

I attended Spark Summit East 2017 last week. This 2 day conference - February 8th and 9th - gathered 1500 Spark enthusiasts in Boston.
While I mostly followed the sessions about Data Engineering, Data Scientists were also able to find Data Science related talks. Here is my take.
Structured Streaming
One subject that drew a lot of attention is the Structured Streaming. Matei Zaharia introduced it in the opening keynote.

Michael Armbrust then gave a very good demo of this new functionality of the framework on the Databricks platform.
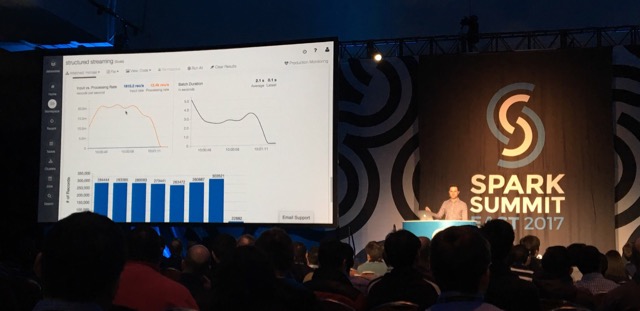
Tathagata Das - a.k.a. TD - then went into further detail, but I have to say I have mixed feelings about this presentation. To start with, while the idea of performing stream processing without having to reason about streaming sounds appealing, I think this is also the best way to get into engineering pitfalls...

Spark's Structured Streaming capability brings a much more powerful way to perform stateful processing. This relies on state stores and resembles what Kafka Streams already offers.

To end his talk, TD showed a comparison of Spark's Structured Streaming capabilities with other frameworks' capabilities. I find this to be very biased...
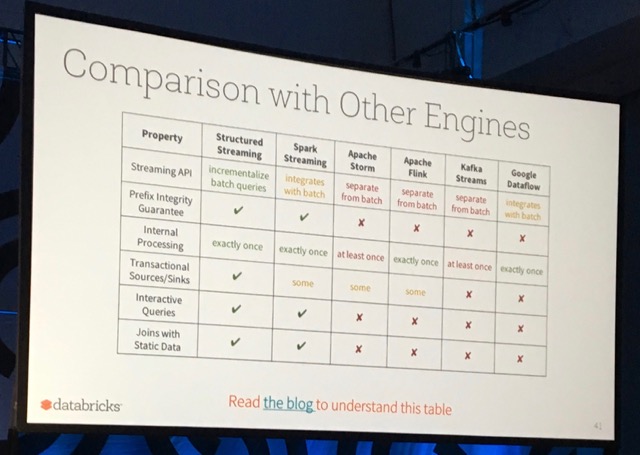
From my point of view, the main things to remember from Spark Structured Streaming are:
- Structured Streaming provides a Dataframes API, where Spark Streaming was only offering RDDs.
- Stateful processing becomes a first-class capability of the framework.
- Structured Streaming is not an event-by-event processing framework. It still uses micro-batches though no one seems to be using this term any more.
- A lot of effort has been put into improving the Kafka connector (it was about time, to be honest).
Streaming with Kafka
A few talks were about the experience of large companies with Spark Streaming and Kafka. Shriya Arora explained how she worked on a realtime Machine Learning implementation at Netflix.


Snehal Nagmote talked about indexing products in realtime at Walmart. They use a lambda architecture and Snehal gave a few interesting takeaways on using Cassandra with Spark.
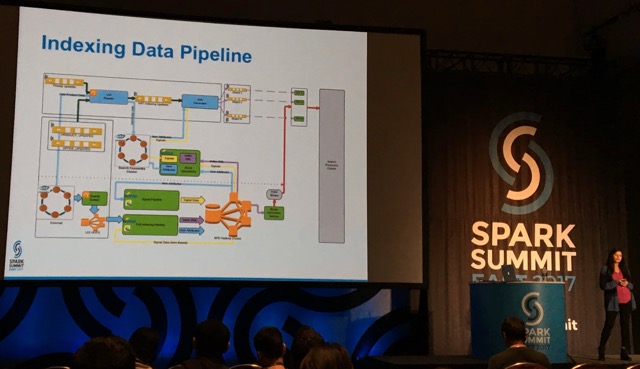
Another talk was from Ivy Lu about a realtime pipeline based on Spark and Kafka to process credit card transactions at Capital One (a project in which I proudly took part!).
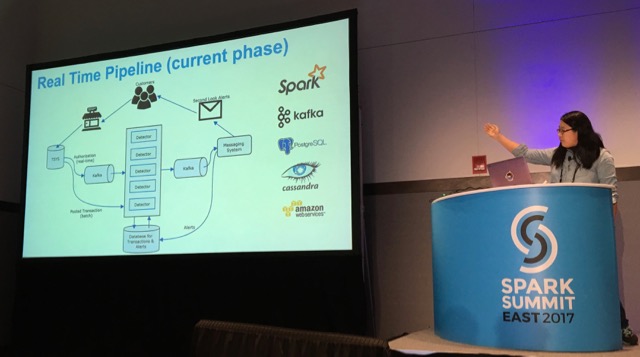
From these 3 talks, it is very clear that implementing a Spark Streaming application with Kafka poses a number of serious problems (some of which I already covered in a talk). An alternative to using Spark was actually provided by Ewen Cheslack-Postava - from Confluent - in his talk. He suggested to use Kafka Streams as a replacement (give it a try, this is a very good technology).

Storage formats
Choosing the right file format is very important to achieve a good level of performance with Spark. In her talk, Emily Curtin gave a very good presentation of Parquet, how this format stores the data on the disk, and how to use it with Spark.

Jacky Li and Jihong Ma presented Carbondata, an alternative to Parquet that seems to be optimal when you need to read data and need to filter on some values.

Given how Parquet is widespread and well maintained, I would recommend to put your efforts into using Parquet correctly before resorting to using another format such as Carbondata.
A few other talks
Jim Dowling talked about using multi-tenant clusters. He showed how Hops Hadoop provides Hadoop/Spark/Kafka clusters as a service and how users are billed for the resources they use from the shared cluster. This is interesting to see how to let users make responsible usage of cloud resources.
While I am more interested into programming in Scala, I could not miss Holden Karau's talk about debugging PySpark applications. I highly recommend this talk as it gives many useful tips for PySpark users.

Finally, Ion Stoica presented the goal of the RISELab. The RISELab replaces the AMPLab that gave birth to Spark, and will focus on Real-Time Intelligence with Secure Execution. I am convinced some interesting tools will come out of this new lab!

Conclusion
While I only covered the engineering aspects here, it was interesting to see how Spark is used in many industries, from making recommendations of what to watch on TV to very advanced research on genomics.
All the videos have been published on YouTube and can be accessed from the schedule of the talks. I encourage you to check them out.



Comments