


December 9, 2019
I attended a session from Stefano Buliani, Principal Business Development Manager at AWS, in which he gave some recommendations on how to fine tuned Java code to avoid the long cold starts seeing while deploying it to Lambda.
As he told the story of how he was woken up in the middle of the night with a customer incident, he walked us through the process of improving the Java code to pass from a P99 percentile of 24 seconds latency with a P100 over 30 seconds to getting a cold start well under 6 seconds.
The first and simplest solution he described was to increase the amount of memory allocated to the Lambda function. This brings with it more compute power which in turn reduces the amount of time required to initialise the code. That solution works only as a temporary one as it implies extra cost only to reduce the cold start as the extra performance is not needed once the JVM is initialised.
The next step described was to reduce the number of classes loaded by the JVM. His example only required the AWS SDK to make a call to DynamoDB and even in this simple case, the number of classes loaded reached 4130. By using simpler libraries (in the case of the AWS SDK, the SDK for Java version 2 is more modularised which allows for importing less dependencies) and excluding dependencies from those libraries, the number could be greatly reduced, improving initialisation time. As an example, the Apache HTTP client requires loading many dependencies to better handling concurrent requests, which in general is not needed in the context of a Lambda. Switching to the URLConnection class found in the standard library reduces further the required dependencies.
One of Lambda’s features is its ability to burst the CPU provisioned during the initialization phase, throttling afterwards to the amount configured, to reduce the cold start time. By leveraging this, Stefano was able to cut down around 6 seconds of the total time required by the Lambda to execute the code. To accomplish this, he moved all the code that could benefit from this extra compute power to the initialisation phase by using static fields and blocks. In his example he moved the dependency injector framework (in this case Dagger 2) from the handler to a static variable and then used it to initialise the DynamoDB client to yet another static variable.
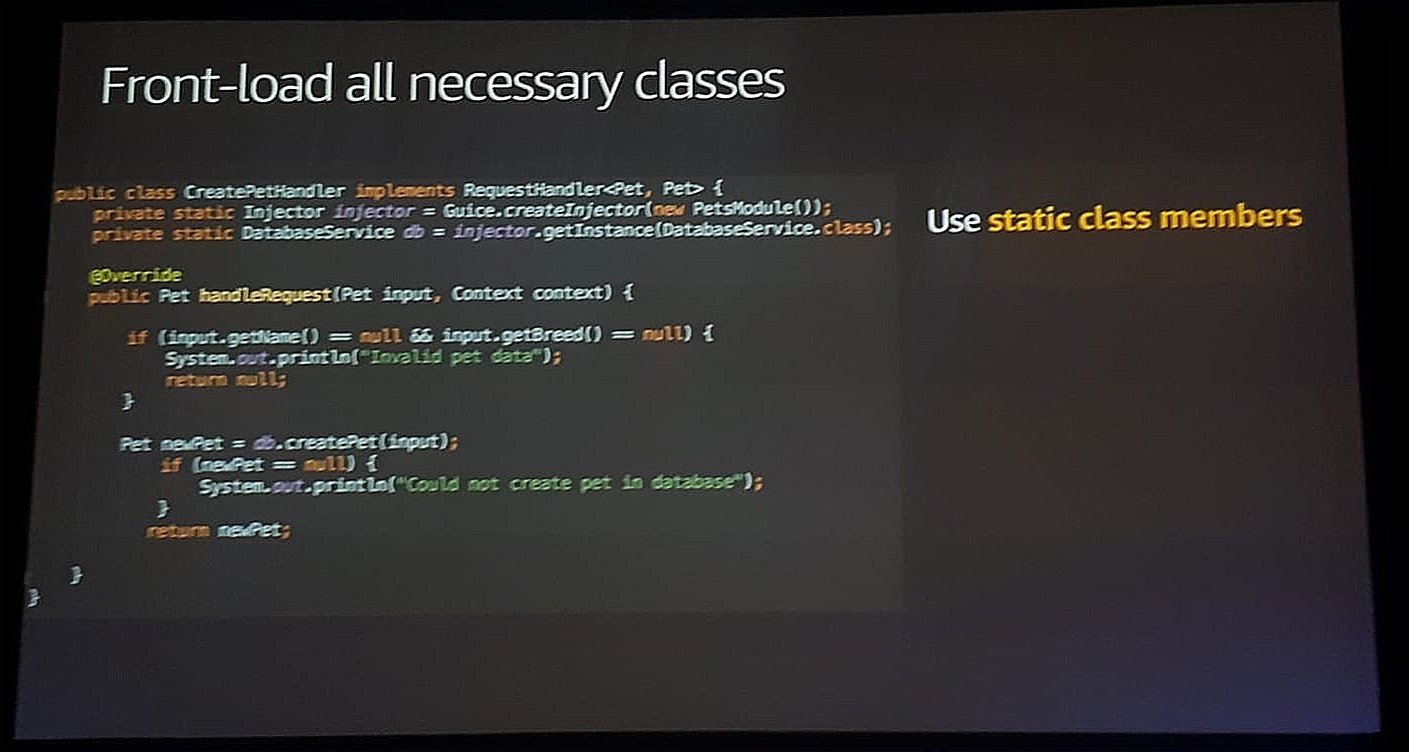
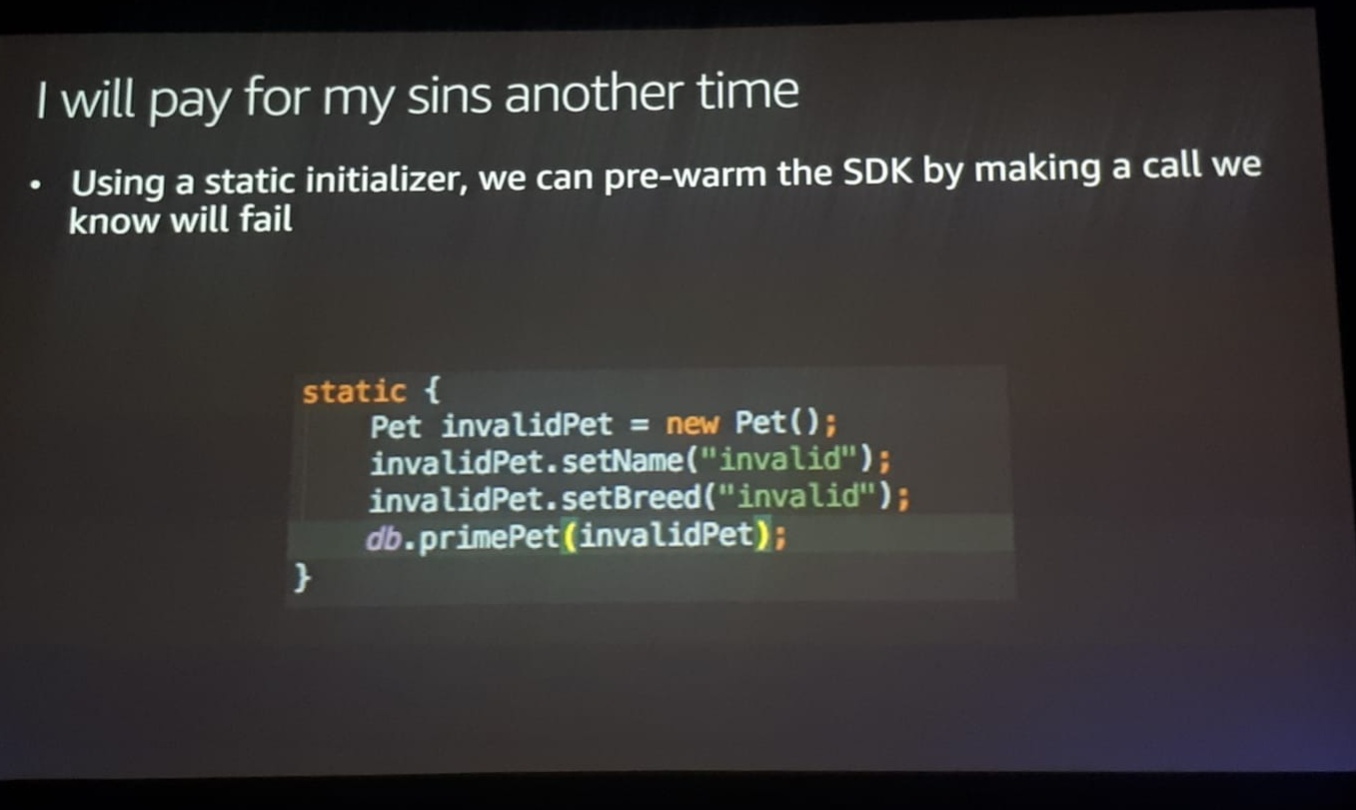
He even went ahead to create a static block where he used the SDK DynamoDB client to make a put into the database he knew would fail but that would leave the client already initialised for the subsequent calls.
One aspect of Lambda is the way it discovers any variables used by the code. When variables like AWS regions, endpoints and the like are inferred from the context, Lambda needs to parse a very long JSON file to find them. By hard-coding this information, Lambda is able to scratch some more time from the cold start.
Another point he raised was the fact that reflection should be avoided in Lambda as much as possible, the reason being it stopping the JVM from doing any possible optimisation at runtime. Many dependency injection frameworks like Spring or Guice rely on reflection to initialise classes which make them less than desirable in the context of serverless. Thankfully, there is an open source project based on the original Dagger framework from Square and now maintained by Google that ditches reflection in favor of static, compile time dependency injection.
With all these changes in the code, the Lambda function was finally able to pass from a 24ish seconds cold start to less than 6 seconds. As a final note, he exposed what was to come in the world of serverless and Java as a long term solution that could make the language rival others like Python and Node in terms of cold start time. We are talking about the universal virtual machine GraalVM, that allows for the creation of ahead-of-time compiled native images, or frameworks like Quarkus or Micronaut that benefit from GraalVM to provide startups of milliseconds. Using these technologies, he was able to start a Lambda function in less than a second. And for Spring developers he pointed out that, even though Micronaut is compatible with many of the Spring annotations natively, the Spring team is working on its own implementation that would use GraalVM. So, for any Spring developer out there, stay tuned.
Conclusion
Back in 2014 when Lambda was announced, the cold start problem supposed quite a challenge to any developer willing to jump into the wagon of this new technology. For Java developers, the challenge was even greater than for others not running inside the JVM. 5 years later, after the introduction of many new features (the last one, announced during this re:Invent session, the provisioned concurrency feature that allows for a predefined number of Lambda instances of a function to be kept up and running at all times), the numerous improvements done by the AWS team under the hood, the new but fast developed technologies like GraalVM, Quarkus and Micronaut and a little bit of work from the part of developers, it seems like Java still has things to say in the world of serverless.
.png?width=520&height=294&name=Webflux%20image%20(1).png)


Comments