

When you start doing some Machine Learning, you go through a batch-oriented process: you take a dataset, build a Machine Learning model from this data, and use the model to make some predictions on another dataset. Then, you want to apply this process to streaming data, and this is where it can get confusing! Let's see what you can do in streaming and what you cannot do.
Looking at a use case
To illustrate this article, let's take one of the most common use cases of Machine Learning: estimating prices of real estate (just like Zillow does). You have a dataset of past observations, with the characteristics and the selling price of some houses:
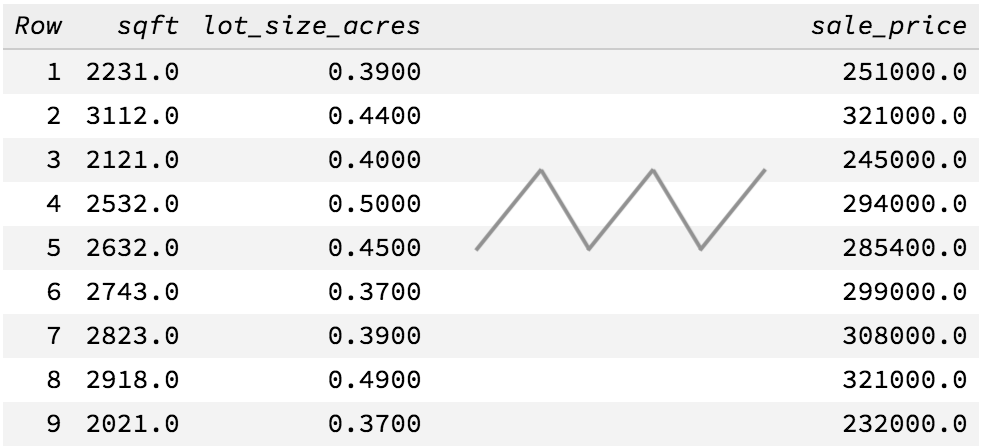
You can build a regression model so that, when there is a new house to sell, you can estimate what the selling price will be, e.g. a house of 2000 sqft with a lot of 0.5 acres might sell around $250,000.
The first mistake people make is to think we can update the model when we receive a new house to sell. We can't, because the new piece of data is an unlabeled record: we know the characteristics of the house, but we don't know its selling price (yet). It is only once the house has been sold that we can enrich our training dataset with a new record.
The second usual mistake is to think we should update the model every time we have a new labeled record (a house was sold and we know its selling price). Well, we could, but it is probably not a good idea to do so. Training a model may require doing some cross-validation, going through a grid-search to optimize our parameters, and we may even try multiple algorithms. All of this is makes the process very resource-intensive. It is also a good idea to have a human verify that the model performs as expected before using it in production. And who knows, the real estate market may be going through a bubble, and you may want to refine your dataset to only keep the last 3 months of data.
Basically, what I am trying to say is that your Data Scientist should decide when to update the model.
More generally speaking, when you update your model incrementaly, i.e. as you receive new training examples, we talk about Online Machine Learning. However, few algorithms allow that.
Looking at technologies
To recap the point above:
- The training process should be done in batch, from time to time, with a fixed dataset, and will produce a model.
- A streaming application can use the model (without updating it), and we may need to update the application when a new model is produced.
Let's look at some popular Machine Learning toolkits:
- scikit-learn and Tensorflow: two popular Python libraries.
- Spark ML: a library built on top of Apache Spark.
- cloud-hosted Machine Learning services, such as Google Cloud Machine Learning Engine or AWS SageMaker.
- H2O.ai: a mostly-Java based platform.
These are all great options to build a ML model, but let's say you want to use the model to make some predictions in realtime, as events arrive in Kafka, and your application is Java-based:
- scikit-learn and Tensorflow: since these are Python libraries, your best bet is to expose the model on a REST API, and call the API from your Java application. Serving the model - and potentially scaling it - requires some work, though.
- Spark ML: you will most likely have to use Spark Streaming, which comes with its set of challenges (high latency, complexity when updating an application, etc.).
- Cloud-hosted services: these are API-based, and therefore very easy to integrate, but latency might be too high if you need to make your predictions with a very low-latency.
- H2O.ai: this platform allows you to download the model as a POJO (a Java class) that you can integrate in your application. This is what we are going to use in this post.
Creating a ML model with H2O
H2O.ai is an open-source platform for Machine Learning, and the company behind it also offers paid support as well as paid products enterprise products. In this post, we are going to use the free product.
I am not going to explain how to use the H2O platform, and show how to build a model. Instead, follow this Quick Start Tutorial For Just About Anyone. In this tutorial, the author uses the data I showed above, and builds a model with the gradient boosting machine algorithm. You should get something like this:
Go ahead and click on "Download POJO" to get a Java file that looks like this:
Using the model in a Java application
Now, let's use our model in a Java application (we're actually going to use Kotlin, but this is a JVM-based application).
Start by creating a project, then put the POJO you downloaded earlier under the src/main/java/ directory. By default, the model belongs to the root package, which is not great, so let's move it to another package. I moved the class to the com.ippontech.kafkah2o package:
We are going to use H2O's Gen Model library to interact with the model, so let's add a dependency in our Gradle build:
dependencies {
compile 'ai.h2o:h2o-genmodel:3.20.0.6'
// other dependencies...
}
(Make sure to use the version that matches your H2O installation.)
We can now load our model, prepare a record, then make a prediction:
fun main(args: Array<String>) {
val rawModel = gbm_2760b04d_9dfd_436c_b780_7bdb2f372d85()
val model = EasyPredictModelWrapper(rawModel)
val row = RowData().apply {
put("sqft", 2342.0)
put("lot_size_acres", 0.4)
put("stories", 1.0)
put("number_bedrooms", 3.0)
put("number_bathrooms", 3.0)
put("attached_garage", "yes")
put("has_pool", "no")
put("has_kitchen_island", "yes")
put("main_flooring_type", "hardwood")
put("has_granite_counters", "yes")
put("house_age_years", 4.0)
}
val prediction = model.predictRegression(row)
println("Prediction: \$${prediction.value}")
}
If we run this code, we get something like:
Prediction: $290591.70578645257
Great, we just used our Machine Learning model in a standalone application!
Using the model in a Kafka Streams application
I put together a basic producer that pushes unlabeled records to a Kafka topic called housing. The data is in JSON:
$ kafka-console-consumer --bootstrap-server localhost:9092 --topic housing
{"sqft":2572,"lot_size_acres":0.2318716,"stories":2,"number_bedrooms":1,"number_bathrooms":0,"attached_garage":false,"has_pool":true,"has_kitchen_island":true,"main_flooring_type":"hardwood","has_granite_counters":false,"house_age_years":18}
{"sqft":1256,"lot_size_acres":0.774486,"stories":2,"number_bedrooms":1,"number_bathrooms":2,"attached_garage":false,"has_pool":false,"has_kitchen_island":true,"main_flooring_type":"hardwood","has_granite_counters":false,"house_age_years":3}
{"sqft":2375,"lot_size_acres":0.7467226,"stories":2,"number_bedrooms":4,"number_bathrooms":0,"attached_garage":false,"has_pool":true,"has_kitchen_island":false,"main_flooring_type":"hardwood","has_granite_counters":true,"house_age_years":3}
...
We are going to build a Kafka Streams application to process this stream and make predictions as new records arrive.
The first step is to create a model for our data. We are using a Kotlin data class:
@JsonInclude(Include.NON_NULL)
data class House(
val sqft: Int,
val lot_size_acres: Float,
val stories: Int,
val number_bedrooms: Int,
val number_bathrooms: Int,
val attached_garage: Boolean,
val has_pool: Boolean,
val has_kitchen_island: Boolean,
val main_flooring_type: String,
val has_granite_counters: Boolean,
val house_age_years: Int,
val selling_price: Int? = null)
The selling_price property is the value we will predict. We will use it when we output predictions to another Kafka topic.
We can now read the data from the input topic into a KStream<String, House>:
val streamsBuilder = StreamsBuilder()
val housesStream: KStream<String, House> = streamsBuilder
.stream("housing", Consumed.with(Serdes.String(), Serdes.String()))
.mapValues { v -> jsonMapper.readValue(v, House::class.java) }
Now, all we have to do to make predictions is to fill in a RowData object, making sure all the numeric values are of type Double, and booleans are either yes or no:
val predictionsStream: KStream<String, House> = housesStream.mapValues { _, h ->
val row = RowData().apply {
put("sqft", h.sqft.toDouble())
put("lot_size_acres", h.lot_size_acres.toDouble())
put("stories", h.stories.toDouble())
put("number_bedrooms", h.number_bedrooms.toDouble())
put("number_bathrooms", h.number_bathrooms.toDouble())
put("attached_garage", h.attached_garage)
put("has_pool", h.has_pool.toYesNo())
put("has_kitchen_island", h.has_kitchen_island.toYesNo())
put("main_flooring_type", h.main_flooring_type)
put("has_granite_counters", h.has_granite_counters.toYesNo())
put("house_age_years", h.house_age_years.toDouble())
}
val prediction = model.predictRegression(row).value.toInt()
h.copy(selling_price = prediction)
}
Notice that I used a Kotlin extension function to convert booleans:
fun Boolean.toYesNo(): String = when (this) {
true -> "yes"
else -> "no"
}
I also kept the model as a member variable to avoid instantiating it multiple times:
private val rawModel = gbm_2760b04d_9dfd_436c_b780_7bdb2f372d85()
private val model = EasyPredictModelWrapper(rawModel)
We can finally write the KStream back to a Kafka topic:
predictionsStream
.mapValues { _, p -> jsonMapper.writeValueAsString(p) }
.to("predictions", Produced.with(Serdes.String(), Serdes.String()))
Now, if we look at the output topic, we can see the input data enhanced with predicted selling prices:
$ kafka-console-consumer --bootstrap-server localhost:9092 --topic predictions
{"sqft":2572,"lot_size_acres":0.2318716,...,"selling_price":297625}
{"sqft":1256,"lot_size_acres":0.774486,...,"selling_price":254118}
{"sqft":2375,"lot_size_acres":0.7467226,...,"selling_price":303408}
...
Conclusion
We saw in this post how we can embed a Machine Learning model in a Kafka Streams application. The model was built outside of the streaming pipeline, and the generated POJO was completely independant from the platform where the model was trained.
There are pros and cons to embedding a model in your application, as opposed to serving a model through an API:
- pros:
- predictions are made with very low latency
- no external dependency, making it a very robust deployment model
- cons:
- harder to update the model: you have to update the application as well
- A/B testing of different models is also more difficult.
Hopefully this article lifts some interrogations about how to use Machine Learning in streaming. Let me know if it helped!
The code used in this post can be found here.




Comments