

Intro
DevOps Engineers have moved from on-premise, monolithic applications to large-scale application systems in the cloud. One of the most popular orchestration systems currently being used in production across the board is Kubernetes (K8s, for short) under the covers. I want to share some knowledge I have gathered over the years and break down what K8s does at its core. An understanding of the K8s core construction will allow you to understand how new features are constructed for K8s and how these basic functions ensure a more stable operating environment.
Kubernetes is an open-source project on GitHub. They define their project as:
Kubernetes, also known as K8s, is an open source system for managing containerized applications across multiple hosts. It provides basic mechanisms for deployment, maintenance, and scaling of applications.
Application Deployment
To understand Kubernetes, I believe it is helpful to look at and compare how production applications have been deployed in the past and compare that what K8s brings to the table in the present. First, let's consider our first legacy setup. At company "ABC," there are a couple of servers in a physical data center on the company's real estate somewhere to host our applications. Let's say we size our production servers to match our expected user base and concurrent usage. In our example, we have four discrete business applications: Green, Orange, Teal, and Blue. Now let's say all of these applications share a network, database, and load balancer with each other. We also have a couple of spare servers allocated in the event of a disaster recovery.
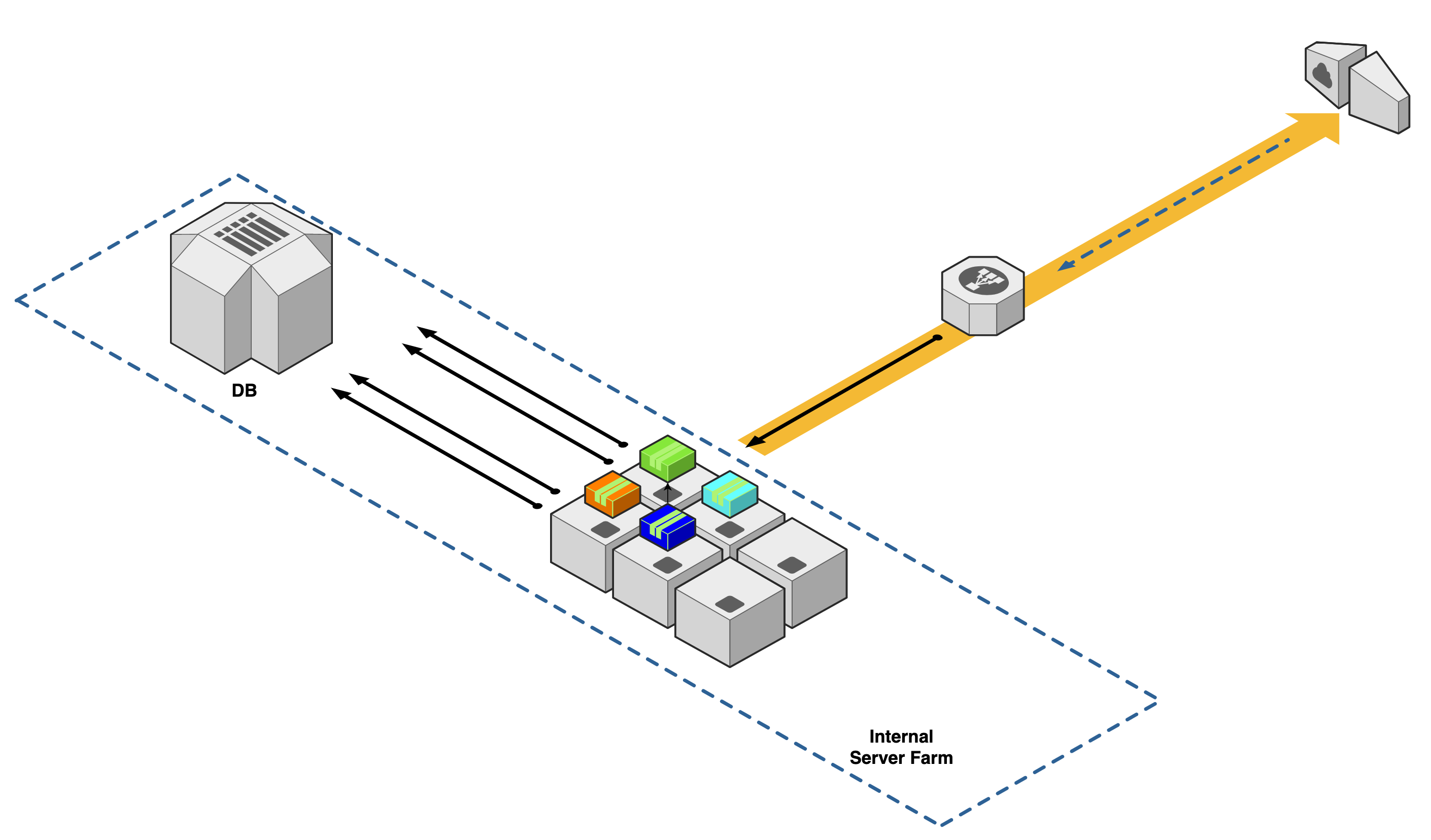
Simulating a Disaster
We have a scenario where an IT network operations center gets alerted about an outage in application "Blue." An electrical storm came through the night before and shorted the hardware on the server. Because of the outage, IT determines that they will need to move the application to one of the spare servers.
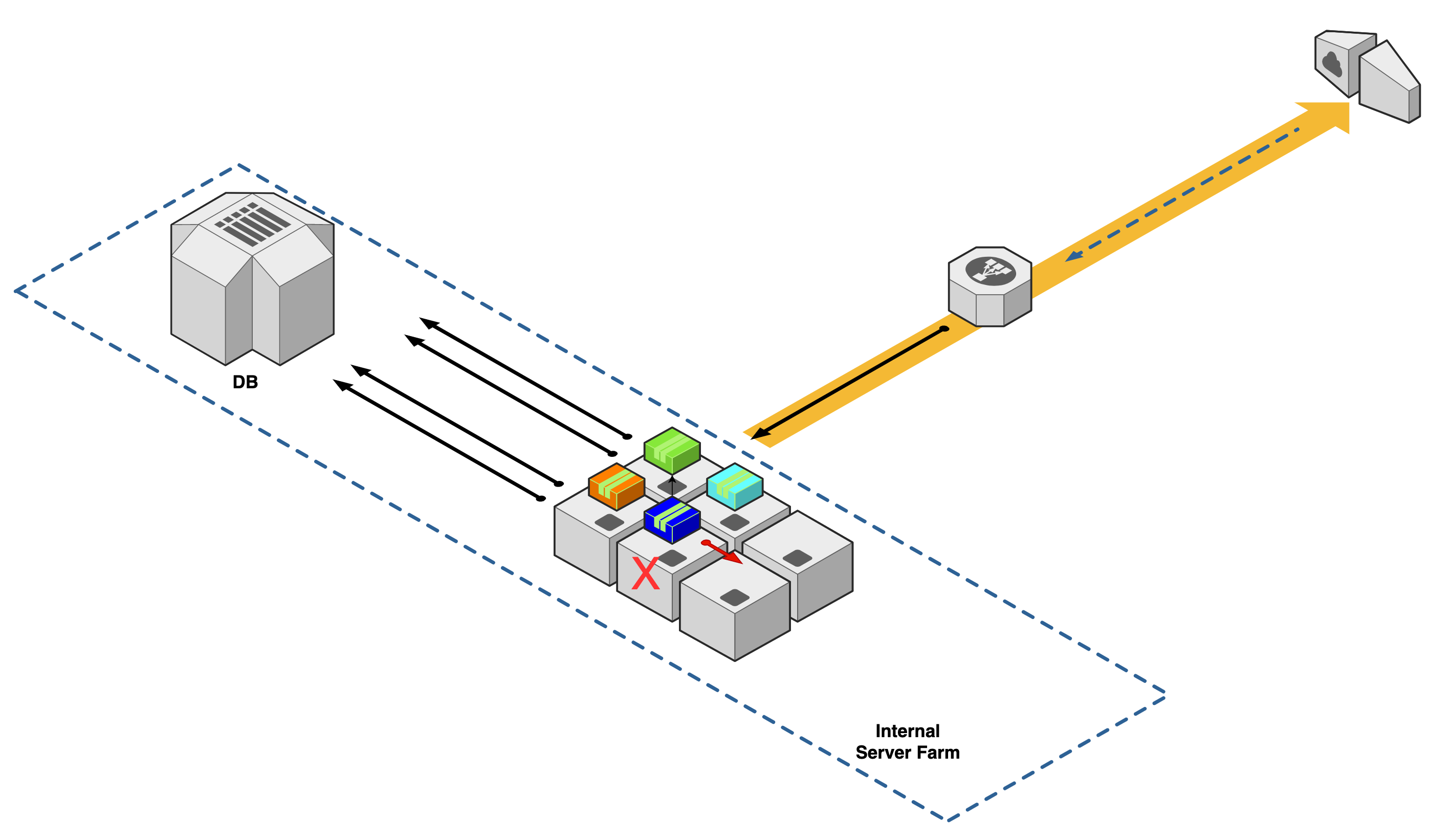
During this outage, IT will be scrambling to bring one of the spare servers online. In addition, they will have to configure access to the shared database and network load balancer, and allow firewall rules for the application to run on the new server. Each of these tasks can be time-consuming if not planned for ahead of time or have had repeated dry runs to ensure that they can be done issue-free.
In our example, each application cannot recover from a single machine failure. Recovery from said disaster will bring outage times and take IT time to perform investigation and recovery. Naturally, we would ask how can our environment be setup such that our application can recover from this scenario?
Breakdown
Losing one machine means having to manually recover. There are many ways to make your recovery time more efficient in this scenario. For instance, install equipment to protect against electrical storm damage or establishing a process to build and test a DR plan in case of such disaster. These types of protections will not necessarily change the underlying issue, which is single machine recovery. Another method used on-premises is to have one hot machine and one cold machine. The hot machine is used until an issue arises, whereas the cold machine is switched on in case backup is necessary. You can now recover from a single failure, but you have only moved the bar one tick and still would not be able to recover from a two machine failure. Ideally, we want to be able to recover from any and all machine failures.
In order to achieve this, Kubernetes changes the way we deploy applications. Instead of having dedicated hardware and manual deployment processes, our applications now have automated deployments and containerized applications.
Kubernetes is one of many options that enable this type of functionality by creating a distributed cluster of machines that all work together to host deployed applications.
Cluster Communication
The way Kubernetes operates is to have a pool of machines ready for any application to be deployed onto them. The machines communicate by having the same Kubelet application installed on all said machines. The Kubelet has the responsibility of managing the node its installed on and communicating to the controller nodes. It has the system permissions to start and stop containers, mount and unmount volumes, and open and close ports etc. Essentially it is in charge of listening for commands sent from the controller nodes and executing the commands sent. This enables each node in the cluster to be orchestrated as a group of machines, otherwise known as a cluster.
Visualizing Kubernetes
Let's go back to company "ABC" with their four application deployments. We convert our production deployment operations to Kubernetes -- first by installing a Kubelet onto all of our agent nodes.
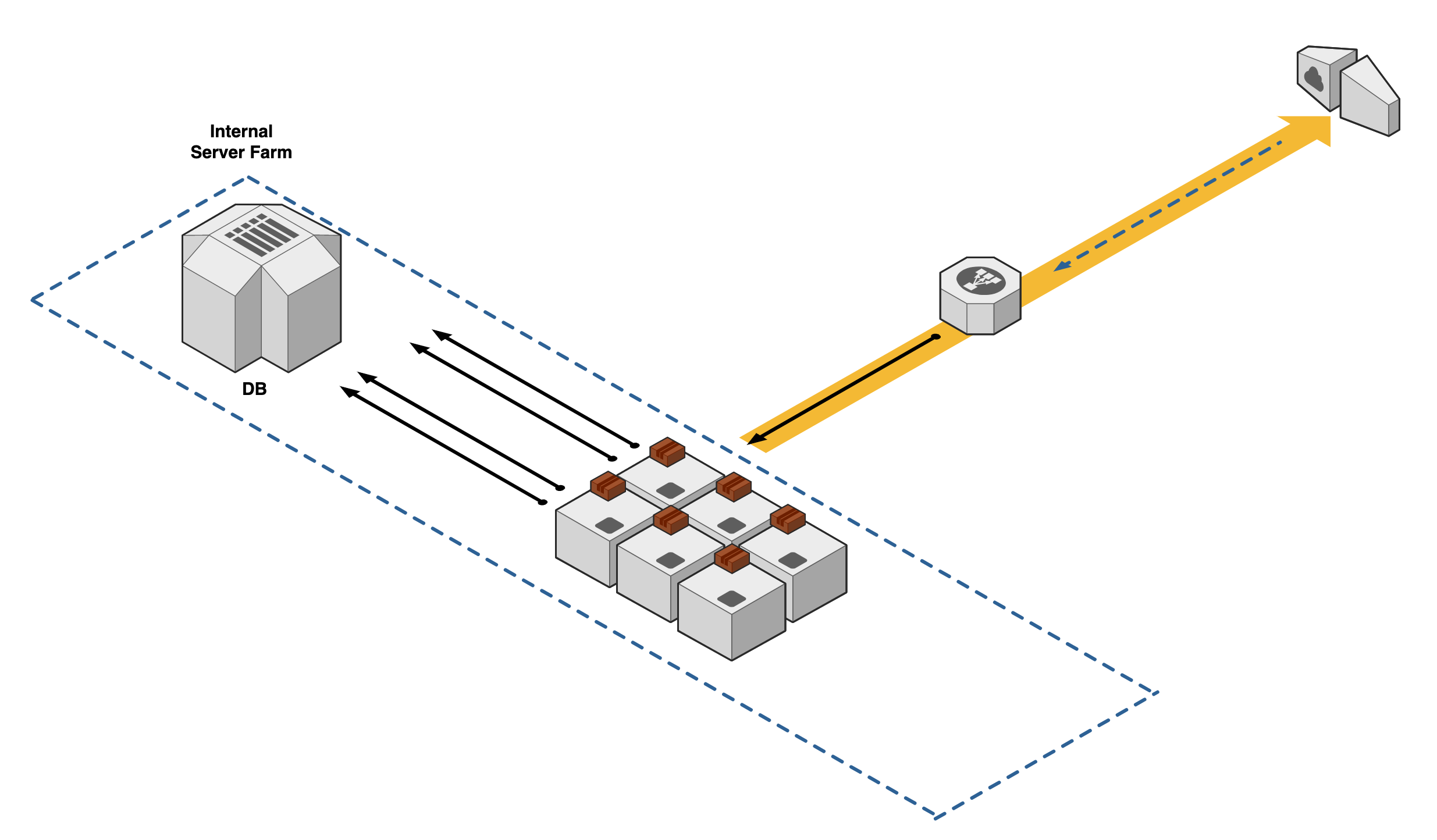
Next, we segment three machines to be controllers that will be in charge of maintaining communications with all the agent nodes and checking the health of the cluster configuration.
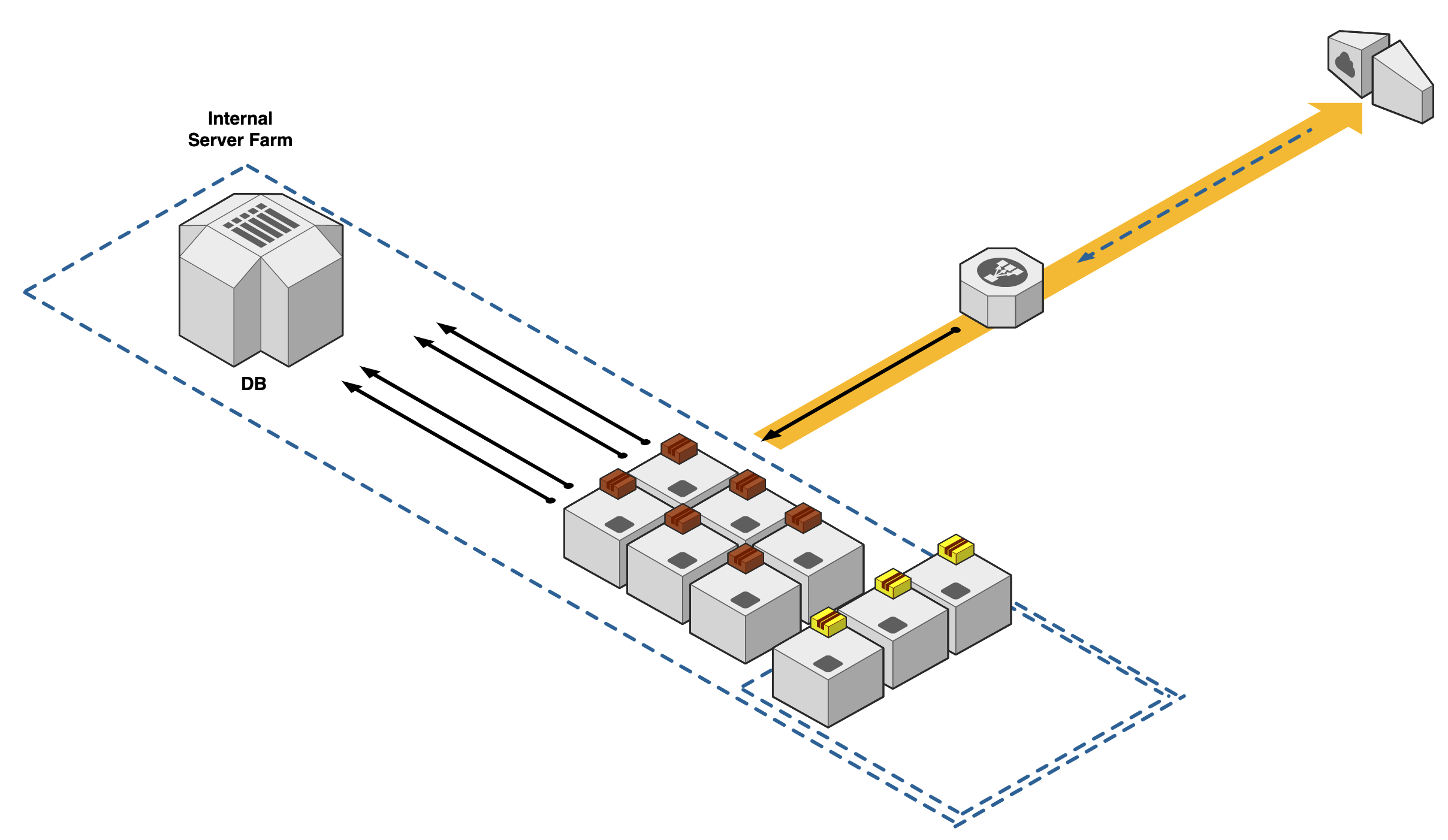
We then define our application deployments as "plans". The "Plans" are defined by Kubenetes configuration YAML files. These configuration files can configure many different aspects like resource sizes, network settings, and health checks. These plans get communicated to our agent nodes for deployment on all active machines.
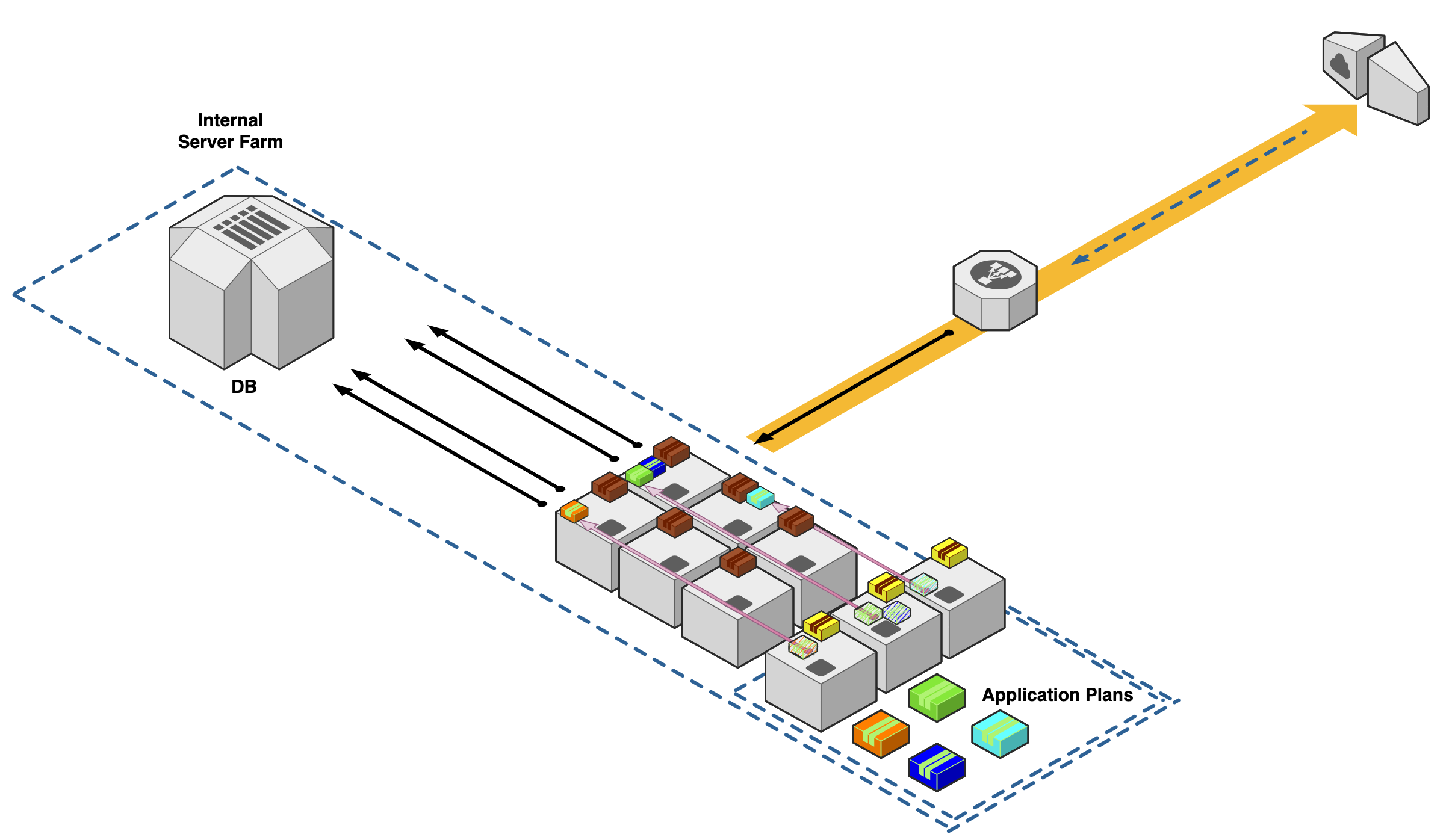
If we repeat our disaster scenario from before and one of our machines in our agent pool is taken offline, our controllers can now assess the health of this application automatically and redeploy our application onto the next available node.
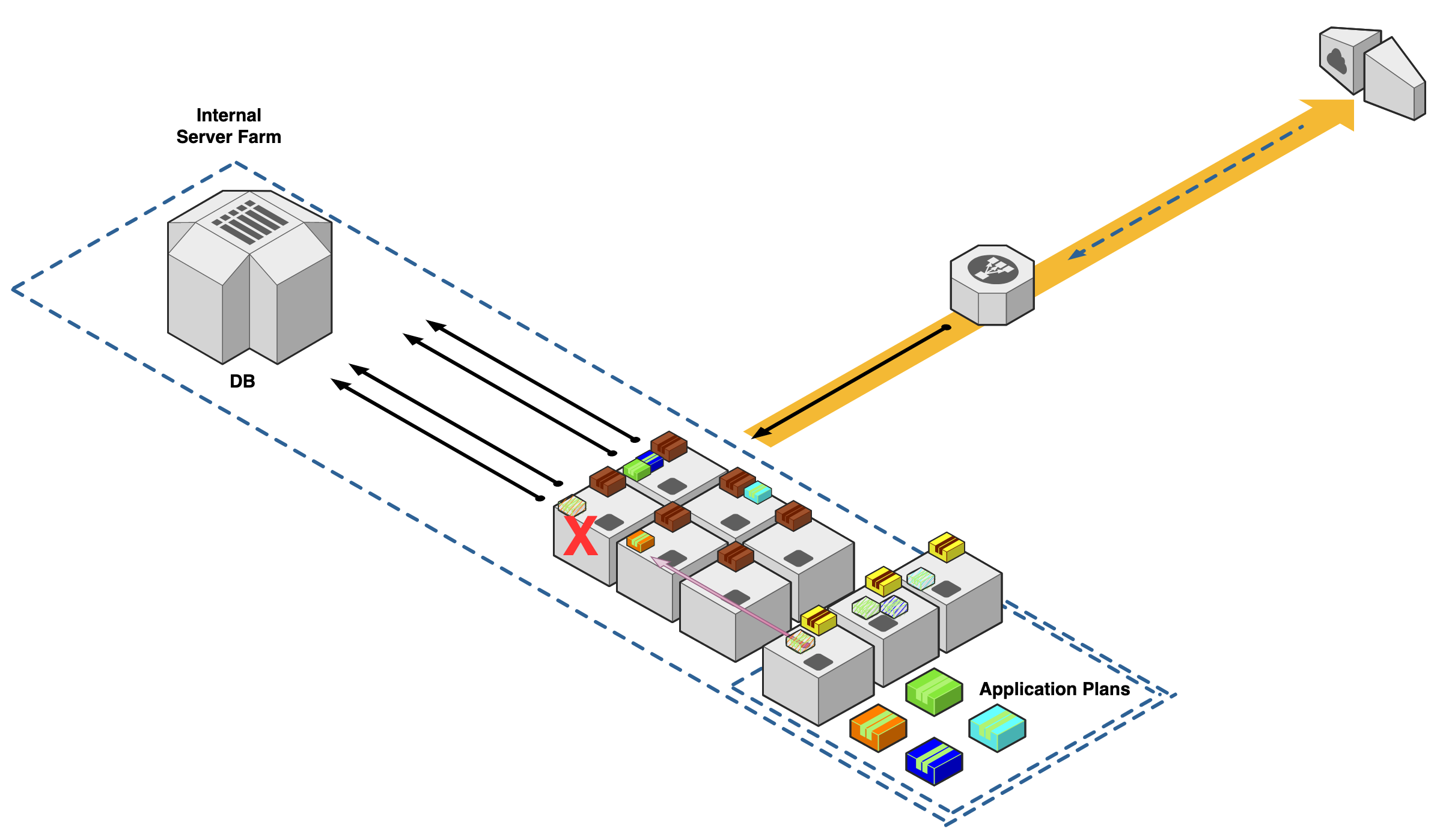
Summary
Using Kubernetes enables many exciting new features for us DevOps Engineers. These functionalities are enabled by how we form our operational environment like I demonstrated above. By using a cluster of machines, we can achieve high availability. This change in deployment method allows our application deployments to withstand x-number of machine failures where "y" is the size of your cluster.
This high level overview of how clusters are formed and maintained should contribute to your understanding of complexities within larger orchestration systems.
Here at Ippon, we have experience with designing resilient large-scale application architectures. We do this by following the newest open-source tools and best practices within the tech community. If you are designing your next system or are in charge of a Kubernetes cluster and in need of professional guidance, feel free to contact me on LinkedIn or send us over a message.




Comments