

November 2, 2021
In the first part of this article, we saw what an event-driven architecture is and how Kafka can be used to transit and expose events.
In this next section, we will discuss some important points to consider when implementing event flows.
Two major issues are important to consider when launching an event-driven architecture:
- Reliability: all events produced in the context of critical flows must be processed
- Adoption: the foundation and the tools put in place for a first use case must facilitate the adoption of the architecture by other teams, to allow its extension/generalization
Reliability / “At-Least-Once Delivery”
In an event-driven approach, all events must be routed and processed, otherwise the state of the producing service and the consuming service(s) of the event will be out of sync.
An "at-least-once delivery" guarantee must be implemented to ensure:
- That an event cannot be lost once issued
- That each event is properly processed
- That an event is processed only once, even if it is issued several times
Events Durability
To ensure the durability of the data that passes through Kafka, it is necessary to instantiate several server nodes, commonly called "brokers", and duplicate the topic data on them. This is possible thanks to the internal replication mechanism of the Kafka cluster. Thus, it will be possible to lose one or more brokers depending on the configuration without losing the data.
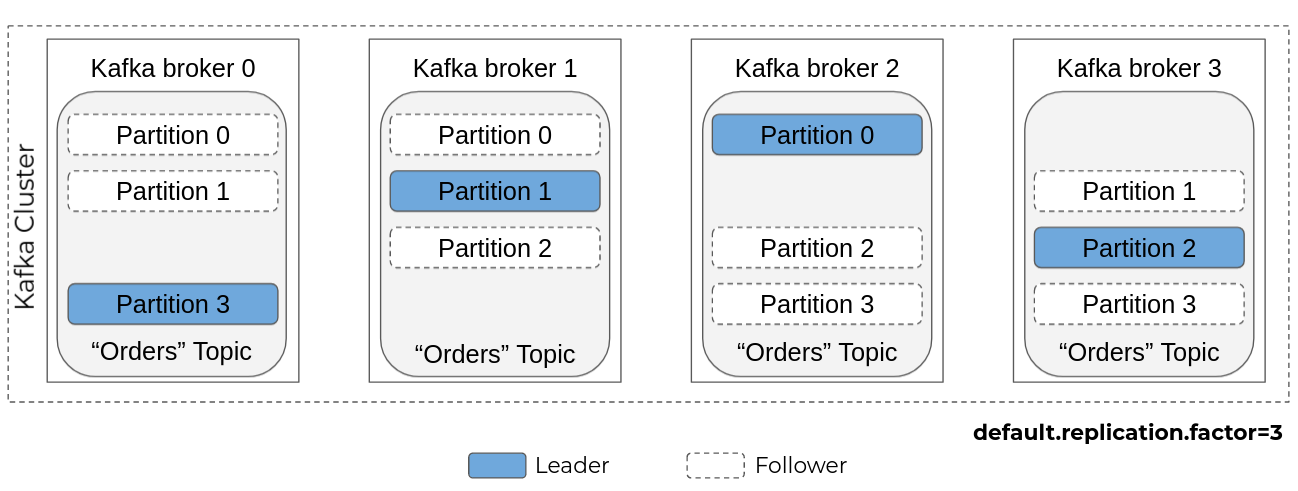
In the example below, we have a cluster of four (4) Kafka brokers, with a replication factor of three (3) for the topic "orders", which has four (4) partitions:
- Each node is "leader" of a partition (equally distributed among the nodes of the cluster)
- Each partition is replicated on two (2) nodes (three (3) times in total) thanks to the "default.replication.factor=3" parameter which can be defined topic by topic and which is 1 by default (no replication).
In order for this replication to be effective at all times and to avoid event loss, especially during the production of an event, the broker must acknowledge the writing only after having carried out the replication.
To do this, the topic must be configured with the "min.insync.replicas" parameter to set the minimum number of replicas to be kept in sync to 2, and the producing application with the "request.required.acks" parameter to all.
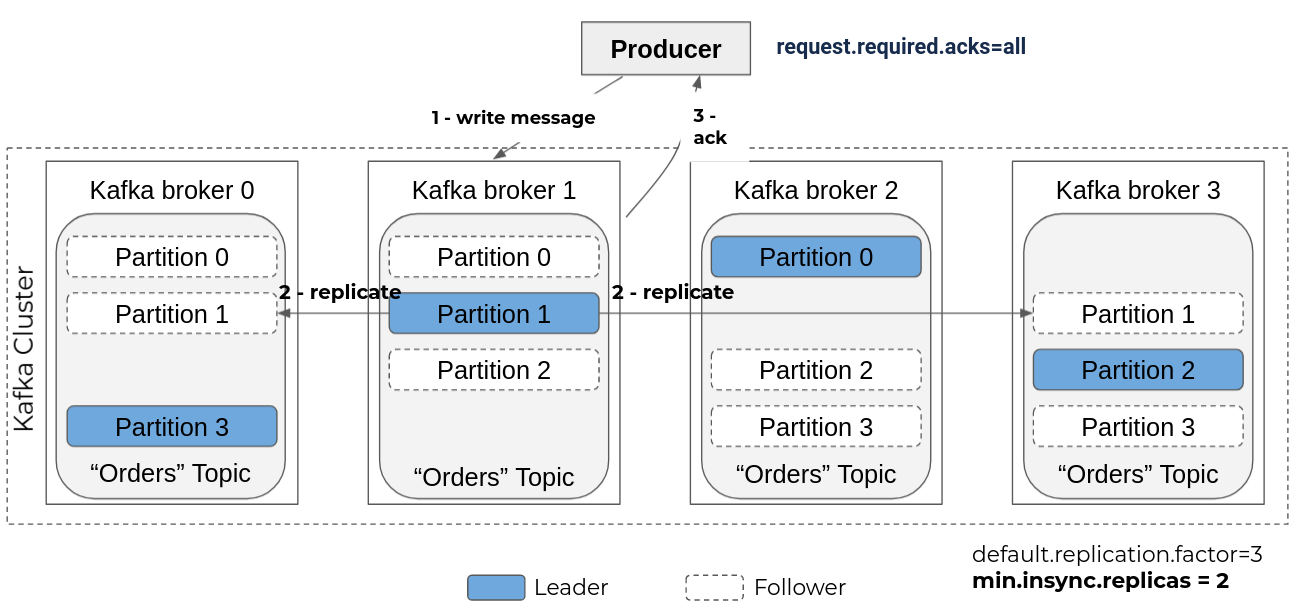
Thanks to these settings, if broker 3 becomes unavailable for example, the data of partitions 1, 2, and 3 are not lost because they are replicated on the other nodes.
Another node will then be elected leader for partition 2 (here broker 1 or 2, for example), and partitions 1 and 3 will be replicated on another node.
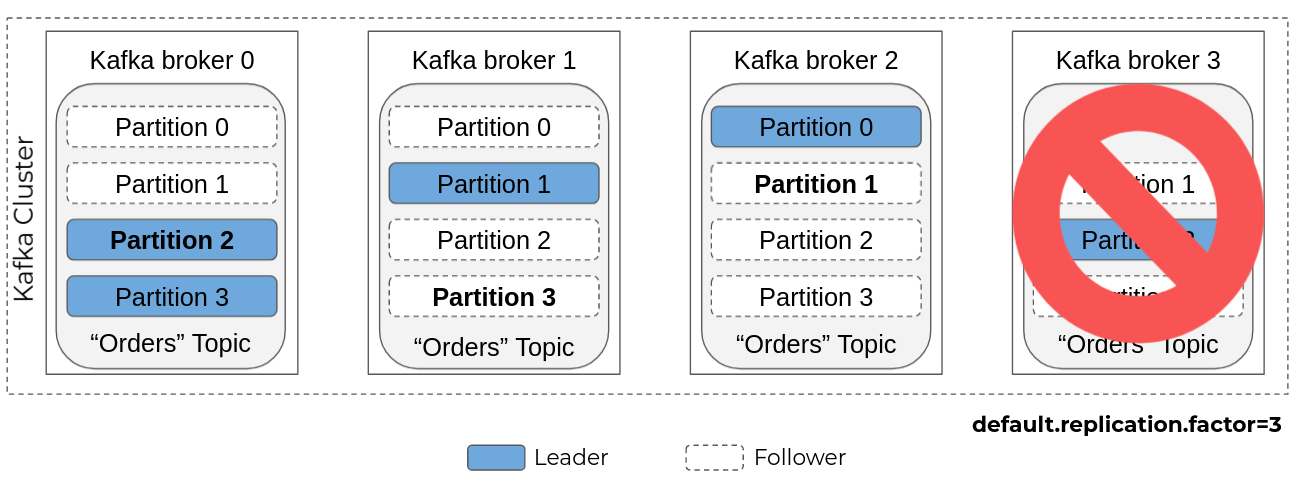
If another broker becomes unavailable, the topic becomes read-only because there are not enough nodes to host three replicas of its partitions.
Guaranteed Processing of Events
The applications that consume the events published on a topic are responsible for communicating their progress to the broker. To do this, they trigger a "commit" operation with the broker by indicating the last offset read. The broker will then store it in a technical topic "__consumer_offsets" which will centralize the progress of all the consumers of this broker.
By default, the Kafka client embedded in the consumers will perform a periodic "commit" (autocommit) without ensuring that the consumed messages have actually been processed.
In the context of an event-driven architecture, each message must be processed or the state of the producer and the consumer of the event will be out of sync.
To guarantee the processing of each event, event consuming applications must therefore:
- disable autocommit: enable.auto.commit=false
- perform an explicit commit at the end of the processing
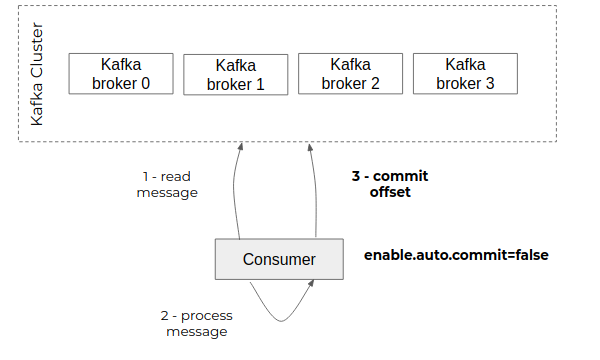
This guarantees that each event that has been committed has been taken into account by the consumer and in particular that the necessary data has been recorded on the consumer side.
Idempotence
Internal replication and manual commit ensure that an event is transmitted from the producing application to the consuming application and processed by the latter.
However, as the title of this section suggests ("at-least-once delivery"), it is possible that some events are received twice.
Example #1 (technical duplication):
- A consumer processes a series of events
- The consumer crashes after processing an event “E,” but before committing it
- Kafka will then detect that the consumer is no longer responding and will rebalance the partitions between the remaining consumers
- The consumer that takes the partition containing “E” will then consume it again, even though its data is stored in the database
Example #2 (functional duplication):
- A producer produces an event “E1” with a key “C1” corresponding to its business identifier
- A consumer will consume “E1” and persist its data
- The same producer produces an event “E2” with a different technical identifier, but with the same key “C1” (because of a fragile implementation, such lack of control before emission, or for reasons of concurrent access to the same entity.)
- The consumer will consume “E2”
Therefore, it is necessary that the processing of an event be implemented in an idempotent way, i.e., in such a way that a second occurrence of the event has no effect on the consumer data.
In the example below, the processing implements two levels of control:
- Technical deduplication based on the technical identifier of the message (via the technical identifier of the event, transmitted via a header)
- Functional deduplication based on the functional key of the message (via the event key, carrying the necessary information)
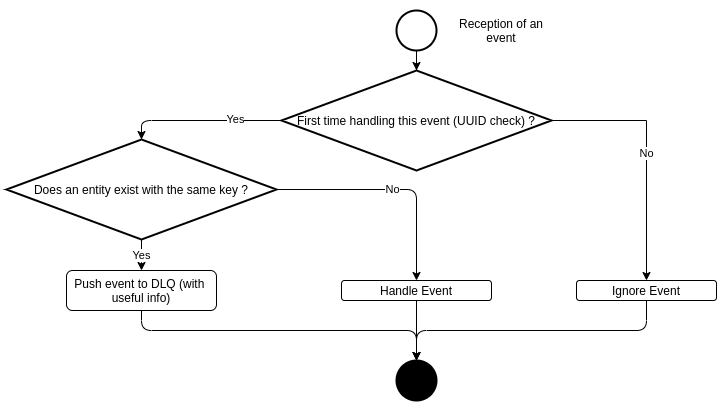
The first level can be implemented by storing the list of the last events received in the database and the second by checking the uniqueness of the keyby using a unique key constraint on the database.
In the case of a technical duplicate, it is sufficient to ignore the event and perform a commit.
In the case of a functional duplicate, it should be placed in a Dead Letter Topic, which will contain the events that could not be processed for manual analysis. Unless there is an implementation error, no event should be in this topic. If this is not the case, the cause of the problem must be corrected and these events must be consumed again or the desynchronization of the data between producer and consumer must be corrected manually.
Facilitating Adoption
Whether a system is built from the ground up with an event-driven approach or is adapted to embrace this approach, it is important that new flows can be easily integrated, including automating deployments and preparing message format governance
Events Format
Serialization / Deserialization
For performance and data volume reasons, messages are transmitted in binary in Kafka. The events (key on one hand and value on the other) must therefore be:
- Serialized when they are produced
- Unserialized when they are consumed
Kafka provides a number of serializers and deserializers for common types (String, Long, etc.). For more complex / composite contents, you must use serialization libraries like Avro / Protobuf or JSON Schema.
Apache Avro has several advantages, including:
- Compact binary format
- Being well-integrated in the Kafka ecosystem / tooling
- Ability to generate objects (Java, for example) to manipulate events in the application code
- Allows you to control compatibility when the format of an event changes
- The schema can be historized in configuration management
Schema Registry
The schema registry is a component that allows the schema of events passing through the system to be hosted centrally, thus ensuring that event producers and consumers use a common exchange format.
It also allows you to control changes made to a schema, guaranteeing upward or downward compatibility, depending on whether you want to first update the applications that produce or consume the associated event.
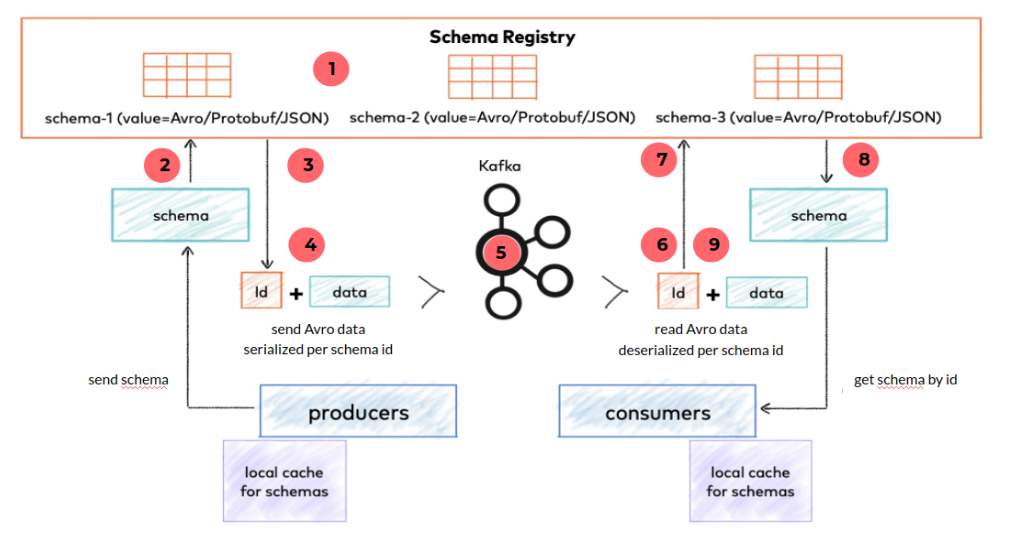
- Publication of schemas with CI/CD
- The producer sends the schema of the event it wants to publish to the registry to:
- check the compatibility with the current schema
- retrieve its identifier
- The schema registry returns the schema identifier
- The producer serializes the data in binary and adds the schema identifier at the beginning of the event
- The event is sent to the Kafka topic
- The consumer extracts the schema identifier from the event
- The consumer sends the schema identifier to the schema registry
- The schema registry returns the associated schema
- The consumer can deserialize the binary data into a Java object
To avoid requesting the schema registry each time an event is published or consumed, the producers and consumers keep the useful data in cache.
Automated Deployment
Schemas
By default, Kafka clients are configured to automatically publish the schema when an event is produced (auto.register.schemas=true).
In production, it is recommended to publish schemas upstream, via CI/CD after creating or modifying them. The schema registry then checks the compatibility of the changes with the strategy defined for the associated topic (example: with a BACKWARD compatibility aiming at updating consumers before producers of an event, only deletions of fields or additions of optional fields are allowed, which allows the producer to continue working with the old version of the schema).
To avoid the heavy syntax of Avro schemas, it is possible to use the IDL Protocol format which is more condensed and allows you to generate Avro schemas. Each event can then be stored individually in configuration management under its IDL version.
Example of a deployment pipeline:
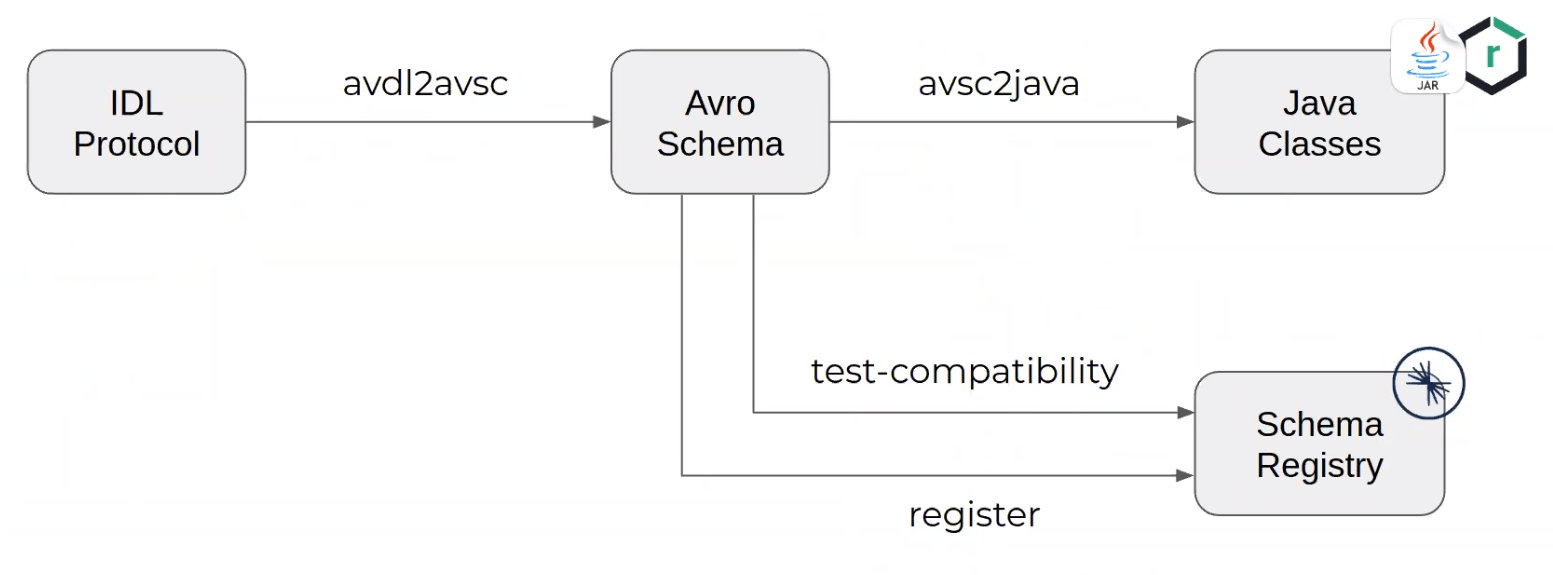
avdl2avsc : uses the "idl2schema" command of the "org.apache.avro:avro-tools" utility
avsc2java : generate the sources via the goal "schema" of the "avro-maven-plugin" plugin
test-compatibility : use the "test-compatibility" goal of the kafka-schema-registry-maven-plugin
register : uses the "register" goal of the kafka-schema-registry-maven-plugin
Applications can then declare a dependency on the events they produce or consume via Maven.
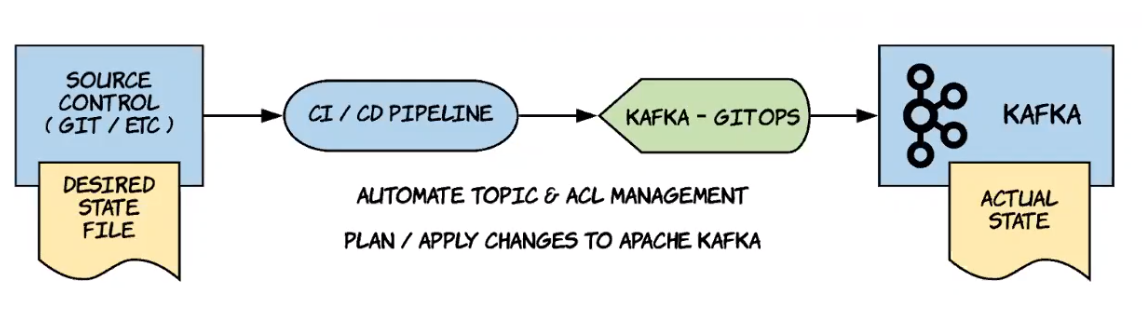
Topics and ACLs
Topics and ACLs can be deployed using Kafka GitOps, an open source product available here: https://github.com/devshawn/kafka-gitops.
Kafka GitOps allows to define a desired state via Yaml files:
- Topics and associated settings
- Services using topics and associated accounts
It provides a CLI that allows you to apply changes from a previous state.
Conclusion
The elements presented in this section allow us to tackle the main challenges of implementing an event-driven architecture with Kafka.
The routing and processing of events is guaranteed by the multiplication of brokers and the 'at-least-once delivery' configuration of Kafka. It is also necessary to guard against the occurrence of duplicate events that will inevitably occur due to the distributed nature of the system. This ensures that an event that occurs in the system is always taken into account by the components that subscribe to it and offers the same level of reliability as with synchronous exchanges.
Furthermore, the applications that make up the system must speak the same language, which must be able to evolve over time. We have seen here that the schema registry is a good way to achieve this by centralizing the format of all the events and by making it possible to test the compatibility at the time of the production of an event, as well as at the time of the publication of a new version of an event.
Finally, to facilitate maintenance and the construction of new event flows, it is necessary to industrialize the deployment of the various artifacts that make the event architecture work (topics, schemas, ACLs, etc.). This will make life easier for your teams that will have to build other flows on the Kafka technical base and facilitate the generalization of the event-driven architecture on the system.




Comments