


AWS recently announced the General Availability of AWS Glue Data Quality which aims to deliver high-quality data across your data lakes and existing pipelines. This blog will explore its capabilities and benefits to show how it revolutionizes the way businesses ensure data accuracy and reliability.
What is AWS Glue Data Quality?
AWS Glue Data Quality is a powerful data profiling and data quality solution designed to assist data engineers, data scientists, and analysts in understanding and enhancing data quality across their AWS environments. This new feature complements AWS Glue's existing functionality and further simplifies the process of validating, cleaning, and transforming data.
Key Features and Capabilities
-
Data Profiling: AWS Glue Data Quality empowers users to gain insights into their datasets by providing comprehensive data profiling reports. These reports help identify data inconsistencies, patterns, and anomalies, aiding in the understanding of the data's quality and characteristics
-
Data Quality Checks: The feature allows users to define custom data quality rules and checks based on specific business requirements. These checks can be executed at scale to ensure data accuracy and compliance, thus minimizing the risk of erroneous insights and decision-making
-
Data Cleansing: With AWS Glue Data Quality, organizations can easily clean and standardize their data to eliminate duplicates, missing values, and incorrect entries. This functionality ensures that downstream analytics and applications are built on reliable, high-quality data
-
Integration with AWS Glue ETL: Seamlessly integrate AWS Glue Data Quality with AWS Glue jobs to incorporate data validation and cleansing as part of the data preparation process
Use Cases
-
Retail: Retailers can use AWS Glue Data Quality to validate and cleanse product catalogs, customer information, and sales data to enhance customer experience and optimize inventory management
-
Healthcare: Healthcare organizations can leverage the feature to ensure data accuracy and privacy compliance while analyzing patient records and medical data
-
Financial Services: Financial institutions can benefit from AWS Glue Data Quality in verifying financial data integrity, minimizing errors in transactions, and adhering to regulatory requirements
Rules and alerts setup
Dataset
I decided to create my own dataset using the awesome Python library Faker:
from faker import Faker
import csv
fake = Faker()
# Create CSV with header
with open("person.csv", "w", newline="") as csvfile:
fieldnames = ["name", "birthdate", "ssn", "sex", "mail"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
# Generate 100 rows
for _ in range(100):
p = fake.profile()
writer.writerow(
{
"name": p["name"],
"birthdate": p["birthdate"],
"sex": p["sex"],
"mail": p["mail"],
}
)
After generating the csv and uploading it to S3, I was able to load the data into the Glue Catalog using a regular CSV crawler. For more information on how to use Glue crawlers, I recommend reading the documentation.
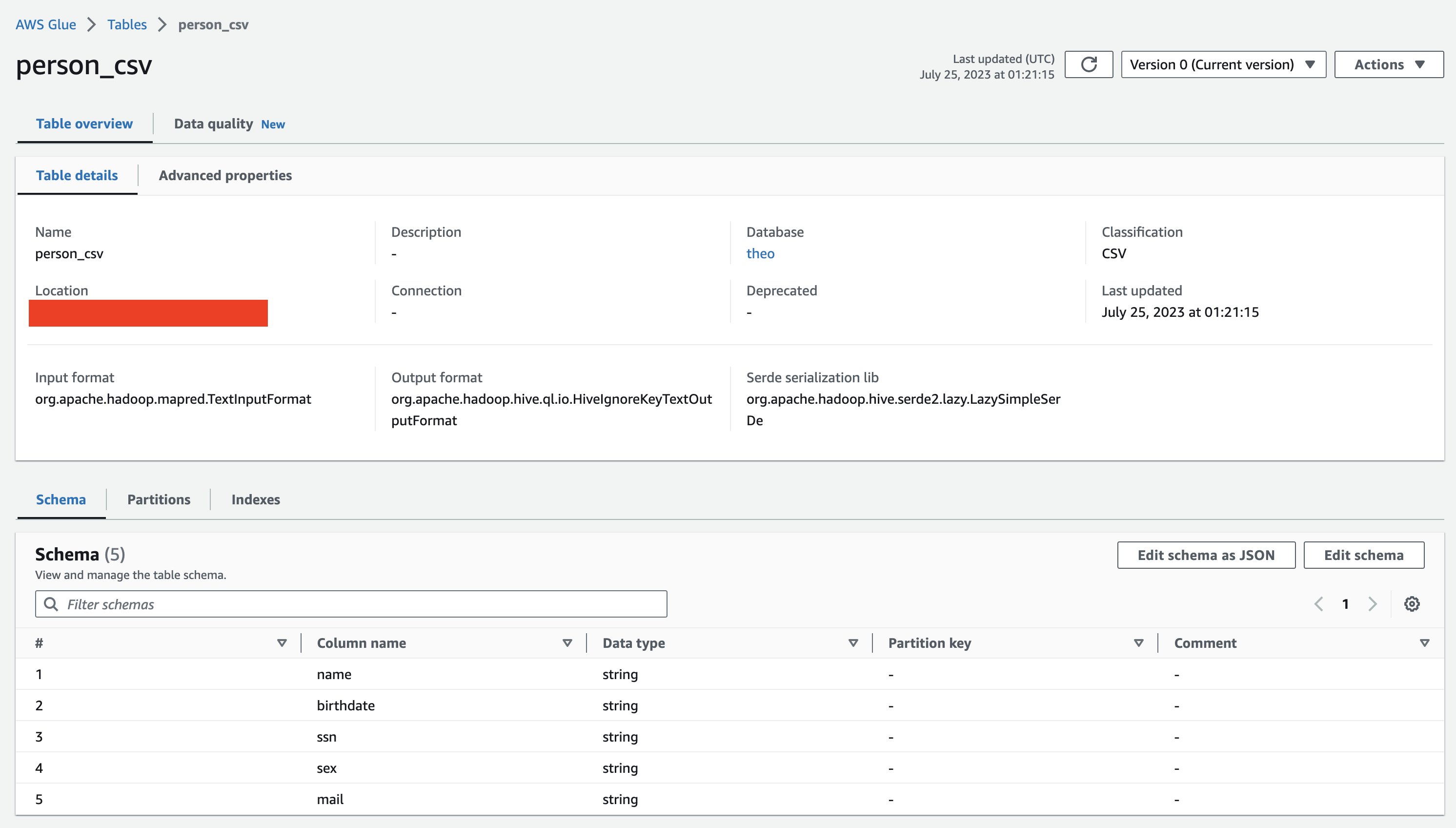
Rules
Now that we have our table, we can create rules through the "Data quality" tab directly in the Glue UI. Glue can also generate a set of recommendations based on your data, this is extremely useful when having a lot of columns. A rule uses a Data Quality Definition Language (DQDL) format to define what will be tested on your table, more details about DQDL here.
Here is what we gonna use for our Person table in a healthcare context:
Rules = [
(IsComplete "name") and (Uniqueness "name" > 0.95),
(IsComplete "birthdate") and (ColumnLength "birthdate" = 10),
ColumnLength "ssn" = 0,
IsComplete "sex",
IsComplete "mail",
CustomSql "select count(*) from primary where date(birthdate) > current_date" = 0
]
Each column (except the SSN one) are checked to make sure that it's not NULL using the IsComplete rule. The rule CustomSql is very powerful and allows us to run any query on our dataset. Here it is used to make sure that birthdate is not a future date.
After running the rule, we can see that two rules failed:
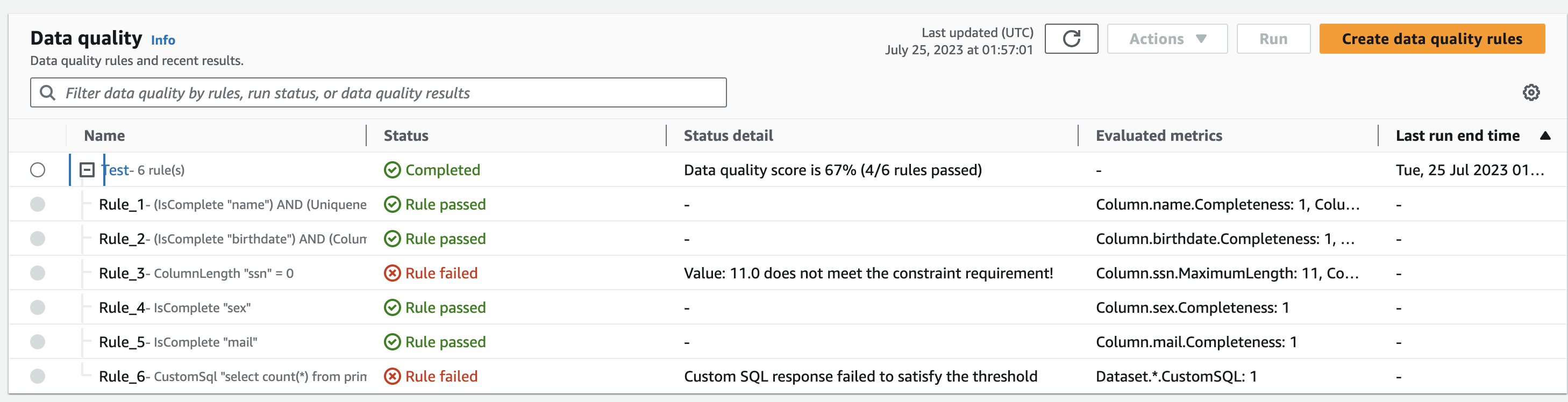
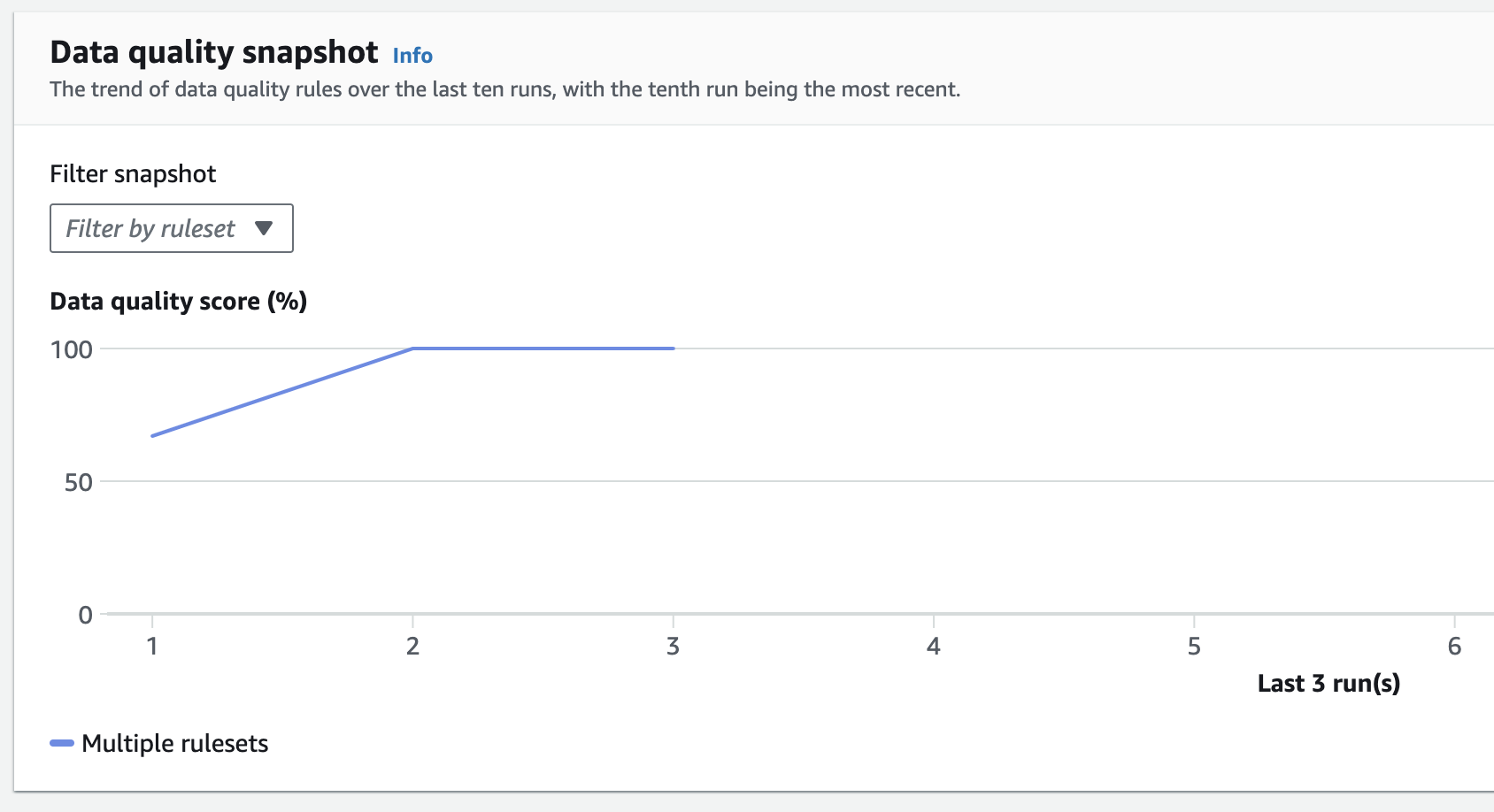
This is normal as I deliberately added an SSN and a future date of birth in the dataset to have it fails the data quality checks. After cleaning up the data and rerunning the CSV crawler, everything is green, and we can actually see the quality score increasing to 100% on the data quality chart:
Alerts
When running the rule, I recommend using Amazon Simple Storage Service (Amazon S3) to store the output of the run. Then a simple EventBridge rule can be created to trigger a Lambda when a file is created at the correct S3 location. The lambda will parse the JSON output and then perform any kind of alerting (email, PagerDuty, etc) based on your Organization's alerting system.
For a more detailed implementation, I suggest reading this series of blogs from the AWS team.
Conclusion
AWS Glue Data Quality introduces a new era of data integrity, offering organizations a comprehensive solution to validate, cleanse, and maintain high-quality data in their AWS environments. By empowering data professionals to make informed decisions based on reliable data, AWS Glue Data Quality becomes an indispensable tool in driving successful data-driven strategies for businesses across diverse industries.
Need help with your existing data lake? Or do you need help using AWS Glue? Ippon can help! Send us a line at contact@ippon.tech.




Comments