

Having recently made the switch from software to data engineering, I learned there are many new concepts and ideas that need to be picked up and understood quickly. Such concepts include things like Data Lakes, Data Warehouses, and Data Modeling. In this blog, I will give a basic introduction to each of these concepts from a high level, giving those new to the data world, like myself, a nice springboard into learning more about these topics.
Data Lakes, Data Warehouses, and The Process
Now from a high level view, a Data Lake can be considered a repository for raw, unreformed data, whereas a Data Warehouse is a repository for processed, ready-for-production data. In the diagram below, we can see that the Data Lake can receive data from a number of sources. In this specific case, databases -- which will then be available for Data Engineers to study, analyze, and manipulate (more on that in a bit).
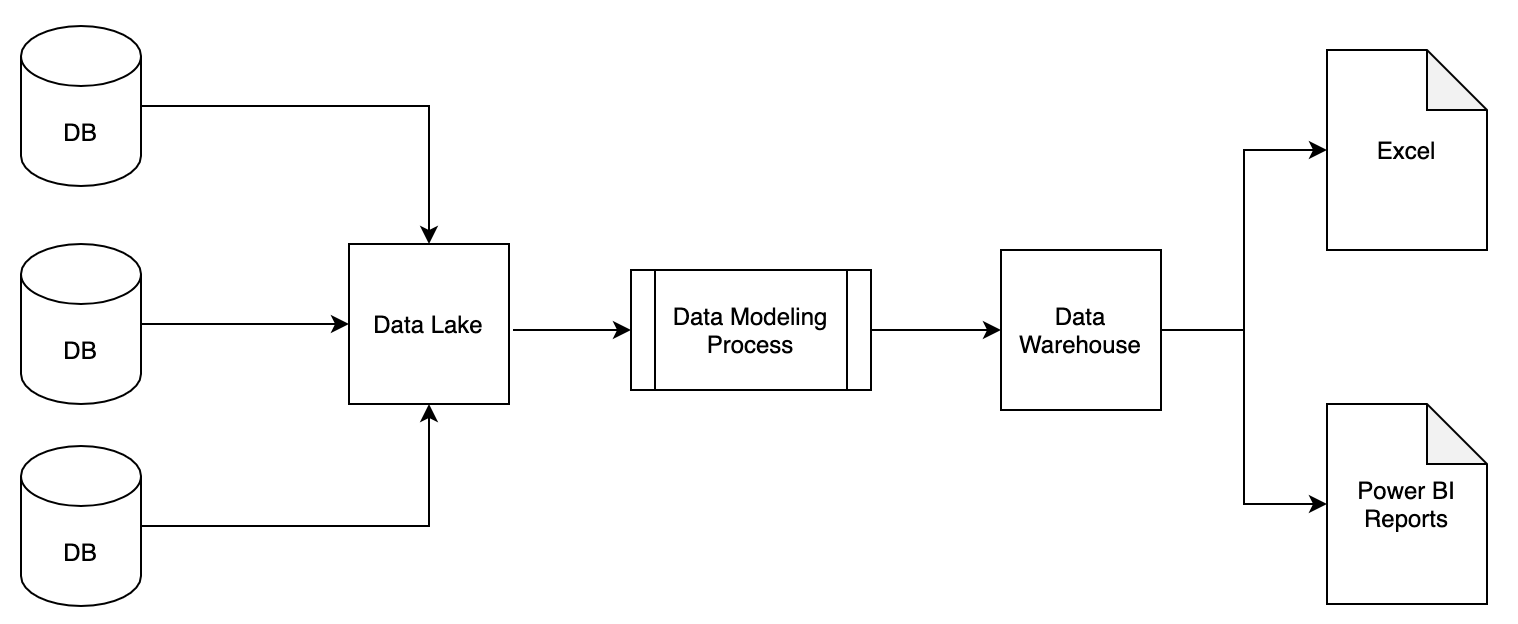
Near the tail end of the process, we see the Data Warehouse which houses data ready to be used by real world users, not just Data Engineers. As we can see, end users utilizing tools like Excel and Power BI can use this data in their work. But how do we get there? That’s where Data Modeling comes into play.
Data Modeling
At its most basic, Data Modeling is the process we use to visualize and represent data that will be stored within our Data Warehouse. This will include studying and understanding the data we will be working with and discovering the relationships between this data, all while working towards creating data models that will be useful to the end user.
At this point, we can use a simple example to better illustrate the concept.
Suppose you have been tasked with analyzing school data with the end user wanting to run reports to see how students are doing with their assessments, among other things. One of the first steps would be to look at the available data and begin to understand what it represents and how it can be related to each other to help enrich it.
Within the database we find an 'Assessments' table that seems to have some information that will be useful to the end user:
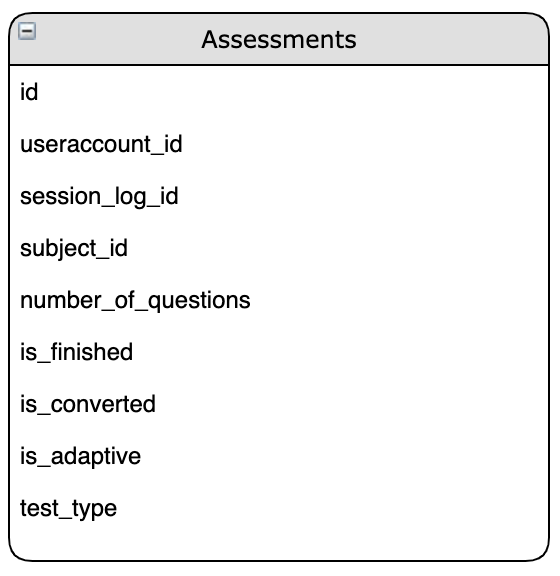
In looking at this data, we notice there is a subject_id which appears to correlate with the id within the 'Subjects' table:

We seem to have found a useful relationship between these individual tables! This association can be seen below:
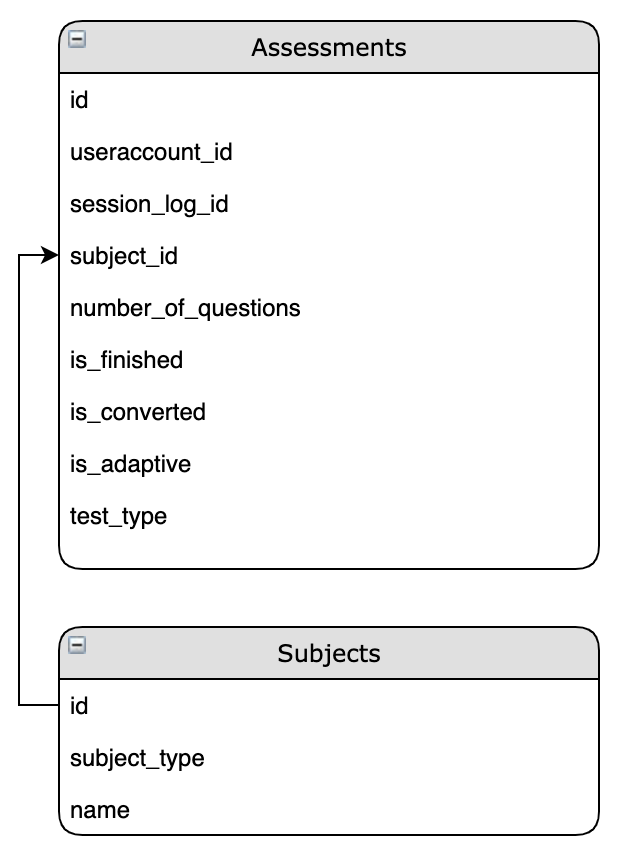
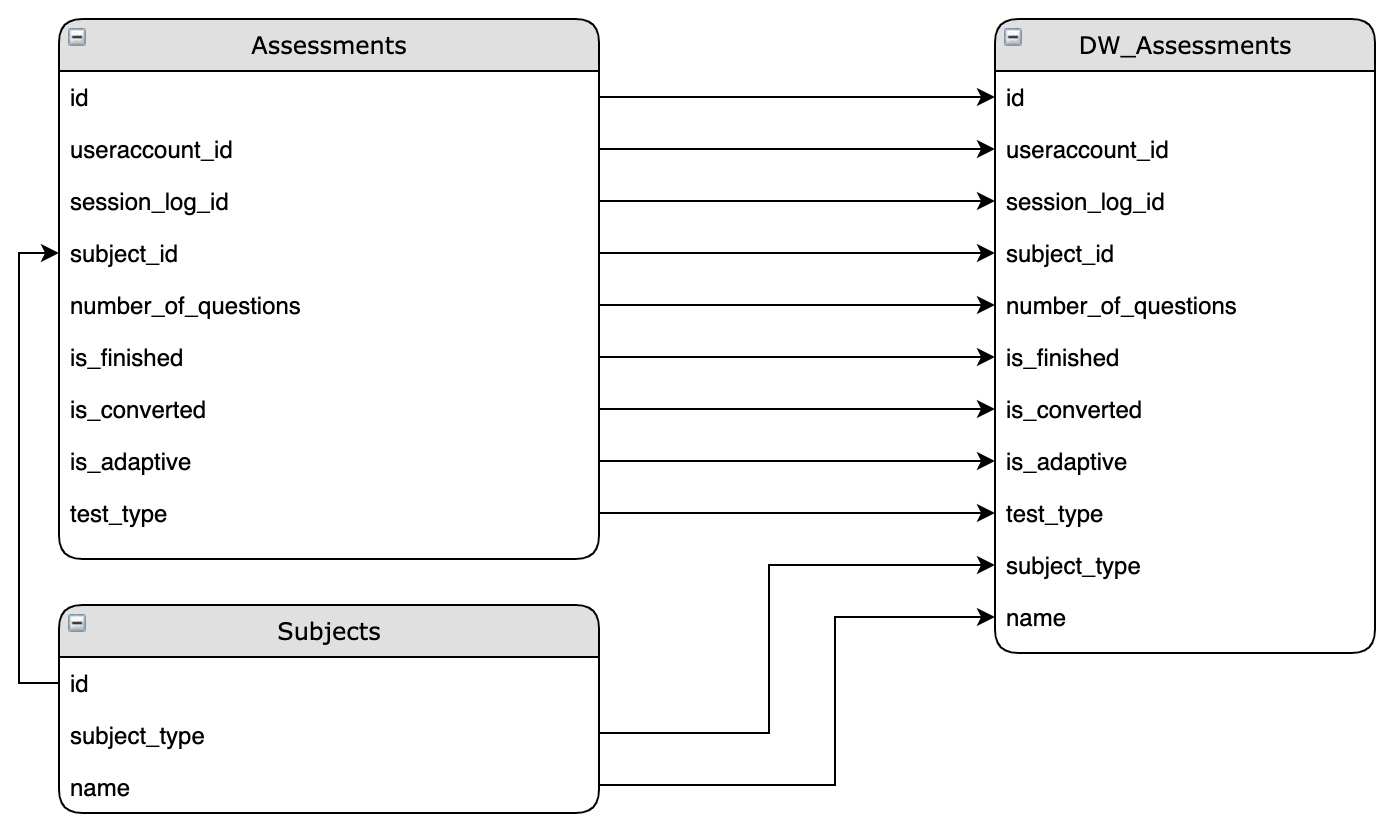
Finding these relationships is at the heart of Data Modeling. What we have done is made the data more useful, valuable, and meaningful to the end user who will be using this in their daily reporting. We can use this same methodology to continue to find meaningful relationships within the data to further enhance it, but for the sake of simplicity, we will leave our Data Modeling here.
At the end of this process, we now have a new table that we can call ready-for-production and will live in our Data Warehouse.
Conclusion
As mentioned before this is just the tip of the iceberg when it comes to each of these topics. Even so, as a long-time Software Engineer that has only recently made the jump to Data Engineering and now has a completed data project under his belt, this is high-level information that would have been invaluable to have known going into it. I would imagine that any other life-long Software Engineer's thinking about making the switch into the world of data would probably agree.




Comments