

Earlier this year, Ippon published an Introduction to Snowflake post which provided a Snowflake Primer. I recently attended the Snowflake Partner Bootcamp in Baltimore, a four-day instructor-led training program and was allowed to learn even more. In this first of three posts, I am going to do an in-depth examination of Snowflake's unique architecture style and some of the benefits resulting from it.
Why Snowflake?
Snowflake's unique architecture allows both for easy data management as well as performance benefits and increased scalability as well as easy data management. Snowflake is also completely ANSI SQL compliant.
Architecture:
Snowflake uses a central data repository for persisted data that is accessible to all compute nodes and processes queries in Massively Parallel Processing compute clusters referred to as Virtual Warehouses. This architecture consists of the three layers stated below. In each of the following sections, I'll talk a little bit about what each layer contributes to Snowflake.
The Three Layers:
Database Storage
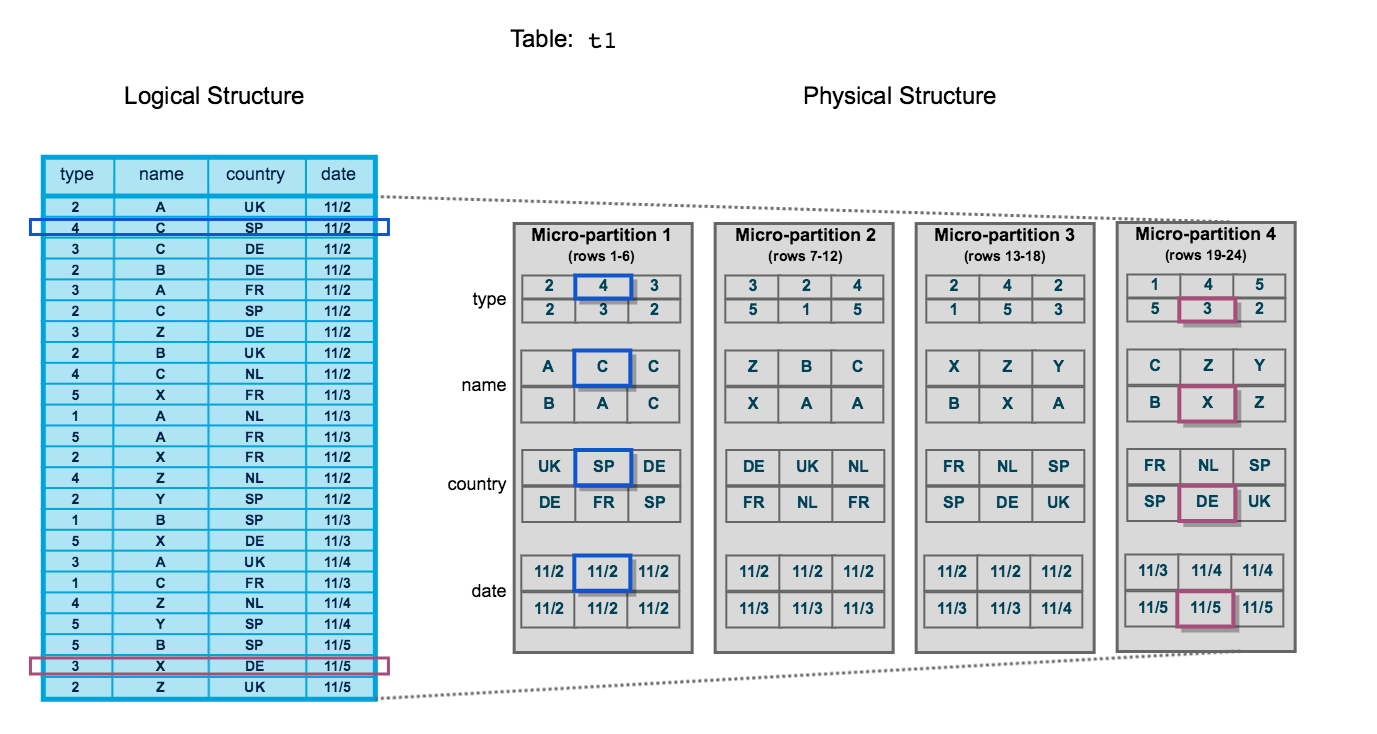
Snowflake automatically converts all data stored into an optimized immutable compressed columnar format (Micro-Partitions) and encrypts it using AES-256 strong encryption.Micro-Partitions (FDN [1])
When data is loaded into Snowflake, it is automatically divided into micro-partitions. Micro-partitions are automatically derived, physical data files which can contain between 50 and 500 MB of uncompressed data. Groups of rows in tables are mapped into individual micro-partitions and are organized in columnar fashion. These micro-partitions are not directly accessible or visible and are immutable. Any updates to data in a table will result in the deletion and recreation of Micro-Partitions to reflect the new data.
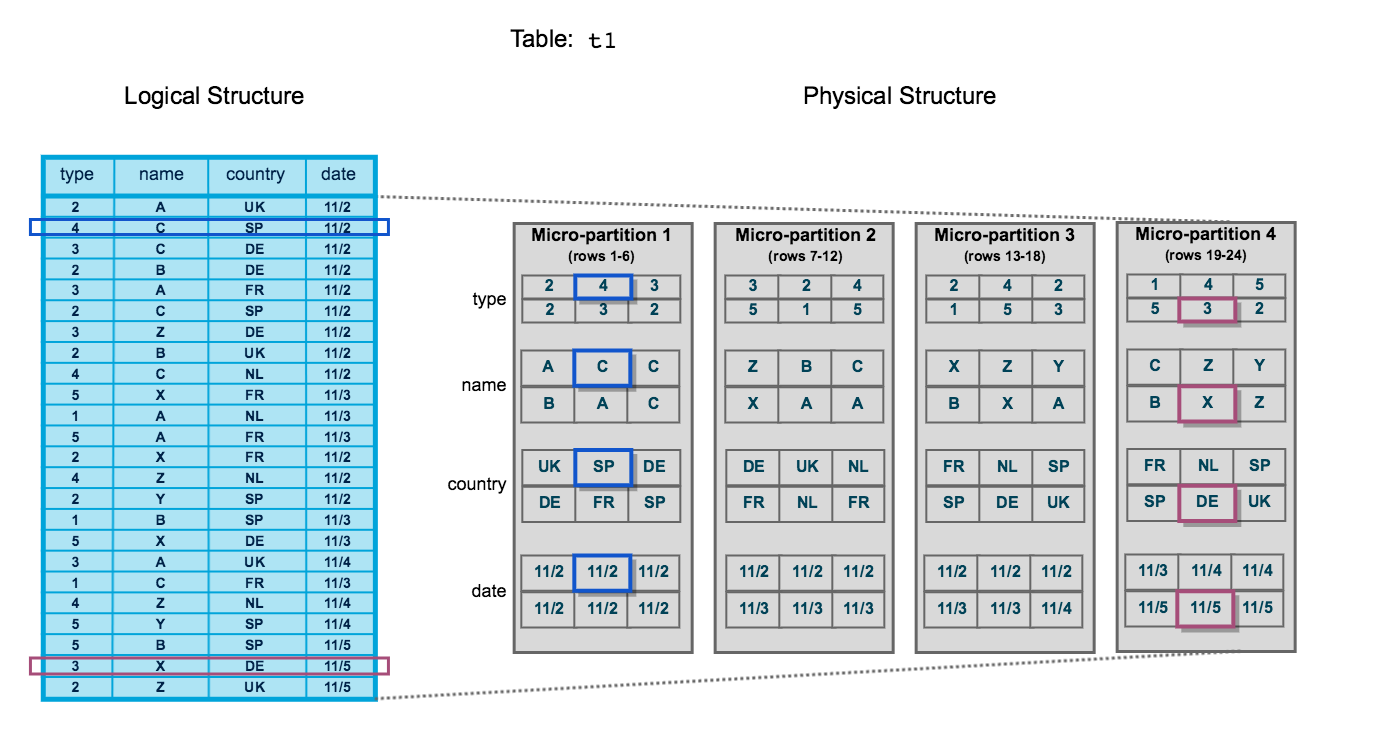
In the image above, the table has 24 rows which have been divided into 4 micro-partitions, organized and sorted by column. By dividing the data into micro-partitions, Snowflake can first prune micro-partitions not needed for the query and then prune by column for the remaining micro-partitions. This results in fewer records traversed and much faster response times.
Clustering
In addition to storing data as micro-partitions, Snowflake also sorts them according to natural dimensions. This Clustering is very important to Snowflake data storage, as it can greatly impact query performance. Clustering occurs upon ingestion. As data is loaded, Snowflake co-locates column data with the same values in the same micro-partition if possible.
Over time, as a table grows, its naturally defined clustering keys can become stale, resulting in reduced query performance. When this occurs, periodic re-clustering is required. During re-clustering, Snowflake uses the clustering key for a table to reorganize the column data. This deletes all affected records, which Snowflake will re-insert grouped according to the Clustering Key.
What is a Clustering Key And How Do You Select One?
A clustering key is one or more columns or expressions that can be used to sort a table. The number of distinct values in a column is a key aspect when selecting clustering keys for a table. It is important to choose a clustering key with a large enough number of distinct values to enable effective query pruning while containing a small enough number of distinct values to allow Snowflake to effectively group rows into micro-partitions.
You should select a clustering key for your table if queries on your dataset typically use sorting operations or if you typically filter on a column or several. If so, you should consider designating the column or columns as a clustering key for a table [2].
You should only cluster when queries will substantially benefit. Much of the time, Snowflake's natural clustering will suffice!
Time-Travel and Fail-Safe
Snowflake also provides two features which allow a customer to access historical data.
- Time-Travel facilitate the restoration of deleted objects, Duplicating and backing-up data from key points in the past and analyzing data usage over time.
- Fail-Safe data storage occurs for the 7 days immediately following the Time-Travel retention period.
Snowflake preserves the state of data for a data retention period (automatically set to one day for all table types). This data retention time limit cannot be disabled on an account level but can be disabled for individual databases, schemas, and tables.
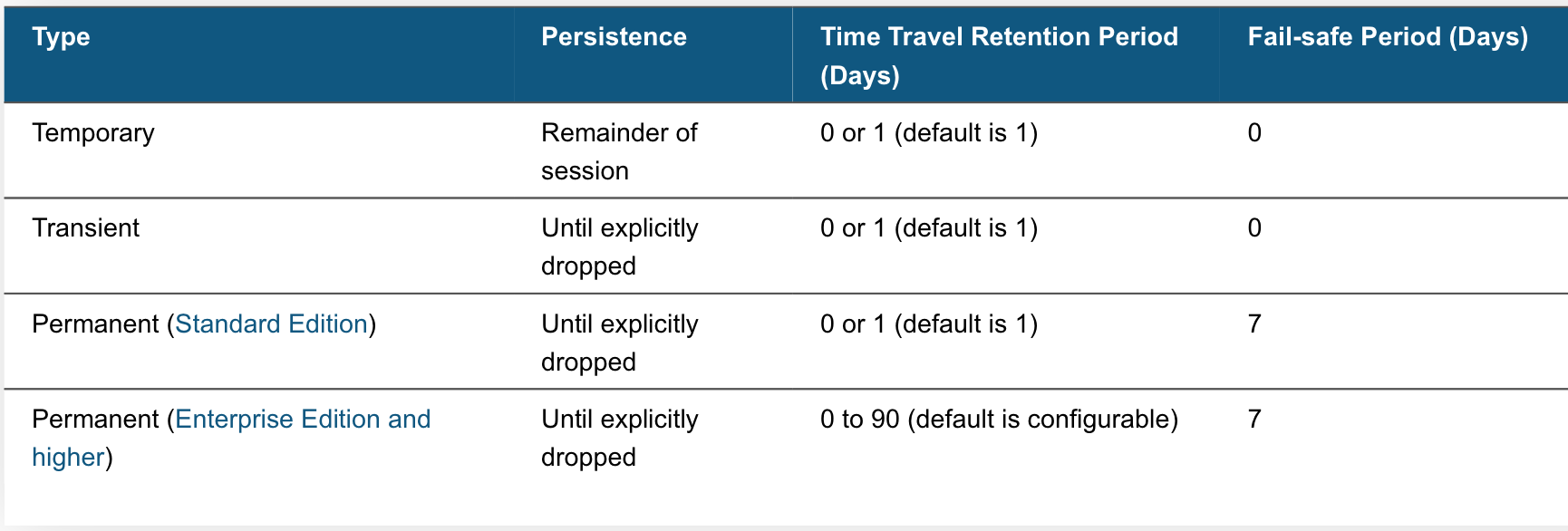
As seen above, all table types have a Time-Travel period, but only permanent tables have a Fail-Safe period. Fail-Safe is non-configurable and is not intended as a means for accessing historical data after the Time-Travel period has elapsed. Fail-Safe is intended for Snowflake to retrieve data that may have been lost or damaged due to extreme operational failures.
In case retrieval of data from Fail-Safe is necessary, you must speak to the Snowflake sales team.
Storage Costs Associated with Time-Travel and Fail-Safe
Storage fees are incurred for maintaining data in both Time-Travel and Fail-Safe. These costs are calculated for 24 hours from the time the data changed. Snowflake minimizes the amount of storage required for historical data by maintaining only the information needed to restore rows that were updated or deleted (This means that if a table were truncated or dropped, Snowflake will maintain the full copy). As Temporary and Transient tables only use 1 day of Time-Travel and no Fail-Safe, these should be used to reduce costs.
Temporary tables will be deleted once the session ends. One day of Time-Travel on Temporary Tables will only occur if the session is greater than 24 hours in length.
Query Processing
The layer of the Snowflake Architecture in which queries are executed using resources provisioned from a cloud provider.Virtual Warehouses
At their core, virtual warehouses are one or more clusters of servers that provide compute resources. Warehouses are sized in traditional t-shirt sizes, and each size determines the number of servers in each cluster of the warehouse. Size can be managed using SQL or in the Web UI.
| Warehouse Size | Servers per Cluster | Credits per Hour | Notes |
|---|---|---|---|
| X-Small | 1 | 1 | Default size for warehouses created in SQL using CREATE. |
| Small | 2 | 2 | |
| Medium | 4 | 4 | |
| Large | 8 | 8 | |
| X-Large | 16 | 16 | Default size for warehouses created in the UI. |
| 2X-Large | 32 | 32 | |
| 3X-Large | 64 | 64 | |
| 4X-Large | 128 | 128 |
It is possible for users to script warehouses of size up to 5XL. 4XL is the maximum size when creating warehouses from the Web UI. If a warehouse of size greater than 5XL is required, you will need to work with the Snowflake Sales Team.
Warehouses can be resized at any time with no downtime or performance degradation. Any queries already running against the warehouse will complete using the current resource levels. Any queued and new queries will use the newly provisioned resource levels.
By default, Snowflake will automatically suspend an unused warehouse after a specified time period. Similarly, Snowflake will automatically resume a warehouse when a query using it is submitted and the warehouse is the current warehouse for the session. Both auto-resume and auto-suspend can be turned on and off, though it is highly suggested that both are used since Snowflake will charge for all running warehouses.
Multi-Cluster Warehouses
Multi-Cluster Warehouses allow for the scalability of computing clusters to manage user and query concurrency needs. Typically, a virtual warehouse contains a single cluster of servers. By setting the minimum and the maximum number of server clusters, Snowflake will automatically scale warehouses horizontally according to demand.
Multi-Cluster Warehouses cost more than standard Virtual Warehouses since more clusters are running. This feature is only available for Enterprise Edition customers and above
Credit Usage and Billing
All costs for computing resources are based on Snowflake Credits. Credits are charged based on the number of Virtual Warehouses used, how long they run and their size. There is a one-to-one relationship between the number of servers in a warehouse and the number of credits they consume per hour. Warehouses are only billed when they are running. Credits are billed per-second, with a 60-second minimum. After 1 minute, all subsequent billing is per second.
Global Services
The Global Services layer coordinates and manages the entire Snowflake system. It authenticates users, manages sessions and secures data. The Global Services layer also performs query optimization and compilation, as well as managing Virtual Warehouses. Using the Global Services layer, Snowflake can ensure that once a transaction on a virtual warehouse is complete, all virtual warehouses see the new data.During this blog, we've examined each of the three layers of the Snowflake Architecture. We've learned about Micro-partitions and their benefits as well as some of the data-recovery features Snowflake provides. Stay tuned for the second part of this series where we will discuss Snowflake's cache structure for query optimization!
For more information on how Ippon Technologies, a Snowflake partner, can help your organization utilize the benefits of Snowflake for a migration from a traditional Data Warehouse, Data Lake or POC, contact sales@ipponusa.com.
-
FDN: Flocon de Neige, the proprietary file format which Micro-Partitions are stored as. ↩︎
-
When defining a multi-column clustering key, the order of the columns matters. Snowflake recommends ordering columns from lowest to highest cardinality. When using a particularly high cardinality column, it is recommended to define the clustering key as an expression on that column to reduce the number of distinct values. ↩︎




{kind=link}
Comments