

Do you have a Spark-Job which runs every day? Do you manually create and shut down an EMR Cluster? Do you continuously monitor its runtime, check for output in an S3 bucket and then report status in an email? Have you ever thought of automating this process? If yes, then this is the post you have to look into.
This post demonstrates a cost-effective and automated solution for running Spark-Jobs on the EMR cluster on a daily basis using CloudWatch, Lambda, EMR, S3, and SNS.
Architectural Diagram
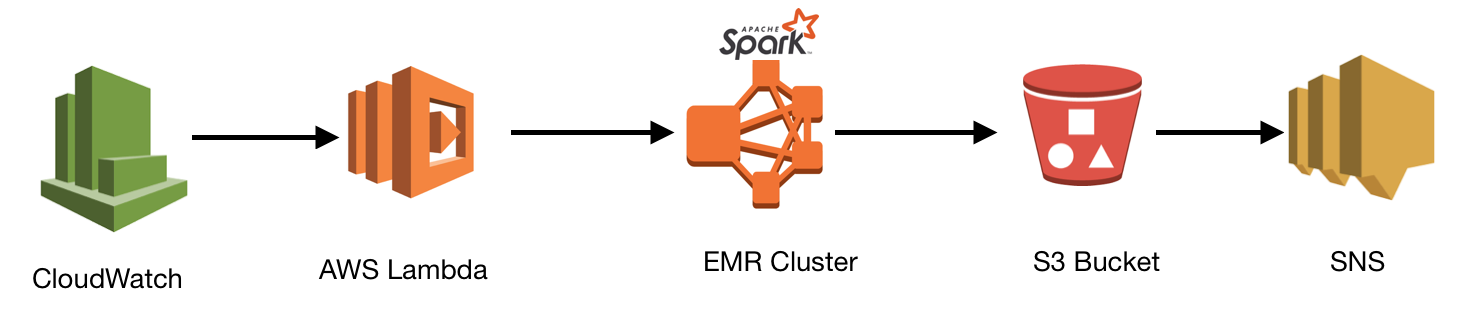
Design shows the following steps:
- Cloudwatch rule triggers the lambda function once every day, as the time specified in the rule.
- Lambda function creates the EMR cluster, executes the spark step and stores the resultant file in the s3 location as specified in the spark and shuts down.
- As soon as the file lands in the s3 location, an email notification is sent to the subscribers using SNS.
Step 1: IAM Policy and Role
Create a policy with the permissions as shown below. Create a new role and add this policy to the new role.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"iam:*",
"sns:*",
"application-autoscaling:*",
"clouddirectory:*",
"s3:*",
"logs:*",
"elasticmapreduce:*",
"autoscaling-plans:*"
],
"Resource": "*"
},
{
"Action": "iam:PassRole",
"Resource": [
"arn:aws:iam::655583618505:role/IAM_ROLE_EMR"
],
"Effect": "Allow",
"Sid": "Pass"
}
]
}
Step 2: EMR and Lambda
There are two kinds of EMR clusters: transient and long-running. If you configure your cluster to be automatically terminated, it is terminated after all the steps complete. This is referred to as a transient cluster. If you configure the cluster to continue running after processing completes, this is referred to as long-running. Long-running will allow you to interact with the cluster after processing but will require manual shutdown . As my goal is to create an automated and cost-efficient EMR cluster, the transient cluster option will be used. To achieve this, set the 'AutoTerminate' attribute as 'True' and the cluster will shut down as soon as the Spark-Job completes processing.
There are three types of nodes in EMR: Master, Core, and Task. There are also two types of instances: ON_DEMAND(always available and expensive) and SPOT(not always available, and one has to bid, but cheap). When it comes to choosing instance types for these nodes, I always prefer the ON_DEMAND type for the Master node, as there is always only one master node and it acts as the name node and job tracker. I opt for the SPOT type for core and task nodes in transient clusters.
Create a Lambda function called ‘Emr-Spark’, select existing IAM role and add the role which has been created in step 1. Write the following python code:
import json
import boto3
import datetime
def lambda_handler(event, context):
print("Creating EMR")
connection = boto3.client('emr', region_name='us-east-1')
print(event)
cluster_id = connection.run_job_flow(
Name='Emr_Spark',
LogUri='s3://sparkuser/emr/logs',
ReleaseLabel='emr-5.21.0',
Applications=[
{'Name': 'Hadoop'},
{'Name': 'Hive'},
{'Name': 'Spark'}
],
Instances={
'InstanceGroups': [
{
'Name': 'Master nodes',
'Market': 'ON_DEMAND',
'InstanceRole': 'MASTER',
'InstanceType': 'r4.8xlarge',
'InstanceCount': 1,
'EbsConfiguration': {
'EbsBlockDeviceConfigs': [
{
'VolumeSpecification':{
'VolumeType': 'gp2',
'SizeInGB': 400
},
'VolumesPerInstance': 2
},
],
'EbsOptimized': True,
}
},
{
'Name': 'Slave nodes',
'Market': 'SPOT',
'InstanceRole': 'CORE',
'InstanceType': 'r4.8xlarge',
'InstanceCount': 1,
'EbsConfiguration': {
'EbsBlockDeviceConfigs': [
{
'VolumeSpecification': {
'VolumeType': 'gp2',
'SizeInGB': 500
},
'VolumesPerInstance': 2
},
],
'EbsOptimized': True,
},
'AutoScalingPolicy': {
'Constraints': {
'MinCapacity': 2,
'MaxCapacity': 20
},
'Rules': [
{
'Name': 'Compute-scale-up',
'Description': 'scale up on YARNMemory',
'Action': {
'SimpleScalingPolicyConfiguration': {
'AdjustmentType': 'CHANGE_IN_CAPACITY',
'ScalingAdjustment': 1,
'CoolDown': 300
}
},
'Trigger': {
'CloudWatchAlarmDefinition' :{
'ComparisonOperator': 'LESS_THAN',
'EvaluationPeriods': 120,
'MetricName': 'YARNMemoryAvailablePercentage',
'Namespace': 'AWS/ElasticMapReduce',
'Period': 300,
'Statistic': 'AVERAGE',
'Threshold': 20,
'Unit': 'PERCENT'
}
}
},
{
'Name': 'Compute-scale-down',
'Description':'scale down on YARNMemory',
'Action': {
'SimpleScalingPolicyConfiguration' : {
'AdjustmentType': 'CHANGE_IN_CAPACITY',
'ScalingAdjustment': -1,
'CoolDown': 300
}
},
'Trigger':{
'CloudWatchAlarmDefinition': {
'ComparisonOperator': 'LESS_THAN',
'EvaluationPeriods': 125,
'MetricName': 'YARNMemoryAvailablePercentage',
'Namespace': 'AWS/ElasticMapReduce',
'Period': 250,
'Statistic': 'AVERAGE',
'Threshold': 85,
'Unit': 'PERCENT'
}
}
}
]
}
}
],
'KeepJobFlowAliveWhenNoSteps': True,
'TerminationProtected': True,
'AutoTerminate': True,
'Ec2KeyName': 'test',
'Ec2SubnetId': 'subnet-0198a20fbd7c5f549',
'EmrManagedMasterSecurityGroup': 'sg-0141dee2ca266f83b',
'EmrManagedSlaveSecurityGroup': 'sg-072d020138130e430'
},
Steps=[
{
'Name': 'spark-submit',
'ActionOnFailure': 'TERMINATE_CLUSTER',
'HadoopJarStep': {
'Jar': 's3://sparkuser/jar/example.jar',
'Args': [
'spark-submit','--executor-memory', '1g', '--driver-memory', '500mb',
'--class', 'spark.exercise_1'
]
}
}
],
AutoScalingRole='EMR_AutoScaling_DefaultRole',
VisibleToAllUsers=True,
JobFlowRole='EMR_EC2_DefaultRole',
ServiceRole= 'EMR_DefaultRole',
EbsRootVolumeSize=100,
Tags=[
{
'Key': 'NAME',
'Value': 'Emr_Spark',
},
],
)
print (cluster_id['JobFlowId'])
Code Breakdown:
LogUri - The path to the Amazon S3 location where logs for this cluster are stored.
Applications - The applications installed on this cluster. Hadoop, Hive, and Spark have been chosen here. There are other applications available such as Pig, Oozie, Zookeeper, etc.
Instances - Describes the Amazon EC2 instances of the job flow.
InstanceGroups - This represents an instance group, which is a group of instances that have a common purpose. For example, the CORE instance group is used for HDFS.
Market - The marketplace to provision instances for this group. Valid values are ON_DEMAND or SPOT. ON_DEMAND type for Master and SPOT type is considered here.
AutoScalingPolicy - An automatic scaling policy for a core instance group or task instance group in an Amazon EMR cluster. The automatic scaling policy defines how an instance group dynamically adds and terminates EC2 instances in response to the value of a CloudWatch metric.
CloudWatchAlarmDefinition - The definition of a CloudWatch metric alarm. When the defined alarm conditions are met along with other trigger parameters, scaling activity begins.
AutoTerminate - Specifies whether the cluster should terminate after completing all steps.
TerminationProtected - Indicates whether Amazon EMR will lock the cluster to prevent the EC2 instances from being terminated by an API call or user intervention, or in the event of a cluster error.
JobFlowRole - Also called instance profile and EC2 role. An IAM role for an EMR cluster. The EC2 instances of the cluster assume this role. The default role is EMR_EC2_DefaultRole.
ServiceRole - The IAM role that will be assumed by the Amazon EMR service to access AWS resources on your behalf.
Step 3: Spark
The spark-submit step executes once the EMR cluster is created. Create a jar file for your program using any IDE and place the jar file in S3 bucket. the Spark program is written in Scala and bundled into a jar file using IntelliJ. The final result of the program is also written to the S3 bucket.
In spark-submit, the jar file and all required arguments- driver memory, executor memory, and class name, are mentioned. Input path and the output path can also be added as arguments in the spark-job.
The following are the actions to take when the cluster step fails. Possible values are TERMINATE_CLUSTER, CANCEL_AND_WAIT, and CONTINUE. TERMINATE_JOB_FLOW is provided for backward compatibility. It is recommended to use TERMINATE_CLUSTER instead.
Steps=[
{
'Name': 'spark-submit',
'ActionOnFailure': 'TERMINATE_CLUSTER',
'HadoopJarStep': {
'Jar': 's3://sparkuser/jar/example.jar',
'Args': [
'spark-submit','--executor-memory', '1g', '--driver-memory', '500mb',
'--class', 'spark.exercise_1'
]
}
}
]
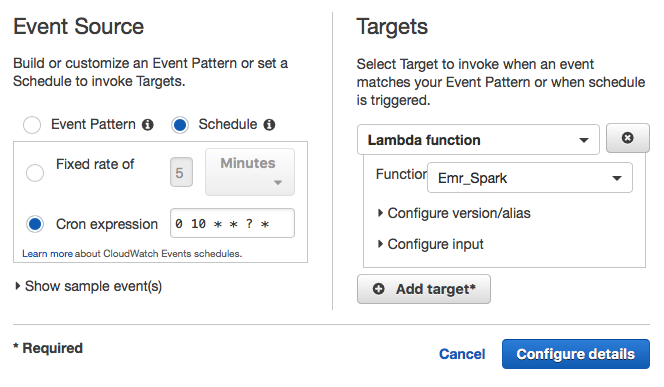
Step 4 : Cloudwatch
Create a rule in CloudWatch using the following command. Mention the name of the rule(Ex: DailyLambdaFunctin) and schedule time(Ex: 0 10 * * ? * Run at 10.00 am UTC every day ).
aws events put-rule --name "DailyLambdaFunction" --schedule expression "cron(0 10 * * ? *)"
In the targets section, under the Lambda function, select the name of the Lambda function which will be triggered by CloudWatch. In our case, it is ‘Emr_Spark,’ as shown below.
Step 5: SNS and S3
Topic is created in SNS and subscriptions, email addresses, are added with a message to the topic.
aws sns create-topic --name Emr_Spark
The access policy for SNS topic to access S3 bucket:
{
"Version": "2008-10-17",
"Id": "__default_policy_ID",
"Statement": [
{
"Sid": "s3-event-notifier",
"Effect": "Allow",
"Principal": {
"Service": "s3.amazonaws.com"
},
"Action": "SNS:Publish",
"Resource": "arn:aws:sns:us-east-1:Topic_name",
"Condition": {
"ArnLike": {
"AWS:SourceArn": "arn:aws:s3:*:*:bucket_name"
}
}
}
]
}
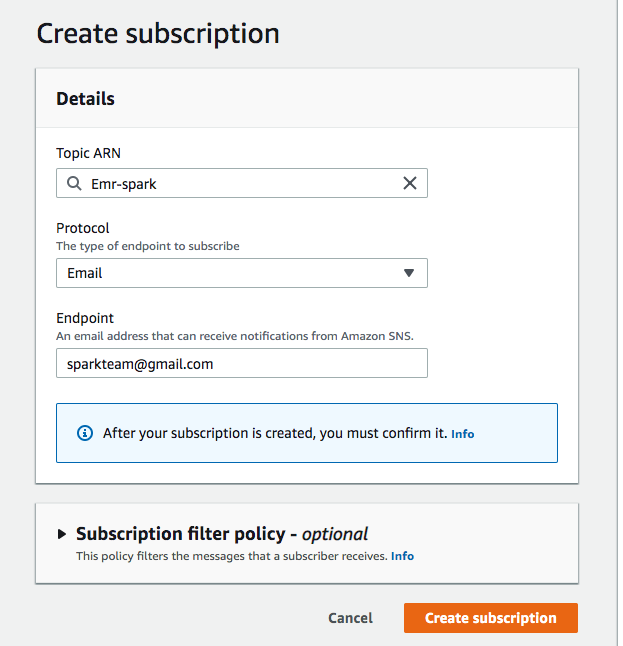
Create an s3 bucket, sparkuser, and add the event trigger for the SNS topic. As soon as the file or object lands in this s3 bucket, an SNS notification is sent to subscribers.
aws s3api put-bucket-notification-configuration --bucket sparkuser --notification-configuration file://notification.json
The file notification.json is a JSON document in the current folder that specifies an SNS topic and an event type to monitor.
{
"TopicConfigurations": [
{
"TopicArn": "arn:aws:sns:us-east-1:s3-Topic_name",
"Events": [
"s3:ObjectCreated:*"
]
}
]
}
Conclusion
The Design used here is a cost-effective, automated, and simple solution to run Spark jobs on a transient EMR Cluster. In the next iteration, we can improve the design by adding more detailed log analysis in case of cluster failures, add more Lambda functions, and make use of step-functions to coordinate these Lambda functions.


Comments