

Spring Data JPA provides an implementation of the data access layer for Spring applications. This is a very handy component because it does not reinvent the wheel of data access for each new application and therefore you can spend more time implementing the business logic. There are some good practices to follow when using Spring Data JPA. For instance, limit the loading of unnecessary objects to optimize performance.
This article will give you some tips to reduce round trips to the database, not to retrieve all the elements of the database and thus not to impact the overall performance of the application. For this, we will first see the various tools that Spring Data JPA provides to improve the control of data access, as well as some good practices to reduce the impact that data retrieval will have on our application. Then, I will share with you a concrete example of improving the performance of a Spring application by playing on these different aspects and thus reducing the underlying problems.
The loading of entity relationships
A bit of theory: loading types EAGER and LAZY
When creating an application with Spring Data JPA (and with Hibernate in general), object dependencies (for instance the book’s author) may be loaded automatically - EAGER loading - or manually - LAZY loading.
With an EAGER type dependency, every time an object is loaded, the related objects are loaded as well: when you ask for book’s data, author’s data is also retrieved.
With a LAZY type dependency, only data of the wanted object is loaded: author’s data is not retrieved.
With Spring Data JPA, every relationship between 2 domain objects owns one of these data loading types. By default, the method will be determined by the relationship type.
Here is a reminder of all possible relationships with their data loading default type:
@OneToOne
For every instance of entity A, one (and only one) instance of entity B is associated. B is also linked to only one instance of entity A.
A typical example is the relationship between a patient and his record:
@Entity
public class Patient implements Serializable {
@OneToOne
private PatientRecord record;
}
For this relationship type, the default data loading method is EAGER: every time you ask for patient’s data, the folder’s data will also be retrieved.
@ManyToOne
For every instance of entity A, one (and only one) instance of entity B is associated. On the other hand, B may be linked to many instances of A.
A typical example is the relationship between a product and its category:
@Entity
public class Product implements Serializable {
@ManyToOne
private ProductCategory category;
}
For this relationship type, the default data loading method is EAGER: every time you ask for product’s data, the category’s data will also be retrieved.
@OneToMany
For every instance of entity A, zero, one or many instances of entity B is associated. On the other hand, B is linked to only one instance of A.
It is the opposite of the relationship @ManyToOne, so a typical example may be the product category with its associated list of products:
@Entity
public class ProductCategory implements Serializable {
@OneToMany
private Set<Product> products = new HashSet<>();
}
For this relationship type, the default data loading method is LAZY: every time you ask for category’s data, the product list will not be retrieved.
@ManyToMany
For every instance of entity A, zero, one or many instances of entity B is associated. The opposite is also true, B is linked to zero, one, or many instances of A.
A typical example is the relationship between a blog article and its list of topics:
@Entity
public class Article implements Serializable {
@ManyToMany
private Set<Topic> topics = new HashSet<>();
}
For this relationship type, the default data loading method is LAZY: every time you ask for article’s data, the top list will not be retrieved.
Minimize the use of EAGER relationships
The goal is to load from the database only the needed data for what you are asking for. For instance, if you want to display the list of authors by name registered in the application, you don’t want to fetch all of the relationships’ data: the books they wrote, their address, etc.
A good practice is then to minimize the relationships automatically loaded (i.e. Eager. Indeed, the more you have got EAGER relationships, the more you will fetch objects not necessarily useful. This means an increase of round trips needed to the database and an increased amount of time dedicated to the mapping between database tables to the application entities. Because of that, it may be interesting to privilege the use of LAZY relationships and to load data of missing relationships only when they are needed.
In concrete terms, it is advisable to use EAGER loading only for the relationships where you are sure that the linked data will always be useful (and I reckon it is not so often). This implies to let the default loading methods for both relationships @OneToMany and @ManyToMany and to force the LAZY loading for both relationships @OneToOne and @ManyToOne. This is reflected in specifying the fetch attribute of the relation:
@Entity
public class Product implements Serializable {
@ManyToOne(fetch = FetchType.LAZY)
private ProductCategory category;
}
This requires additional work of adjustment for each entity and each relationship because it will be essential to create new methods that will allow us to load all the data necessary for an action in a minimum of queries. Indeed, if the need is to display all the data relative to an author (his bio, his book list, his addresses, etc.), it will be interesting to get the object and its relationships in one query, so using joins in a database.
How to control which queries are executed
Spring Data JPA provides access to data for us. However, you must be aware of how this will be implemented. To verify which queries are executed to retrieve data from the database, the Hibernate logs have to be activated.
There are several options. First, an option can be activated in Spring configuration:
spring:
jpa:
show-sql: true
Or, it is possible to configure it in the logger’s configuration file:<logger name="org.hibernate.SQL" level="DEBUG"/>
Note: in these logs, all the arguments given to queries are not displayed (they are replaced by "?"), but it does not prevent us from seeing which queries are executed.
How to optimize the retrieval of LAZY objects
Spring Data JPA provides the ability to specify which relationships will be loaded during a select query in the database. We will have a look at the same example with several methods: how to retrieve an article with its topics in a single query.
Method 1: Retrieving and loading objects with @Query
The annotation @Query allows writing a select query using the JPQL language. You can thus use the JPQL keyword fetch positioned on the join of the relationship in order to load these relationship.
In the repository of the Article entity, it is thus possible to create a method findOneWithTopicsById by specifying that the list of topics should be loaded in the instance of the retrieved article:
@Repository
public interface ArticleRepository extends JpaRepository<Article,Long> {
@Query("select article from Article article left join fetch article.topics where article.id =:id")
Article findOneWithTopicsById(@Param("id") Long id);
}
Method 2: Retrieving and loading objects with @EntityGraph
Since version 1.10 of Spring Data JPA, you can use the @EntityGraph annotation in order to create relationship graphs to be loaded together with the entity when requested.
This annotation is also used in JPA repositories. The definition can be done either directly on the query of the repository or on the entity.
Definition of the graph on the query
We define the relationships which will be loaded with the entity thanks to the keyword attributePaths which represents the relationship list (here, a list of one element):
@Repository
public interface ArticleRepository extends JpaRepository<Article,Long> {
@EntityGraph(attributePaths = "topics")
Article findOneWithTopicsById(Long id);
}
Definition of the graph on the entity
We can also define these graphs on the entity thanks to the notion of NamedEntityGraph from JPA 2.1. The main advantage is that it is possible to use this graph definition on several queries. In this case, we specify the list of loaded relationships thanks to the keyword attributeNodes which is a list of @NamedAttributeNode. Here is how to implement it in the Article entity.
@Entity
@NamedEntityGraph(name = "Article.topics", attributeNodes = @NamedAttributeNode("topics"))
public class Article implements Serializable {
...
}
Then it is possible to use it as follows:
@Repository
public interface ArticleRepository extends JpaRepository<Article,Long> {
@EntityGraph(value = "Article.topics")
Article findOneWithTopicsById(Long id);
}
Moreover, it is possible to specify the loading type for the non-specified relationships with the attribute type: LAZY loading for all the non-specified relationships or loading by default (EAGER or LAZY according to the type indicated on the relationship).
It is also possible to create subgraphs and thus work in a hierarchical way to be as thin as possible.
Limitation on the use of @EntityGraph
For these 2 methods related to entity graphs, one cannot, to my knowledge, retrieve a list containing all the entities with relationships. Indeed, for that, one would like to create a method which would be defined for instance as findAllWithTopics() with graph nodes topics. This is not possible; you must use a search restriction (synonymous with where in a select query in the database).
To overcome this limitation, one solution is to create a method findAllWithTopicsByIdNotNull(): the id is never null, all the data will be retrieved. The alternative is to do this join query using the first method because the @Query annotation does not have this limitation.
Adding non-optional information if needed
When a @OneToOne or a @ManyToOne relationship is mandatory - that is, the entity must have its associated relationship - it is important to tell Spring Data JPA that this relationship is not optional.
We can take the following example: a person must have an address, which can itself be shared by several persons. So, the definition of the relationship is as follow:
@Entity
public class Person implements Serializable {
@ManyToOne(optional = false)
@NotNull
private Adress adress;
}
Adding optional = false information will allow Spring Data JPA to be more efficient in creating its select queries because it will know that it necessarily has an address associated with a person. Therefore, it is good practice to always specify this attribute when defining mandatory relationships.
Points of attention
Beware of consequences
Although changing the default loading of the relationships from EAGER to LAZY could be a good idea for performance, it can also have some unintended consequences and some regressions or bugs can appear.
Here are two very common examples.
Potential loss of information
The first side effect may be the loss of information, for instance when sending entities via a web service.
For instance, when we modify the relationship between Person and Address from EAGER to LAZY, we have to review the select queries of Person entities in order to add the explicit loading of their address (with one of the methods seen above). Otherwise, the Person web service may only provide the data specific to the Person and the Address data may have disappeared.
This is a problem because the web service may no longer comply with its interface contract. It may, for example, affect the display on a web page: it is expected that the address is returned because it is needed to display it in the HTML view.
In order to avoid this problem, it is interesting to use Data Transfer Objects (DTOs) rather than directly returning the entities to clients. Indeed, the mapper transforming the entity into DTO will load all the relationships it needs by retrieving in the database the relationships that have not been loaded during the initial query: this is the Lazy Loading. Therefore, even if we don’t refactor the recovery of entities, the web service will continue to return the same data.
Potential transaction problem
The second side effect can be the LazyInitializationException.
This exception occurs when trying to load a relationship outside of a transaction. The Lazy Loading cannot be done because the object is detached: it does not belong to a Hibernate session anymore. This may occur after changes to the relationship loading type because, prior to these changes, the relationship was automatically loaded when retrieving data from the database.
The exception may, in this case, be thrown for 2 main reasons:
- The first cause may be that you are not in a Hibernate transaction. In this case, you have to either make the process transactional (thanks to the
@TransactionalSpring annotation to be set on the method or its class) or call a transactional service that can take care of loading the dependencies. - The second cause may be that you are outside of the transaction in which your entity was attached, and the entity is not attached to your new transaction. In this case, you have to either load the relationships in the first transaction or reattach the object in the second.
Specificities for paged queries
When you want to create a paged query that contains information from one or more relationships, loading the data belonging to relationships directly from the select query is a (very) bad idea. For instance, when we retrieve the first page of the articles with their topics, it is better not to load directly all the articles+topics data, but first load the data from the articles and then the data related to the topics.
Indeed, without this, the application will be forced to recover the full data set of the join between the 2 tables, store them in memory, then select only the data of the requested page. This is directly related to the way databases work: they must select all the data of the join even if we only need a fragment of the data (a page, a min/max or the top x of the results).
In the case of a loading a page with its relationships, an explicit message appears in the logs to warn you:
HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
The greater the volume of the 2 tables, the higher the impact: with tables containing millions of entries, this can result in extremely expensive processing for the application.
To overcome this problem, it is therefore essential to first load the entities without their relationships and then load them again in a second step. To load the entity data of the requested page, you can use the findAll(Pageable pageable) method of the JPA repository (inherited from the PagingAndSortingRepository class). Then, to load the relationships data, you can use the Lazy Loading by directly calling the getter of the relationships to retrieve data for each of the entities.
This operation will be expensive because it will generate a lot of queries. Indeed, there will be - for each entity - as many select queries as there are relationships to load: this problem is known as "Hibernate N+1 query problem". If we take the example of loading a page of 20 articles with a relationship to load, this will result in 21 queries: 1 for the page and 20 for the topics of each article.
To reduce this cost, it is possible to use the @BatchSize(size = n) annotation on the @OneToMany or @ManyToMany relationship between the two entities. This allows Hibernate to wait until there are enough (n) relationships to retrieve before making the select query in the database. This number n is to be associated with the size of the pages (it nevertheless means having a default page size because n is defined on the entity and therefore constant). In the previous example, we can specify the minimum number to 20:
@Entity
public class Article implements Serializable {
@ManyToMany
@BatchSize(size = 20)
private Set<Topic> topics = new HashSet<>();
}
In this case, the number of queries to load the page will decrease from 21 to 2: 1 for the page and 1 for all topics.
Note: if the page contains less than 20 elements (so less than n), the topics will still be correctly loaded.
Going further
Here are some other interesting points to dig in order to not see the performance of your application drop.
Using a cache
To boost the performance of your application, it may be interesting to use a cache system. First, there is the Hibernate second level cache. It makes it possible to keep the domain entities in memory as well as their relationships and thus reduce the number of accesses to the database. There is also the query cache. In addition to the second level cache, it is often more useful. It makes it possible to keep the queries made and their results in memory.
However, we must pay attention to a few points when using this one:
- the second level cache is only useful when accessing entities by their id (and by the proper JPA methods);
- in a distributed application, it is mandatory to also use a distributed cache, or to use it only on read-only objects that rarely change;
- the implementation is more complicated when the database can be altered by other elements (that is to say when the application is not the central point of access to the data).
Index creation
Index creation is a necessary step to improve database access performance. This allows faster and cheaper selection searches. An application without index will be much less efficient.
Some details on creating indexes:
- an index will show the best improvements of performance on large tables;
- an index is generally useful only if the data has sufficient cardinality (an index on the gender with 50% Male and 50% Female is not very efficient);
- an index that speeds up reading will also slow down writing;
- not all DBMSes have the same indexing policies that must be looked at. For example, an index can be created automatically or not when adding a foreign key, depending on the DBMS.
Transaction management
Transaction management is also important in terms of optimization: it is necessary to use transactions correctly if we do not want to see performance issues. For example, transaction creation is expensive for the application: it is best not to use them in cases where they are not necessary.
By default, Hibernate will wait for the Spring transaction to complete before updating all the data in the database (except in cases where it detects that an intermediate persistence flush is needed). Meanwhile, it will store the updates in memory. If a transaction involves a large amount of data, performance issues may occur. In this case, it is best to split the processing into multiple transactions.
In addition, when the transaction is not writing, you could tell Spring that it is read-only to improve performance: @Transactional(readOnly = true)
Real life example
I was recently asked to work on performance problems of a web application.
Despite a first work on some parts to improve overall performance, the application continued to cause saturation of the servers on which it was installed (especially the CPU load), waiting times for each request were very high and it seemed to have reached the maximum volume that the application could support.
By looking at the number of queries made to the database (by activating Hibernate logs) and looking in the code how theses queries were produced, I decided to apply the few tips of this article to allow the application to breathe.
Process used
The web application I worked on has the specificity to work much more as batches (actions done every 1 to 60 seconds depending on the job) than user actions.
In order to reduce these performance issues, I tried to proceed iteratively, worrying about one batch at a time in the decreasing order of the frequency of the jobs: first those that are done every second until to those made every minute.
For each job, I was counting the number of Hibernate select queries made to perform the process and I was trying to check if each was needed or if it was data that was uselessly retrieved. As soon as I found an inconsistency in what was loaded from the database, I was changing the type of relationship (EAGER or LAZY), I was creating adapted queries in the repositories and I was favoring the selection criteria for the query (as opposed to a filter applied a posteriori on the list of retrieved data).
The goal was to reduce the number of queries made to a minimal number (only one if possible) and to load only the objects needed for each treatment.
In order to check whether the load on the database (and data loading) was decreasing, I decided to analyse on 2 metrics: the number of select queries and the number of objects loaded per minute. For that, I used a rather simplistic method: I was redirecting the application logs during 1 minute, and from this file, I was counting:
- the number of select queries: number of occurrences of
SELECT ...; - the number of loaded objects: number of occurrences of
SELECT ...added to the number of occurrences of... join fetch ....
Results
After a few days of work on this subject, and applying only these few steps, I managed to divide by about 5 the number of queries sent to the database and about 7 the total number of loaded objects. With the new version of the application in production, the load of the server has really reduced.
As a proof, here is the state of the server before the new version:
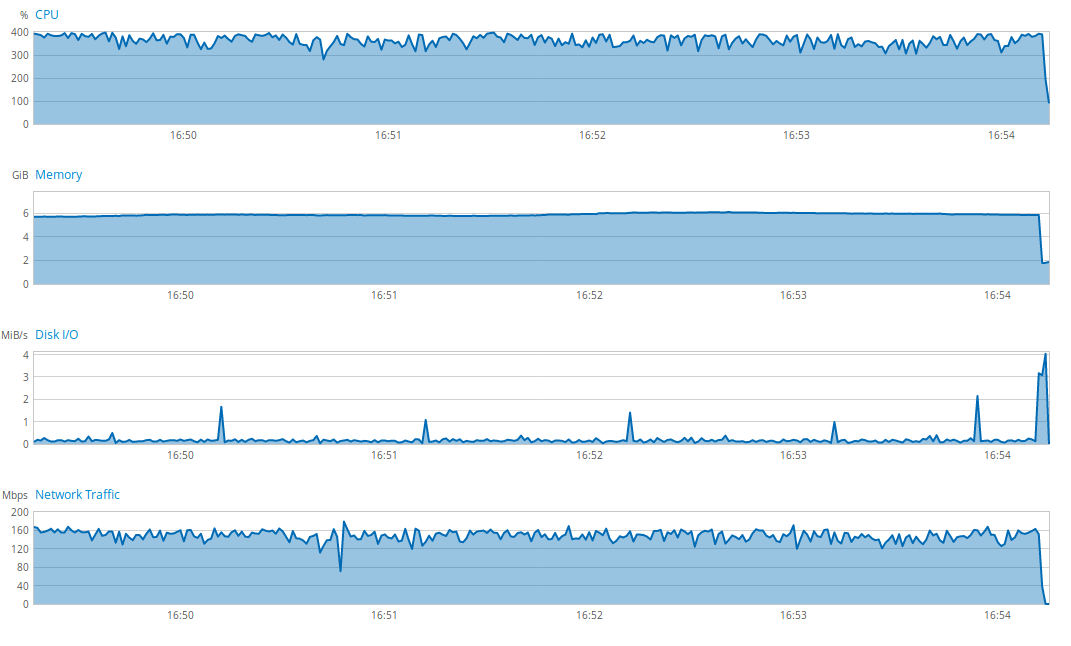
We notice an important and almost worrying use of all the resources of the server. After switching to the new version, here is the state of the server:
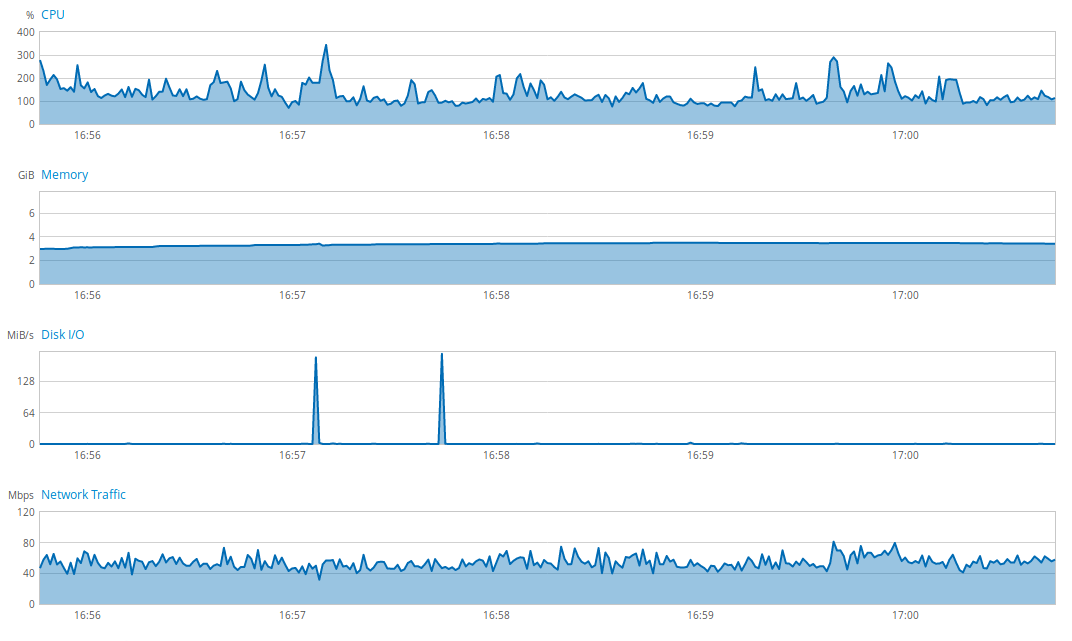
The overall use of the server has been impressively reduced thanks to some small adjustments, simple to put in place. It is, therefore, necessary for me to keep in mind these issues when developing an application.
Conclusion
After outlining the different types of entity relationships and their default loading method, we understood why it is important to maximize LAZY loading of entity relationships. We learned how to get as much data as possible in a minimum number of queries, which is even more important when using LAZY loadings, thanks to some tools provided by Spring Data JPA. With an example in the form of feedback, we saw how important it is to respect these few tips if we do not want to notice significant performance drops in our applications.
What is important to remember is that every request for data to the database must be justified, that we must not retrieve data that is not useful for the application, and that it is preferable to minimize the number of select queries for each request for data (only one per request if possible).
This work is continuous, it must be done along the way during the implementation of the application. Otherwise, you will have to look at these issues when performance problems occur, at the risk of experiencing regressions during resolution attempts.
Do not go into excess, some actions do not necessarily require a significant investment of time. This work is especially important when an action is performed very often, and when you retrieve large blocks of data.
Resources
- https://www.jtips.info/index.php?title=Hibernate/Cache
- https://dzone.com/articles/spring-data-jpa-and-database
- https://jhipster.github.io/
- https://jhipster.github.io/using-cache/
- http://spring.io/
- http://projects.spring.io/spring-data-jpa/
- https://docs.spring.io/spring-data/jpa/docs/current/reference/html/
- http://docs.spring.io/spring-data/data-jpa/docs/current/api/org/springframework/data/jpa/repository/EntityGraph.EntityGraphType.html
- https://vladmihalcea.com

.png?width=520&height=294&name=Webflux%20image%20(1).png)

Comments