
Simulating an Outage with AWS Fault Injection Service Part 2


In part 1 of this blog, we talked about what Chaos Engineering is and how AWS Fault Injection Service (FIS) can help you test your system for unexpected outages. If you are unfamiliar with these concepts, I suggest you go back and read part 1. In part two of the series, we are going to go through the process of setting up an experiment, both in the UI, and using the AWS CLI, and running that experiment in my environment.
WARNING!!!! AWS FAULT INJECTION SERVICE CARRIES OUT REAL ACTION ON AWS RESOURCES IN YOUR ACCOUNT. Therefore, before you use AWS FIS to run experiments in production, AWS strongly recommends that you complete a planning phase and run the experiments in a pre-production environment.
Creating an Experiment from the AWS Console
To get started, we will navigate to AWS FIS, and select Experiment templates. From there we can create a new template and have it target This AWS account. Depending on the structure of your AWS accounts, you may want to target multiple accounts, but for simplicity in this demo, we will stick to running experiments in the same account.
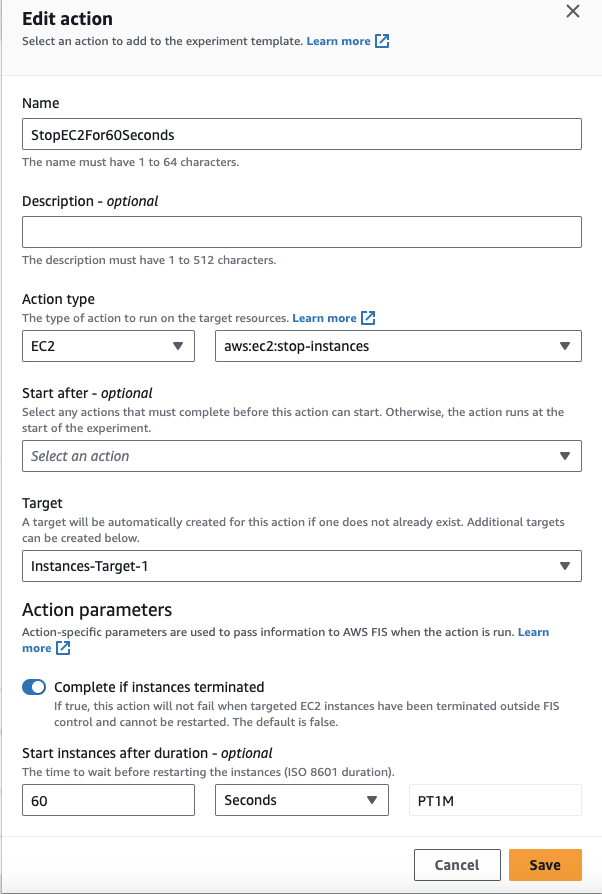
For our experiment, we are going to stop an EC2 instance for 60 seconds. After you create a name for your template, we will add an action. Again we will name it, and then select our action type. In this case, we are going to target EC2 with the aws:ec2:stop-instances. Finally, we can set the Start instances after duration to 60 seconds. This represents how long we want our instances to be stopped. We can save this step
We can now edit our target(s). You can either specify individual resources by ID, or my preferred way is by using tags. Select the Resource tags, filters, and parameters option and under resource tags, set the tags that you want to include in your experiment. I like to have a tag called AllowFIS and set the value to True that way only instances I have explicitly set to be allowed to be experimented on can be included.
After that, as with all things in AWS, we need a role. This role needs a trust relationship to allow fis.amazonaws.com to assume the role. And the role itself needs permission to perform the action we are requesting. In this case, stop and start instances. Depending on your organization, you may be able to use the Create new role for experiment option which will create the following role and trust.
Best practices suggest adding CloudWatch alarms that are used as stop conditions. If the alarm triggers, your experiment will terminate. For simplicity's sake, we aren’t going to set up any alarms.
Finally, we should set where we want our logs to go and set up tags. Neither of these is specifically required but are good practice. You can send your logs to either a log group (which is where I am sending mine) or a S3 bucket. Your tags should be set based on your organization’s policies.
Creating an experiment from the AWS CLI
Now let's create the same experiment as above but using the CLI. The CLI gives you the option to either pass in all of the required values as flags or bypass in a json object. I find the latter easier to read and reproduce so we will use that for this demo. To create the same experiment template, we will use the below json object as our input file.
We can then create the experiment template using the following comment aws fis create-experiment-template --cli-input-json file://experimentTemplate.json
After running this command, the important thing to take note of from the output is the id. We will use this shortly to execute our experiment. Don’t worry if you missed it. You can always retrieve the experiment template ID from the console or use the aws fis list-experiment-templates command.
Running the Experiment
Now that our experiment templates are set up, let’s run an experiment. For this demo, I spun up an EC2 instance and gave it the `AllowFIS` `True` tag that we defined in our experiment templates.
To start an experiment through the console, navigate to the experiment template you want to run, and hit `Start Experiment`. AWS will remind you again that you are about to perform actions on real AWS resources. Once you confirm that you understand this, you can start the experiment.
While the experiment is running, you can scroll down to see what resources are being impacted. In my case, I can confirm that only the single EC2 instance with my tag is being stopped. After the 60 seconds is over, the EC2 instance will start again.
To run the same experiment from the CLI, we can use the experiment ID from earlier and run aws fis start-experiment --experiment-template-id TEMPLATE-ID
Post Experiment Analysis
As discussed in part 1 of this blog, analyzing the results after your experiment is super important. Did your system perform as expected? Were there any gaps? In this experiment, our EC2 instance started back up after the experiment. We consider this a successful outcome for our purposes but it may not be based on your requirements. For example, if you had load-balanced instances and one of them stopped, did the other instances handle the load properly? Did your system autoscale to provide more capacity? When your stopped instance came back online, did you scale back down properly so you aren’t spending to have underutilized instances?
Conclusion
While a basic example of what AWS Fault Injection Service is capable of, hopefully, it can give you an idea of the types of things you do to test your systems. If you are eager to get started engineering Chaos with AWS FIS, then drop us a line at sales@ipponusa.com. Let us be your little chaos monkeys.



Comments