


Depending on your use case, you might want to synchronize the two buckets based on an event or on a daily basis. In order to do that, the easiest option is just to go serverless and have a Lambda that will take care of the syncing process.
Lambda Layer to the Rescue
AWS CLI in a Lambda?
By default, the Lambda runtime includes additional libraries like the AWS SDK so you can interact with your AWS infrastructure. For more details about the Lambda runtimes and which libraries are included, check the official page here.
The problem with the AWS SDK and Boto3 is that the s3 sync command is not available, which means that you will have to write some custom code. Reinventing the wheel is not really something recommended in software development because it might take a while to write something stable and reliable. In addition, the sync command from the CLI includes several handy options, such as include and exclude, so let's just step back a little and figure out a better solution.
Lambda Layers
To have additional features and libraries available for your Lambda, you simply have to build a Lambda layer and have your Lambda use it. By having a layer that includes the AWS CLI, your Lambda will be able to call the CLI and then run the sync process like you would do from your terminal.
There are multiple ways to build your own layer but in our case. Since we are going to use AWS CDK to deploy our Lambda, we can use the lambda-layer-awscli module. This module is easy to use and installs the CLI under /opt/awscli/aws in the Lambda.
Lambda
I decided to use Python to write the Lambda as the sync process is pretty straightforward. The while loop streams the outputs from the sync command to CloudWatch.
import logging
import os
import subprocess
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def sync(event, context):
# Lambda to sync two buckets using the aws cli
s3_sync = subprocess.Popen(
"/opt/awscli/aws s3 sync s3://{} s3://{}".format(os.environ['SOURCE'], os.environ['DESTINATION']).split(),
stdout=subprocess.PIPE)
# Stream logs from the cmd
while True:
output = s3_sync.stdout.readline()
if s3_sync.poll() is not None:
break
if output:
logger.info(output.strip())
s3_sync.poll()
The two environment variables SOURCE and DESTINATION contain the buckets' name and are populated by CDK during the stack deployment.
Deployment and Test
Architecture and Diagram
The architecture must be capable of running the syncing process daily by using the Lambda:
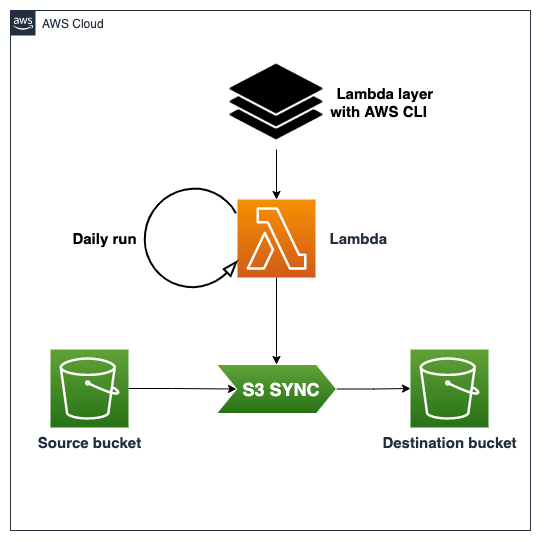
AWS CDK
I have been a huge fan and advocate of AWS CDK since its first release, as it abstracts concepts like permissions and service interactions. Writing code with your favorite language that ends up deploying components on the Cloud can be quite addictive!
Below is the code that defines our infrastructure:
from aws_cdk import (
aws_events as events_,
aws_lambda as lambda_,
aws_s3 as s3_,
aws_s3_deployment as s3_deployment_,
aws_events_targets as targets_,
lambda_layer_awscli as awscli_,
core as cdk
)
class BlogLambdaAwscliStack(cdk.Stack):
def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Create S3 buckets
bucket_source = s3_.Bucket(self, "Bucket Source")
bucket_destination = s3_.Bucket(self, "Bucket Destination")
# Create Lambda
fn = lambda_.Function(self, "S3_Sync",
function_name="S3_Sync",
runtime=lambda_.Runtime.PYTHON_2_7,
handler="index.sync",
code=lambda_.Code.asset('lambda'),
environment={
"SOURCE": bucket_source.bucket_name,
"DESTINATION": bucket_destination.bucket_name
},
timeout=cdk.Duration.minutes(15))
# Add Lambda layer containing the aws cli
fn.add_layers(awscli_.AwsCliLayer(self, "AwsCliLayer"))
# Grant Lambda access to S3 buckets
bucket_source.grant_read(fn)
bucket_destination.grant_read_write(fn)
# Deploy data folder to source bucket
s3_deployment_.BucketDeployment(self, "Deploy files to source bucket",
sources=[s3_deployment_.Source.asset("./data")],
destination_bucket=bucket_source)
# Trigger lambda every day
rule = events_.Rule(self, "Rule",
schedule=events_.Schedule.rate(cdk.Duration.days(1)),
)
rule.add_target(targets_.LambdaFunction(fn))
I decided to use the Official COVID-19 Data Lake and the folder static-datasets for the source bucket. CDK will take care of uploading the data folder to the source bucket using BucketDeployment.
Testing
The project is available at this GitHub Repository in case you want to clone it. You can follow the instructions to deploy / destroy the stack:
# deploy the stack
cdk deploy
# destroy the stack
cdk destroy
Your console should output something similar once the stack is successfully deployed:
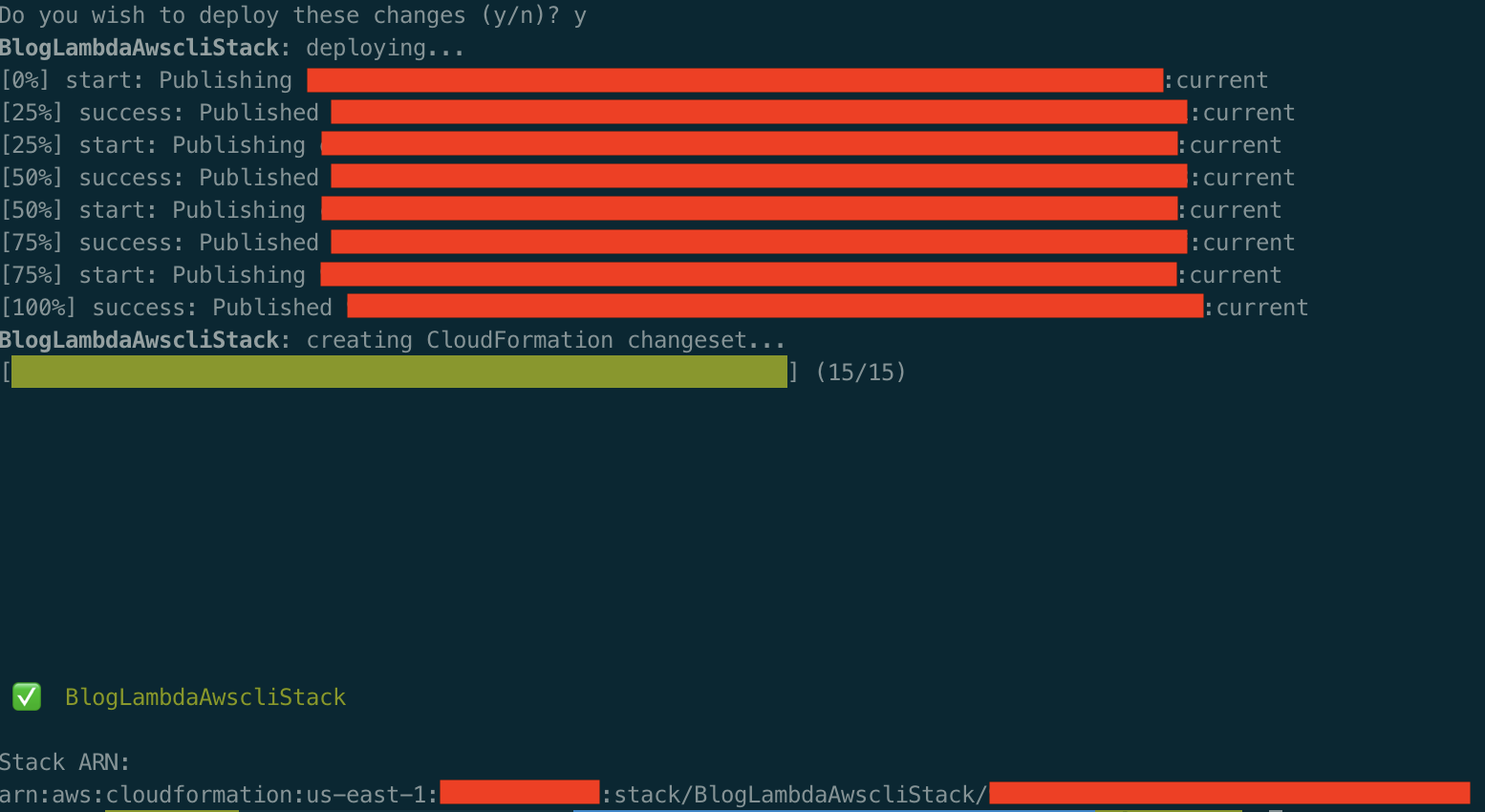
You can manually trigger the Lambda in order to test and then check the CloudWatch logs (we can see the progress of the sync):

Check the destination bucket to make sure that the COVID data was correctly synced:

Caveats
The main "issue" with AWS Lambda is the "15-minute timeout," which essentially means that the Lambda can timeout before the end of the syncing process in case of a large bucket. The good news is that the Lambda can just re-run and continue the syncing process until it's over because files are created on the fly.
It might be a good idea to do the first sync manually, as a large amount of data will take multiple hours. Then, depending on your use case, you can just reduce the schedule to run the Lambda every 30 minutes, for example.
Need help using the latest AWS technologies? Need help modernizing your legacy systems to implement these new tools? Ippon can help! Send us a line at contact@ippon.tech.




Comments