
Published August 25, 2022
The 101 on the 360
“Knowing Your Customer” is one of the most foundational, aspirational desires for any business, and yet the undertaking remains much more complex and nebulous than most people realize. As organizations grow, the sheer volume of data they have on their customers causes all sorts of challenges, including complex integration across lines of business, to messy data privacy policies causing headaches. Even the act of defining a customer can be a challenging process. Is it an individual? A household? A business? Perhaps someone who purchased a product two years ago? There’s a plethora of great articles out there for this more conceptual work. We may touch more on this in a later post, but in this blog, we’re going to talk specifically about customer data and the technical aspects of tackling a Customer 360.
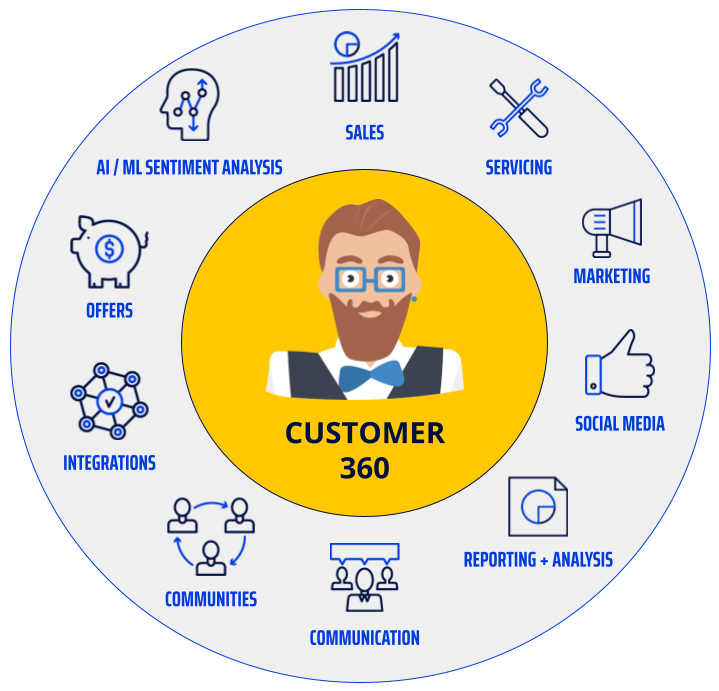
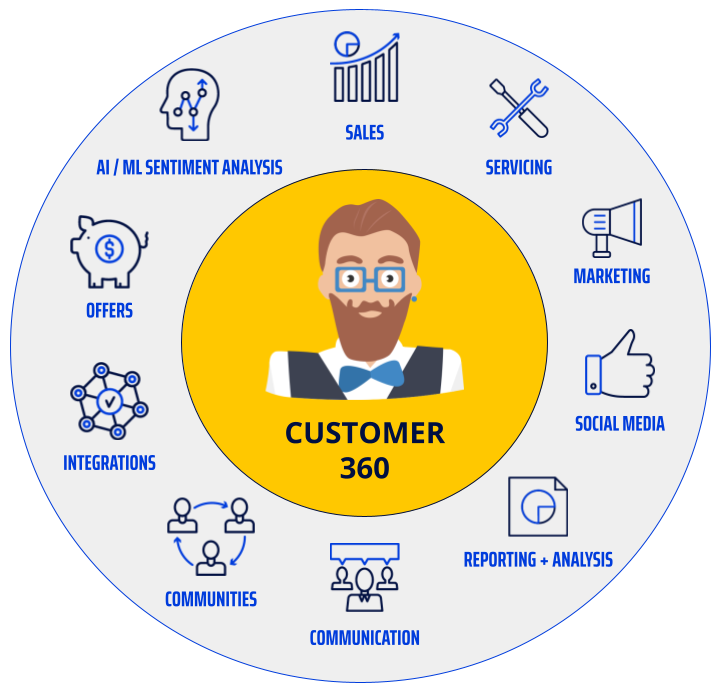
So what is a “Customer 360”? The term gets thrown around a lot, but at its core, it is the ability to know everything relevant about a customer: recent purchases, touch points with the organization, key attributes, contact information, preferences, etc. This is used for a variety of purposes, such as cross-selling, targeted marketing, relationship profitability analysis, identifying VIP customers, and many other benefits to the organization. Further, there are plenty of benefits for the customers themselves: seamless customer experience, more targeted and relevant marketing, etc. More foundationally, it provides a clean single source of truth for a customer’s attributes.
Now, where do we start, and what are the steps we must take to successfully implement such?
Data Discovery and Inventory
First, we must identify the sources of customer data we’ll be relying on. Perhaps your company already manages this type of activity well. You may already have an enterprise data warehouse, well-written documentation, maybe even a robust data catalog. In reality, that is likely not the case, however. This first step involves developing an inventory of data sources and analyzing the complexity of obtaining that data. Profiling the data to understand inconsistencies will save time reconciling quality issues down the road and possibly even yield some short term wins by identifying data quality patterns that can quickly be resolved upstream.
Within different departments and lines of business there will undoubtedly be “data gurus,” people who really understand the data and its quirks. Identifying these people and developing a relationship with them is key to truly documenting and inventorying this data (fun side note: this could be a great jumping-off point for a Data Catalog or Data Dictionary!). While the author of this blog is clearly biased, a third party consulting firm is most useful at this stage. The ability to see the forest from the trees and bring outside perspective provides a huge advantage.
Data Hygiene and Integration
Once we’ve done the work of finding out what data we need, where it resides, and what issues we are likely to encounter with it, comes the arduous task of improving the data’s hygiene. Data Quality issues are rife in organizations -- it’s just the nature of the beast. Outdated systems, poor processes, messy mergers, third party data, etc. all leave us with some degree of data hygiene problems. Oceans of digital ink have been spilled on the topic of Data Quality, but suffice to say, prioritizing the issues that are most likely to diminish the impact of a Customer 360 is a great place to start. In a perfect world, all of these issues will be resolved at their source, but since that isn’t always possible, transformations will be required. This will be an ongoing effort, so a thoughtful, well-documented approach will serve the future of the business well.
Next comes integration. This is tying all of your customers together, creating a centralized customer hub. This “single source of truth” should be sourced with all of the data needed for the identified use cases, be reasonably hygienic, and be architected in a way that satisfies your use cases and is easily maintained. There are a number of approaches and tools on the market for this, but a “hub” model is the most common, and may be a sub-architecture of other data resources within the organization (perhaps it resides in the Data Lake or within a Data Warehouse). Often, the most tricky part of this integration is identifying a unique business key to represent a customer. If “customer ID” or something along those lines has been consistently used across the organization, then that is simple. Usually, that is not the case, and some composite or surrogate key must be created and propagated. A “Global_customerID” may be required, for example. No matter how you proceed from here, organizational knowledge is tantamount so document data lineage, decisions made, transformations on the data, etc. When in doubt, DOCUMENT!
Integrating data introduces new and complex challenges that, similar to data quality, should be prioritized for business impact. Deduping records, particularly when customer data lives across different LOBs at different times in the organization’s history, can be challenging and numerous machine learning models exist to facilitate that process. Similarly, determining survivorship rules for key attributes, such as address information, must be developed when multiple addresses exist for a given customer.
Let’s go!
This may sound like a good deal of work. And, well, it is! However, it is highly valuable work with returns for many years to come. Knowing your customers is key to being competitive, and the ability to quickly glean insights and respond to market trends will be a major competitive advantage. This effort should be considered and prioritized now, as you should consider that the current volume of customer data in your organization is likely the smallest it will ever be again!
With deep expertise in Data Architecture and Data Engineering, Ippon is prepared to assist your organization on your Customer 360 Journey! Connect with me on LinkedIn (https://www.linkedin.com/in/steven-maclauchlan-baa55820/) or reach out to us at info@ippon.tech.




Comments