA.
One important note here is that the two diagrams could be made to look even more similar but we may do some proof of concept with the data connectors as well. Apache Kafka is constant between the two because of the available data ingestion methods available, we like Kafka above others.
So where does Spring XD fit? Spring XD is more of a development facade for Big Data applications. It leverages other Spring offerings such as Spring Data, Spring Batch and Spring Integration to create something of its own lambda architecture. The bar of entry for Big Data becomes a lot lower, especially for shops that are familiar with other members of the Spring family. I personally have not yet delved into Spring XD and my focus has been more on Spark and Storm recently. We also have not found as much literature of groups using Spring XD yet in production settings so it’s difficult to get a feel for the type of problems for which it is better suited than the others.
Hopefully you enjoyed reading. Thanks to my colleagues at Ippon and the other bloggers called out in the matrix for their work. If you would like to see more publications as the proofs of concept move forward, let me know.

Comments