

Recap
Let's do a quick recap to see where we've been in our discussion. First, we introduced DQM at a high level, touching on how it can help your organization make data-driven decisions. The insights you extract from your upstream data having the same quality as your downstream data.
Next, we introduced the ABC framework. This framework is designed to help you create high quality data warehouses by imparting rules, checks, and metadata-driven processes around your data collection. We talked about how in the Audit stage you want to gather information about where your data came from, how it gets to your data warehouse, what the data is used for, etc.
We then examined how in the Balance stage you prove the integrity of your data by comparing it to the source. Balance ensures the data in your warehouse is quantifiably accurate by proving you can make intelligent business decisions against your data.
In this concluding blog, we will discuss the Control process and how it ties the knot on your DQM pipelines.
Consistent, Complete & Comprehensive Data Quality
You may recall the five aspects of an effective DQM system from the introductory post; the Control process focuses on three of those aspects: Consistency, Completeness, and Comprehensiveness.
Control allows your ETL pipelines to perform consistently across executions. Any ETL pipeline may run into various issues, including network connectivity that may cause data loss, schema validation errors that may create inconsistencies between upstream and downstream, database instances that may come down for patching or upgrades, etc. In a production scenario, the list of potential issues that may disrupt an ETL pipeline are limitless. The Control process will help to mitigate the negative effects of these issues, allowing your ETL pipelines to continue to perform the way it was designed to perform.
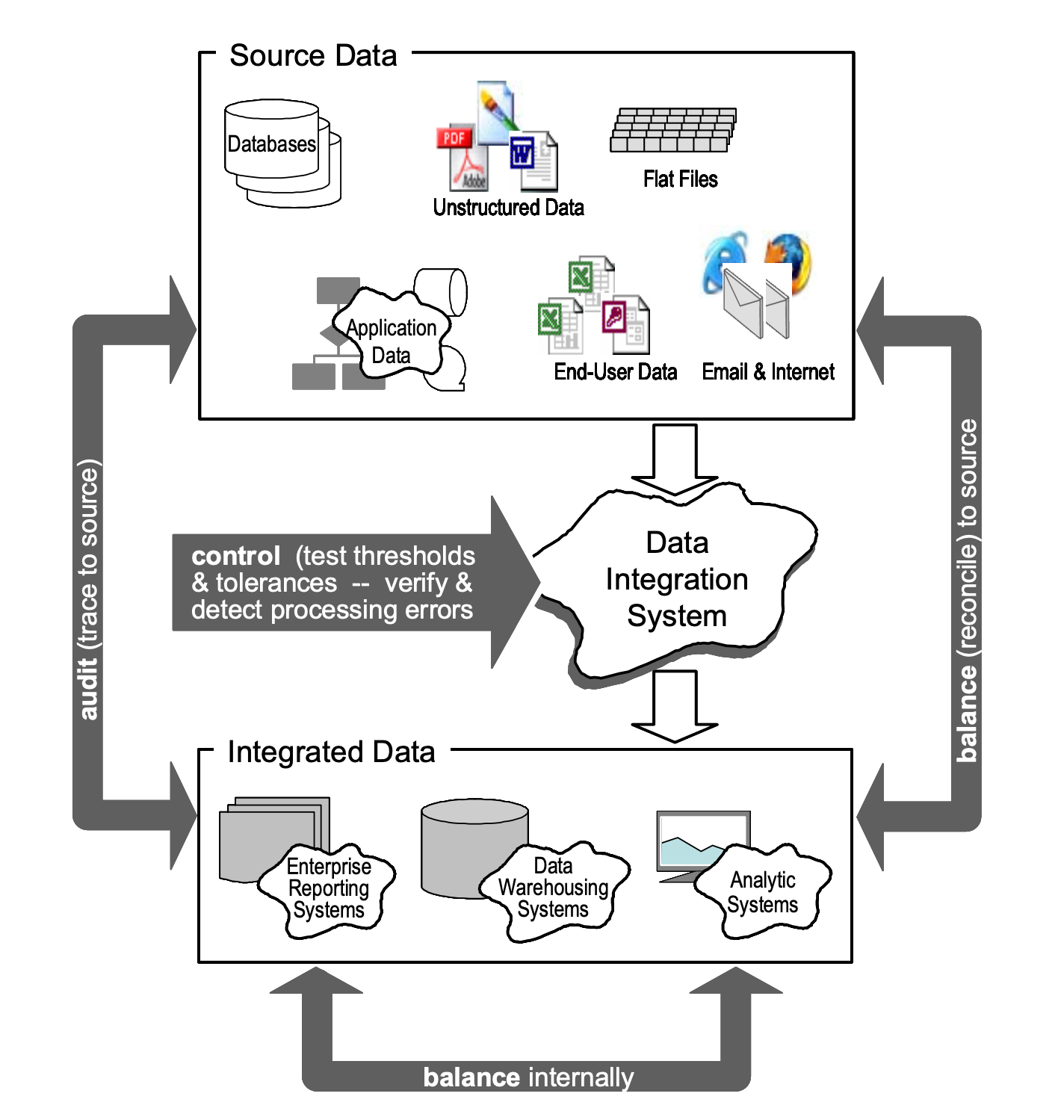
Control: Bringing it all Together
The Control process in a DQM pipeline is the "fixer" of errors. An effective Control process will look at the inputs of an ETL job and the corresponding outputs and ultimately be able to determine what went wrong and ideally how to fix said issues. Exactly how Control jobs do this is highly specific to your use case. But as long as a Control job accomplishes the following, we can consider a control job to be effective.
- Control jobs should understand the meta-information surrounding each record, such as where the record came from, where the record is going, what happened along the way, and why.
- Control jobs should use the meta-information known about each record to isolate instances where ETL jobs acting on those records do not perform as expected.
- Control jobs should be able to alert on failing records, possiby by even "replaying" records that have failed the ETL process, using the meta-information they are informed by.
- If a record cannot be automatically replayed, it should at the very least be flagged as non-compliant and requiring manual intervention.
This list of guidelines for Control processes is admittedly vague. However, just like the Audit and Balance processes, the Control process should be designed to suit the needs of your larger ETL/DQM ecosystem.
For example, if your ETL pipelines are batch-loading data from an OLTP database into a data warehouse day after day with a custom built orchestrator for seasonal sales trend analysis, we can implement Control accordingly. Your Control process can run on a schedule some time after the pipeline is finished. The job would first understand the state of both the OLTP system and the data warehouse by reading the output of the Balance process. After understanding the state of the OLTP system and the data warehouse, the Control process can start to make judgement calls using the business logic it has been built with.
In that example, we didn't need daily updates to our data warehouse to be accurate. When our Control process identifies records that need to be re-inserted to the data warehouse, we don't simply re-run the entire ETL job. Instead, the Control process isolates those records and stores them in a temporary storage, like a queue for example. This allows the Data Operations team to understand why the ETL pipeline failed and devise automation strategies for the future based on the errors they see most often. They can then go back and modify their orchestrator accordingly. This is ideal for scenarios where your Data Practice is still being developed.
Another example that is worth exploring is the near real-time ETL pipeline for rapidly updating data. These kinds of pipelines are not streaming per se, but they do run at rapid intervals, making it difficult to optimize ETL and DQM pipelines without having them slow down your data ingestion architecture. In a scenario like this, your Audit and Balance processes should be lightweight, just like your Control process. When your Control process starts, it needs to quickly understand what records were affected by the previous processes. Recall how Spark breaks up streaming data into slices? This is a similar approach to how you would want to craft your Control process. When your Control process runs, it ingests from the prior Balance process a slice of time upon which to isolate incongruous records. Where did the Balance process get the bounds for this time slice? The Balance process is informed by the Audit process. But where then did the Audit process know when to start and stop auditing? The Audit process was informed by the previous Control process. The previous Control process told the next iteration of DQM exactly what records or what time to start performing data quality checks. If your source system is insertion-heavy, you would want DQM to keep the pace if the insertions based on new ID fields. If your source system is update heavy, you would want to track DQM based on updated time fields.
As you can see, there's no one-size-fits-all solution to a Control process. It is difficult to generalize this kind of check. It relies heavily on the nature of your ETL process, how you want to resolve ETL errors, and what level of data quality want to ensure across your data warehouses. While we cannot pin down exactly how a well-crafted Control process works, we can certainly explore why Control is the last phase of DQM.
First A, Then B, Finally C
By now, it should be obvious why the Control process comes after Audit and Balance. Control is designed to correct and enforce the erroneous findings of Audit and Balance. Audit tries to determine what went wrong, Balance tries to determine how it went wrong, and Control tries to determine why it went wrong, possibly to the point of automatically fixing the issue.
Recall in the post on Audit, we defined some sample data to be acquired after each ETL run.
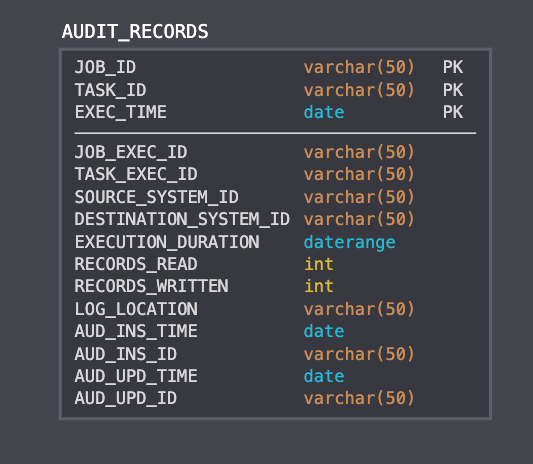
By the time we get to the Control phase, this information will have long been persisted to a DQM database. The database is exactly where we want this information at this point. The Control process is where we'll be utilizing this data to make informed decisions about what records need to be remediated. Can you identify any issues with this data model that would inhibit our ability to run Control tasks on erroneous records?
Let's take a look back at the criteria for a good Control job defined earlier in this post. From this table, do we understand where each record came from, where each record went, what happened along the way, and why? From this schema, we can discern the origin and destination for each record processed; and while we don't know exactly what happened along the way, we can presume how intensive the transform operation was along the way based on the execution_duration field. And if we wanted more information, we could look up the task associated with the recorded task_id.
From the table above, can we isolate instances where an ETL job did not perform as expected? The answer to this is "yes." The schema above will show us if there's an imbalance in the records we've collected. That information is helpful to know if a Control task should execute, but we need more information. This is where Balance comes into play. The prior Balance task associated with this ETL run should show the records between source and destination are imbalanced. Knowing exactly which records have caused the imbalance between source and destination allows us to focus our Control task. Otherwise we'll have to scan both the source and destination systems. This effectively replicates the Balance process in the Control process, and is redundant work. Use the Balance process to focus your Control process.
From this schema, can our Control job "replay" the ETL job that ran erroneously? Well, if the Audit process collected only the schema above, the answer to this question would be "no." We would have to capture information about individual job runs in order to "replay" an ETL job. How do we store this information to inform the Control process accordingly?
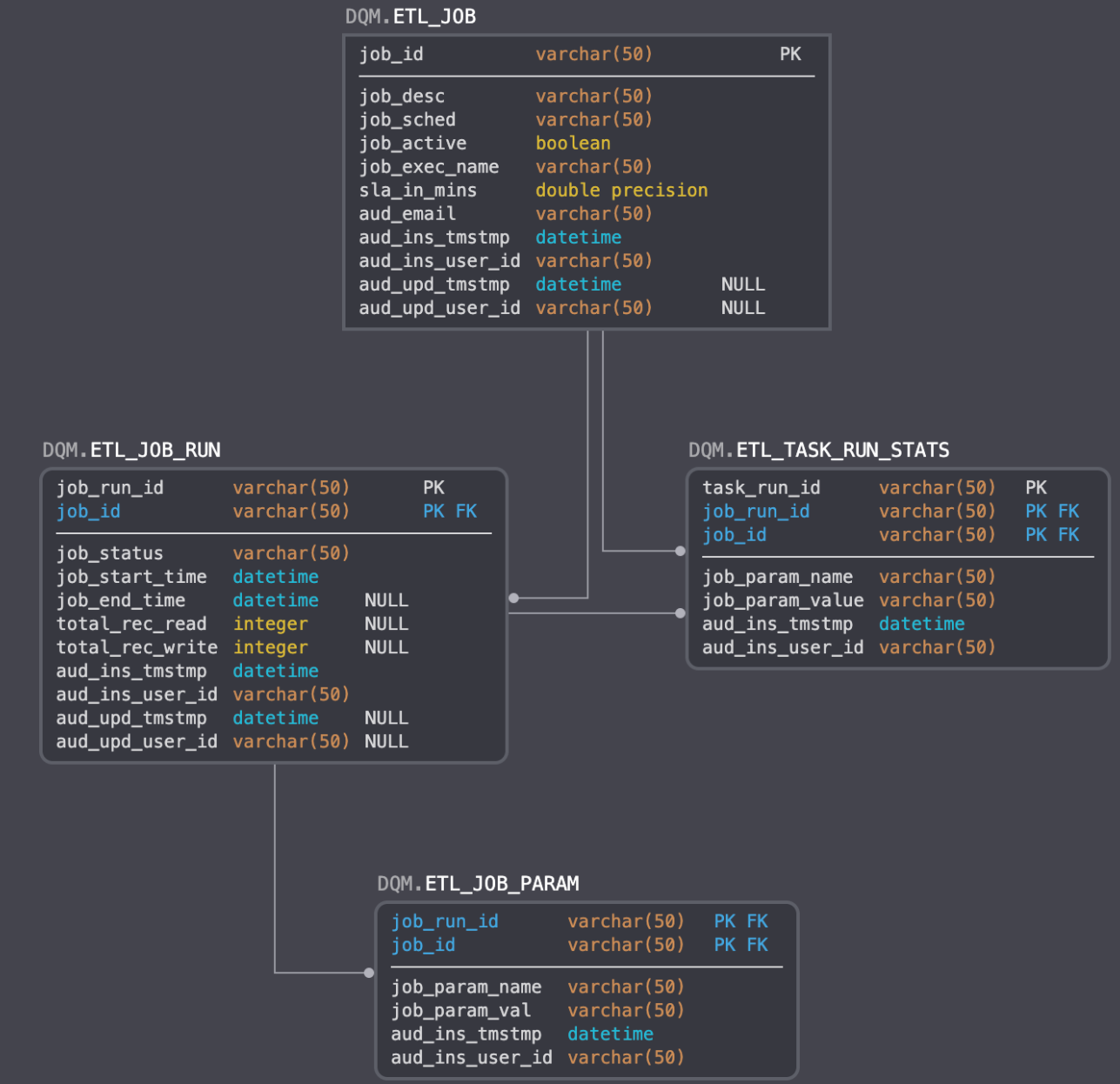
This schema paints a bigger picture of the kind of information we can collect to "replay" an ETL job. Notice the relationship among the ETL_JOB, ETL_JOB_RUN, and ETL_JOB_PARAM tables. These tables allow us to store all of the parameters associated with an individual run of an ETL job. By querying these tables appropriately, we can reverse engineer the job that created the erroneous records flagged by our Audit and Balance processes. From here, our Control process only has to resubmit an additional job with the same (or a modified set of) parameters from the one originally submitted.
What happens if we cannot rerun our ETL job? How do we make our erroneous records known? Did our Audit process gather enough information to flag an issue for manual intervention by a Data Engineer? Based on the above schema, the answer is "yes." Notice in the ETL_JOB table there are some fields preceded by the AUD_ prefix. The AUD_EMAIL field should point to the email of the data engineer that is equipped to fix any issues flagged by the ABC framework.
The above schemas are by no means complete. What we have shown here are the minimum requirements for an effective Control job. If the Audit and Balance processes have run properly, we can rest assured that for simple ETL jobs, your Control process should run effectively. That being said, it's very important to recognize DQM is not a one-size-fits-all solution. To properly implement the ABC framework, you need to thoroughly understand the needs of your ETL pipeline. By understanding the strengths and weaknesses of your ETL pipeline, you can craft effective Data Quality Management systems using the ABC framework.
Final Thoughts
There's a lot of information in this series on Data Quality Management, and these articles only scratch the surface. Hopefully they have piqued interest in the subject, as this is a complex field with no single solution. We can still do our best to generalize some thematic points that will help you to begin implementing a Data Quality Management system for your business.
- The ABC Framework is designed to codify issues and their corresponding resolutions encountered by ETL pipelines.
- The DQM solution employed by one ETL pipeline may not necessarily be the DQM solution required by another ETL pipeline. Use events to keep your DQM solutions flexible and responsive to your dynamic ETL architecture.
- Every issue encountered by an ETL pipeline should have a follow-up remediation action defined by your DQM pipeline. Audit determines if there was an issue, Balance determines what the issue was, and Control executes remediation. In other words, do not propagate errors downstream, propagate resolutions.




Comments