

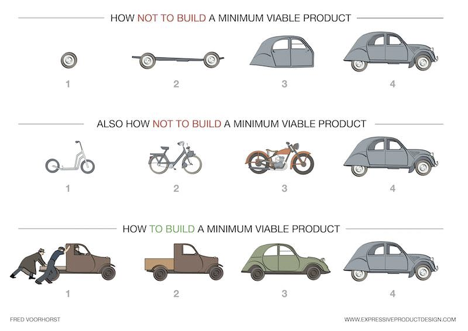
Teams have a hard time developing an enterprise application as an MVP first. It’s easy to find graphics that visualize this idea, but it can be challenging to bring that concept back to your project.
Project grooming
So let’s dive into how to do it with a real-world example.
The product: a batch process to fetch multiple document types, from different repositories, and deliver them to a drop box.
A few sprints out, at grooming time:
Business requirement:
As a batch document requester I want the documents delivered to me on a SFTP dropbox as a tar file.
Clarifications:
- What data points were available to the requesting system
- What data points were needed to fetch the documents
- Which services were needed to enrich the data points
- The preliminary API format and communication method for our dependencies (synchronous, asynchronous)
- Identified the first type of document to support
- Expected load, SLA
High-Level Design:
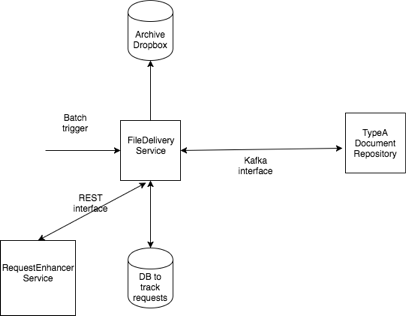
Our service will process in batch, a file containing thousands of requests, enrich each one with the external RequestEnhancerService and send asynchronous requests to a document repository using Kafka. Our service will then track the responses, and package all the documents and deliver them to the SFTP dropbox.
To manage our process, we used Scrum. We had 2 weeks sprints, and in our Definition of Done we had to use automated tests and automated deployments.
Development
Our first sprint:
For our first sprint we decided to mock out all of our dependencies (we had identified three), and work on coming up with an internal design for our FileDeliveryService. We created a few mock responses from the RequestEnhancerService, as well as mock responses from the Kafka interface. This way we didn’t have to integrate with Kafka on our first sprint, and we didn’t need to coordinate with external teams to enhance our request.
With those assumptions, we did build a system that could process the batch document and package files into a tar file to be delivered to an SFTP dropbox.
Value add:
- We can share the tar file with our clients to get feedback on its format, and content
- We received feedback that the archive was too big and would prefer to receive it in chunks.
- We received feedback that they would like to have a manifest file with each archive.
- We have a preliminary full slice architecture to build upon and validate
- We can build concurrently with our dependencies, and integrate with them once they are ready
Second sprint:
We created a manifest file to accompany each archive as an excel spreadsheet. Our RequestEnhancerService dependency was ready for integration, so we also accomplished this in this sprint.
We also did preliminary performance tests to track the performance of our different stages of the process. We discovered that our parsing of the batch file and our archiving process was slow.
Value add:
- We can share the manifest with the clients to get feedback
- We integrated with one of our dependencies
- We understand the weak points for our performance
Third sprint:
We integrated with our final dependency, and did some performance tuning. We incorporate a framework, Spring Batch, to make our file processing faster, and we multithreaded the archive process.
Value add:
- We have a system fully integrated
- We improved our performance to be within our comfort zone for our SLA
Fourth sprint:
We standardized our logging strategy and created monitoring and alerts using Splunk. We were ready for a beta release, so we deployed to production and identified a client to do a test run with.
Lessons learned from running in production:
- SFTP upload sometimes fail/timeout and we need to be able to redeliver without redoing the entire batch request.
- Performance: While the first document type was fast enough, the next document type will stress the system and we will need better performance.
Value add:
- Even though our beta run wasn’t perfect, the client was very happy to see progress and was able to use the portion of documents delivered.
- Our logging and monitoring made troubleshooting production issues easier to diagnose
Fifth Sprint:
We implemented an auto retry to upload the archive, and added a new REST interface to be able to manually trigger an upload retry so we didn’t have to run the batch request from scratch again. For performance improvements, we made our system scalable so multiple instances could share the load.
We did another beta run to validate our changes.
Value add:
- We made our system more resilient to failure
- We made our system scalable to handle different loads.
Sixth Sprint:
We released our first version to all clients, and started working on the refactoring needed to be able to support the next document type.
Summary
Using this approach, even though we didn’t have releasable software at the end of each sprint we were able to provide value each sprint and get feedback straight from our clients. Our product release had a very successful launch; we know this because we succeeded in our goal and our customer feedback was very positive.
Some things we keep in mind when building our product:
- Find the quickest route to start interacting with the end users; their feedback is invaluable.
- Always use the simplest solution first, and build in the complexity in layers.
- Mock out dependencies so you have an isolated testing suite.
- Allow time in each sprint to refactor.
.png?width=520&height=294&name=Webflux%20image%20(1).png)


Comments