

October 26, 2021
An event-driven architecture is a paradigm that has become increasingly used in modern microservices-based architectures. It promises a more flexible and responsive architecture to business events, while offering better technical decoupling.
Appealing! But how do we get started?
In this two-part article, I will review the important elements to consider when starting to implement an event-driven architecture with Kafka.
In this first part, I will define what an event-driven architecture is and how Kafka can be used to build such.
Event-Driven Architecture
To define what an event-driven architecture is, let's first go back to the concepts of command and event.
Command vs. Event
A command is initiated by a user or a technical component, which asks a system to perform an action.
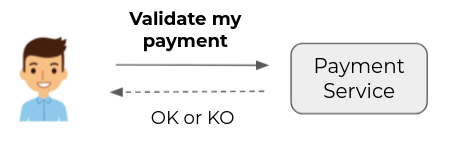
An event is initiated by the system to express the fact that something has happened.

The fundamental differences between the two are:
- When the command is launched, the action is not yet performed and the state of the system is not yet affected. It may or may not succeed and it can be retried by modifying it (if necessary).
- When the event is instantiated, the action is already performed and the state of the system is already affected. The event is therefore immutable and will have to be processed.
Orchestration vs. Choreography
In a command-based scenario, the service requested by the initial command drives the action of the other services involved.
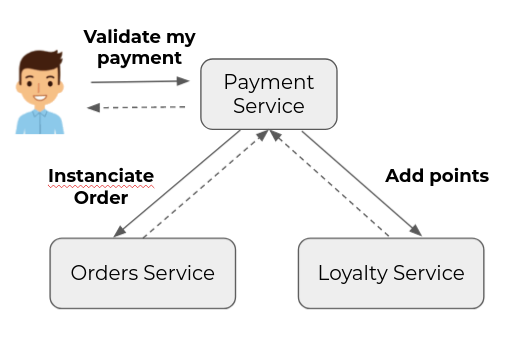
Here, when the payment service processes the validation request, it will ask the other services to trigger the actions that follow the validation action. For example, an instantiation of the order corresponding to the payment and the addition of loyalty points. It is therefore the payment service that orchestrates the scenario in this case.
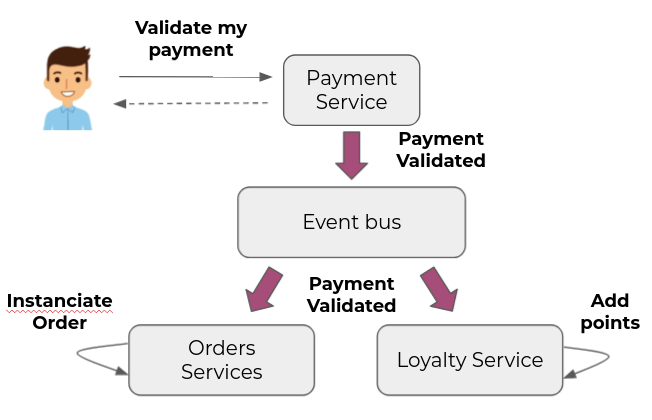
Let's take the same scenario with an event-driven approach. Once the payment service has processed the validation request for which it is responsible, it will issue an event on an event bus. This event will be consumed by the order and loyalty services to trigger the actions that follow the validation of a payment.
These services act independently from an event, which can be assimilated to a choreography.
Benefits
The first benefit that appears in the previous example is the decoupling of the components. The payment service performs the processing for which it is responsible and notifies the user that it is finished, without worrying about the actions that must follow the payment validation. It can also respond to the user's request even if the order and loyalty services are unavailable, which improves overall resiliency.
In addition, events become pivots around which the architecture can be built, making it more flexible. This makes it possible to quickly build new use cases from the events that occur in the system. They can also be used to feed data pipelines or real-time analysis tools. As an example here, to analyze payment volumes by time slots.
Another benefit is greater scalability. In other words, the ability to independently multiply instances of services, depending on their workload. For example, “N” instances of the order service can be added if the processing triggered by the event is long and/or if the overall load is high.
Finally, the events allow us to use less batch processing and to process in real-time what is happening in the system.
Tradeoffs
As with any architecture choice, the benefits come with trade-offs. The main challenges in implementing an event-driven architecture include the following:
First, the state of the different services is out of sync for a certain period of time, corresponding to the delay between the update of the state on the producer side of the event and the update of the state in the consumer service of the event, we speak then of eventual consistency. This aspect must be integrated into the design of the processes and care must be taken to ensure that the synchronization delay is not too great by ensuring that the consumption of events is faster than their production.
Secondly, it will be necessary to ensure that all events are routed and processed, otherwise two services could find themselves out of sync for certain entities. It will be necessary to be vigilant about the parameterization of the event bus, as well as the applications that produce and consume events. In addition, it is necessary to manage errors during the consumption of events, with replay strategies for recoverable errors (e.g., unavailable database) and discard strategies for non-recoverable errors (incorrect event format, or unexpected event, for example).
Finally, to monitor the various problems that could occur in the routing and processing of events, an effective monitoring system must be set up.
Kafka as an Event Bus
Apache Kafka is a distributed event streaming platform, originally developed by LinkedIn and open sourced since 2011.
It is used by a vast number of companies to build high-performance data pipelines, enable real-time data analysis, and integrate data from critical applications.
Why Kafka?
Kafka was built from the ground up to publish and consume events in real-time on a large scale due to its distributed nature.
Events that are published in Kafka are not deleted as soon as they are consumed, as in messaging-oriented solutions (e.g., RabbitMQ). They are deleted after a certain retention time (or not at all as in event sourcing). During their lifetime, they can be read by several different consumers, thus responding to different use cases, which corresponds well to what we want to do in an event-driven approach.
Kafka comes with a rich ecosystem of tools, such as Kafka Connect, which allows you to capture events from a third-party system (e.g., database, S3, etc.) and send them to a Kafka topic, or conversely, to send events from a Kafka topic to a third-party system.
Kafka Streams allow you to work on event flows (stream processing) and to create new flows from existing ones, which makes it possible to make the most of the data in transit with great flexibility.
Event
An event in Kafka is mainly composed of:
- a key
- a value
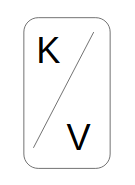
Both can be composed of a simple field type (String, Long, etc.) or a more complex data structure.
These events are written in a stream, hence the term "event streaming." Each new event is added at the end of the stream and old events are never modified.

If the events concern an entity (e.g., a product) and this one changes state several times, several events will be produced to materialize the successive states.
In Kafka, this event flow is implemented as a commit log.
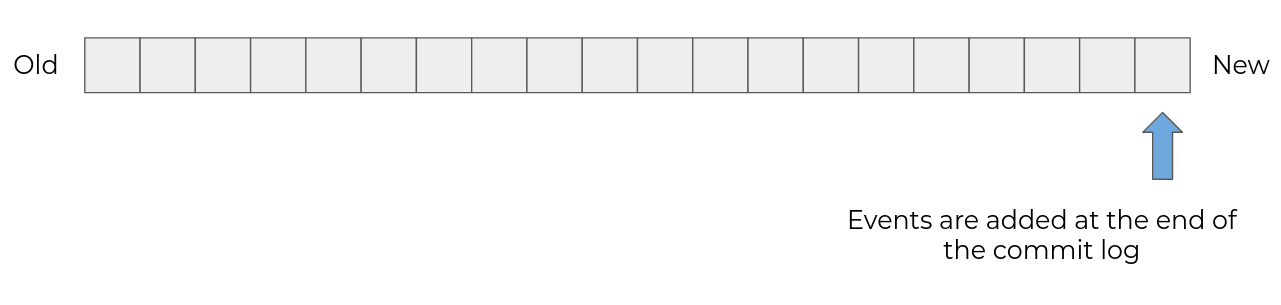
This is the central notion of Kafka.
Topics
In an application, events will concern several types of entities (user clicks, orders, customers, etc.).
To isolate them from each other and allow consumers to consume only the ones they are interested in, the events are divided into topics.
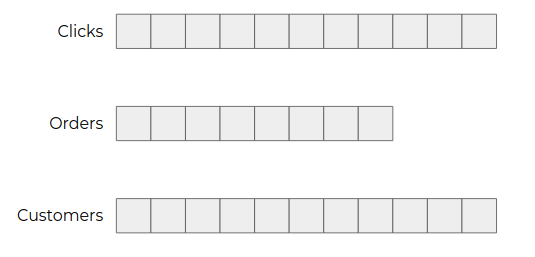
Topics can be compared to database tables since they aim to group similar data.
Partitions
To allow the consumption of a topic by several instances of a consumer, topics are split into partitions. This is what will allow Kafka to handle events at a large scale.
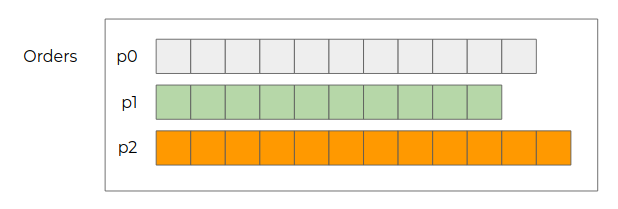
Production of Events
When an application is going to produce events in a topic, it can influence the target partition that will receive the event:
- Either by explicitly indicating the target partition number
- Either by key if it is defined; events with the same key will be written in the same partition
- Otherwise, in homogeneous distribution (round-robin)
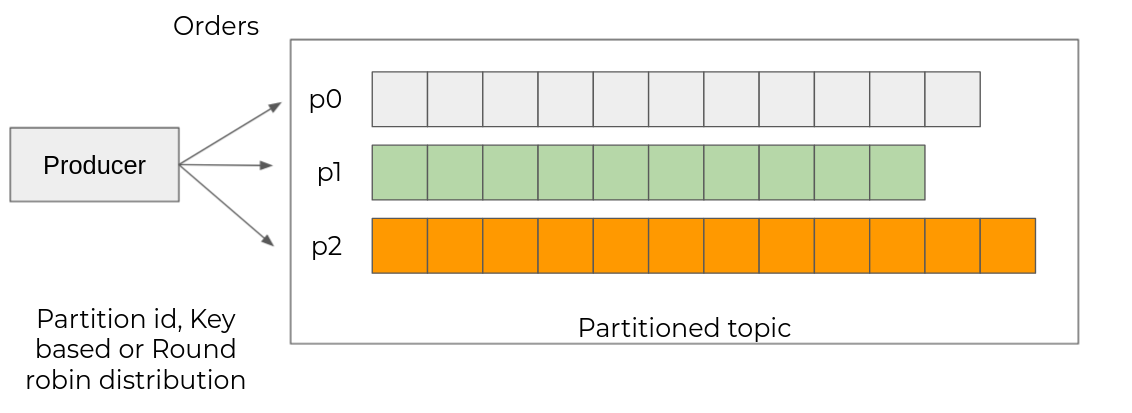
Events Consumption
Different Consumers
Several different applications will be able to subscribe to the same topic. Each one will then read all the scores at its own pace. Each event will then be consumed by MyAppA and MyAppB.
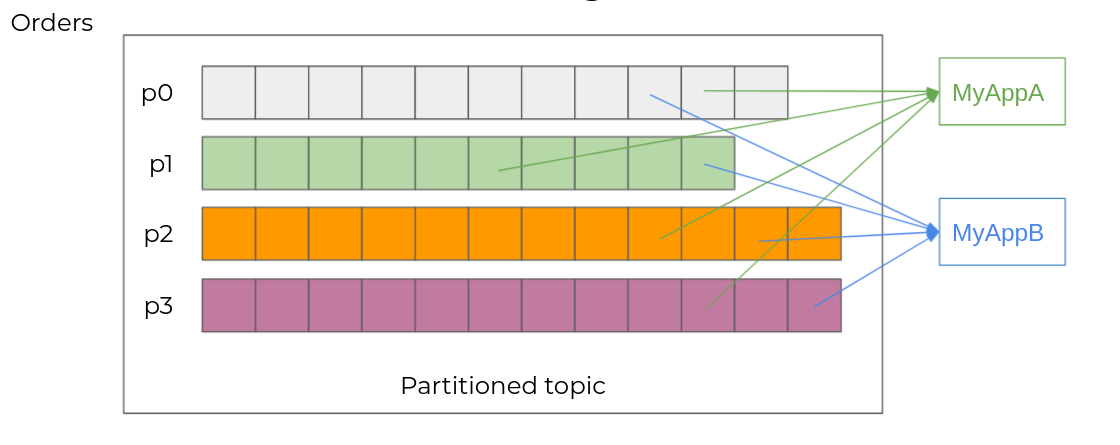
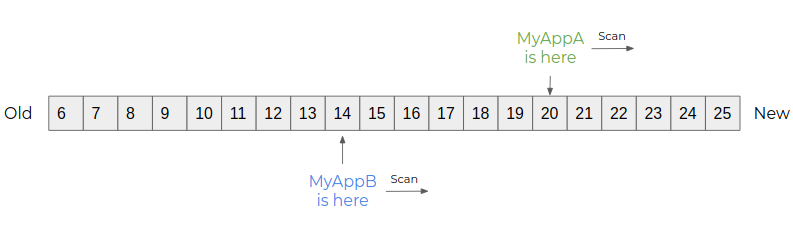
To do this, Kafka will associate each event with a unique number within its partition: the offset. Each consumer will be able to consume the flow of events at its own pace, by recording its progress in Kafka.
Multiple Identical Consumers
To multiply the processing capacities, it is also possible to add several instances of the same consumer, which will then be registered in the same consumer group. Each instance then consumes a subset of the topic's partitions, equally distributed among the consumers.
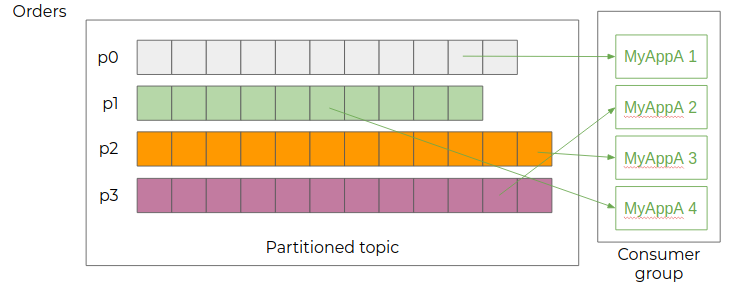
The number of instances in a consumer group is not limited, but if it exceeds the number of partitions of the consumed topic, the excess instances will not have any partition assigned.
By using the key distribution at the production level, we ensure that all the events concerning the same entity (thus with the same key) will be processed by the same consumer instance. And since Kafka guarantees the order of events within a partition, they can be consumed in the order of their emission. This is particularly important for events whose order is important (e.g., order created, order modified, order cancelled, etc.).
Conclusion
We have seen in this section that an event-driven architecture is an important paradigm shift that aims at building a system based on the events that occur within. This makes it possible to build services that react in real-time to these events.
Kafka is particularly well-suited to implement this type of architecture by allowing events to be exposed in a structured way and to be easily subscribed to without impacting the producing applications. It also allows for consumer scalability.
In the second part of this article, I will detail some implementation elements to ensure the transmission of events in a reliable way and facilitate the adoption of the architecture by other teams.




Comments