


Understanding Delta Lake
Delta Lake lets you build a production ready Lakehouse by providing a simple format that unifies all workloads (ETL, Data warehouse, Machine Learning, etc) while being platform agnostic so it runs on any cloud, on-prem or locally. The Delta Lake protocol has multiple specifications to define all the core concepts of Delta Lake, more details can be found here.
Delta Table
A Delta table is the core component of Delta, it provides an easy way of storing data while enforcing a schema and version history. Each table has a _delta_log folder that contains multiple JSON files that contains all the operations done to the table. The Delta Lake API takes care of reading/parsing those JSON files but feel free to open one to understand how Delta manages a table.
Parquet format
All the data files are stored using the Parquet file format in the root directory of the table. Storing data in a columnar format has a lot of advantages over formats like CSV or JSON. I recommend reading this Databricks article on why Parquet was picked for Delta Lake.
ACID Transactions and Data Integrity
A key feature of Delta Lake is that it brings ACID properties to large collections of data, stored as files, in a distributed file system or object store. That is very important, especially when multiple writers can concurrently modify a Delta table. Also, each table is self describing: all metadata for a Delta table is stored alongside the data. This design eliminates the need to maintain a separate metastore just to read the data and also allows static tables to be copied or moved using standard file system tools.
Key Features and Functionality
Schema Evolution
When writing data, if the schema of the source dataframe is different than the target dataframe then the write will fail because of a schema mismatch. By setting the option overwriteSchema to true, Delta Lake will simply replace the previous schema with the new one and each new column will have a NULL value for all the previous rows (more details here).
Time Travel and Audit
Table history provides all the operations done to a table and each operation has a unique version. For audit purposes, it is very useful to know what kind of operation was done while knowing operation metrics like number of rows or files written.
You can also query a table with a specific version or timestamp in order to retrieve an older snapshot, more details here.
Optimize
Writing data to a table produces parquet files for each write which impacts reading speed because of having small data files. To avoid this issue, Delta Lake can improve the speed of read queries from a table by coalescing small files into larger ones. It is recommended to run the optimize command often but not always because of the processing power's cost, please read this page for more details.
Vacuum
The vacuum command removes data files no longer referenced by a Delta table in order to save money by reducing storage cost. Be careful because after vacuuming, you will not be able to retrieve versions that are older than 7 days (default retention period), more details here.
Merge
Merging data to a Delta table allows you to perform an UPSERT operation which means that any existing record will be updated while inserting any new records. This is very useful when updating existing data because you don't have to worry about removing previous data, Delta Lake will just update previous data based on your key. For more details on how to merge data, please read this page..
Generated Columns
Delta Lake supports generated columns which are a special type of column whose values are automatically generated based on a user-specified function over other columns. This is one of my favorite features and will save you a lot of time by avoiding having to add columns before writing data. A good example for this feature is when you have a date column in your dataset but you also want to have a year/month column based on that date.
Let's first start by creating a simple dataframe:
import datetime
# Create initial dataframe
values = [
("AAPL", datetime.date(2023, 1, 1), 100),
("TSLA", datetime.date(2023, 2, 1), 50),
]
columns = ["symbol", "date", "price"]
df = spark.createDataFrame(values, columns)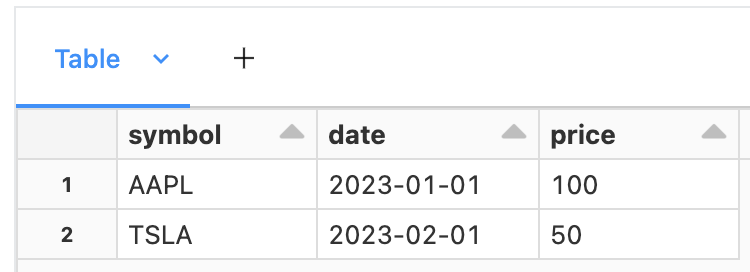
Then let's add two columns that are generated from the column date:
from delta.tables import *
# Add 2 generated columns
DeltaTable.create(spark) \
.tableName("default.blog") \
.addColumns(df.schema) \
.addColumn("year", "INT", generatedAlwaysAs="YEAR(date)") \
.addColumn("month", "INT", generatedAlwaysAs="MONTH(date)") \
.execute()
df.write.format("delta").mode("append").saveAsTable("default.blog")
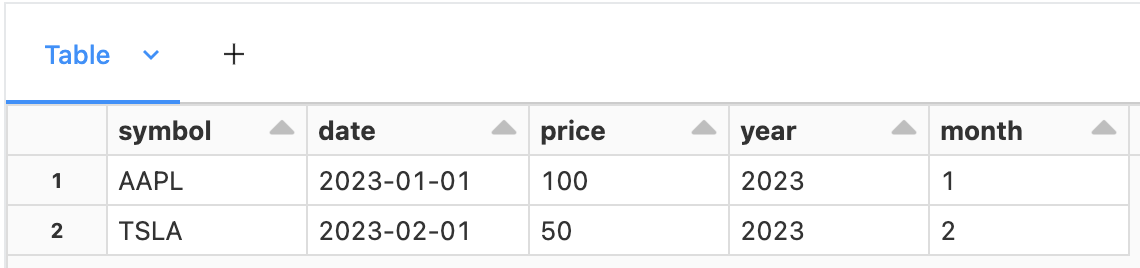
Delta Lake takes care of generating the columns year and month for every insert/update operations. A generated column can also be used as a partition column and Delta can generate partition filters using that column. This concept is very similar to hidden partitioning, read the documentation for more details.
Read Data From a Table Without Spark
Since the underlying storage format of Delta Lake is parquet, any Python data analysis library (like Pandas) can technically read the data of a Delta table. But because Delta Lake keeps versions, reading the parquet files directly will include duplicates from all the previous versions. To avoid that, I recommend using two libraries that support Delta Lake.
Polars
If you like Pandas then you should definitely start using Polars instead as it has better performance. The library also has a lazy API that is extremely useful when loading big datasets to avoid running into memory or performance issues.
Here is an example on how to read a Delta table with Polars (more details here):
import polars as pl
table_path = "/path/to/delta-table/"
pl.read_delta(
table_path,
pyarrow_options={"partitions": [("year", "=", "2021")]}, # Faster read by selecting specific partitions
)Deltalake Library
An alternative to Polars is to use the deltalake Python library to read the Delta table. The library lets you read the data from a table while also helping you converting it to a Pandas dataframe or PyArrow dataset.
Here is an example on how to read a Delta table (more details here):
from deltalake import DeltaTable
dt = DeltaTable("/path/to/delta-table/")
dt.to_pandas(partitions=[("year", "=", "2021")])
dt.to_pyarrow_table(partitions=[("year", "=", "2021")])
Conclusion
In summary, Delta Lake empowers businesses with a reliable, scalable, and performant data storage and processing solution. By adopting Delta Lake, organizations can unlock the true potential of their big data initiatives, ensuring data quality, consistency, and enabling advanced analytics. So, whether you're a data engineer, data scientist, or business analyst, it's time to explore the transformative possibilities of Delta Lake in your big data journey.
The ACID transactions and data integrity guarantees provided by Delta Lake ensure consistent and reliable data processing, enabling organizations to have complete trust in their data pipelines. Moreover, Delta Lake's schema evolution, time travel, and metadata handling features provide the flexibility and agility required to adapt to evolving business needs.
Need help with your existing Delta Lake platform? Or do you need help using the latest Data lake technology? Ippon can help! Send us a line at contact@ippon.tech.




Comments