

Transform data with dbt
If you never used dbt before, you will first need to be more familiar with a few concepts like models and macros. I recommend reading the documentation for more details.
We first need a dataset, as a New Yorker I decided to pick a very controversial subject which is ... Pizzas! Our friend Liam Quigley went on a journey and ate 464 slices from multiple pizza places in NYC while logging everything. He also created a spreadsheet and for this blog I created a table in Databricks with the data:
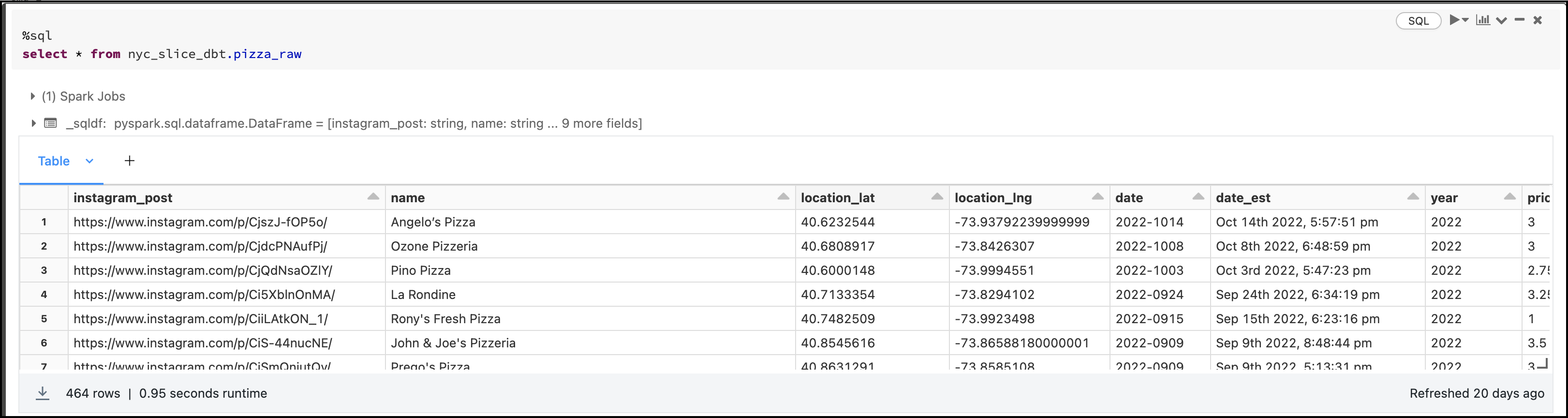
The second step is to create a dbt project that will transform our pizza raw table and create tables/views. I will use this dbt project on Github that has 3 models:
- pizza: A table that parses the date and add 2 columns (id and inserted_at)
- name_summary: A view that counts pizza places by name
- style_summary: A view that calculate the total spent by pizza's style
Why dbt and Databricks
I am a huge fan of using dbt with Databricks and it is very easy to have them running together thanks to the Databricks adapter. All models use Delta Lake out of the box and you also have a few extra features like snapshots and merge. Unity Catalog is supported and the adapter also includes SQL macros that are optimized to run with the Photon runtime.
It's safe to say that Databricks pairs very well with dbt and is also a good alternative to Delta Live Tables for your ETL pipelines. For more details on the configuration and how to use the adapter, please read this page.
Databricks Workflows
Databricks Workflows is a fully-managed orchestration service that is highly reliable and very easy to use. We're going to use that to create and run our dbt job directly on Databricks without configuring any external resources.
Before creating the dbt job, make sure that Databricks SQL is enabled for your workspace and that you have a SQL warehouse created. Also, your dbt project must be a Databricks Repos, it can't run directly from DBFS.
You can create a job in the Databricks UI or using the Databricks API. After creating the job, add a new task that uses the type dbt and link the source to your dbt project:
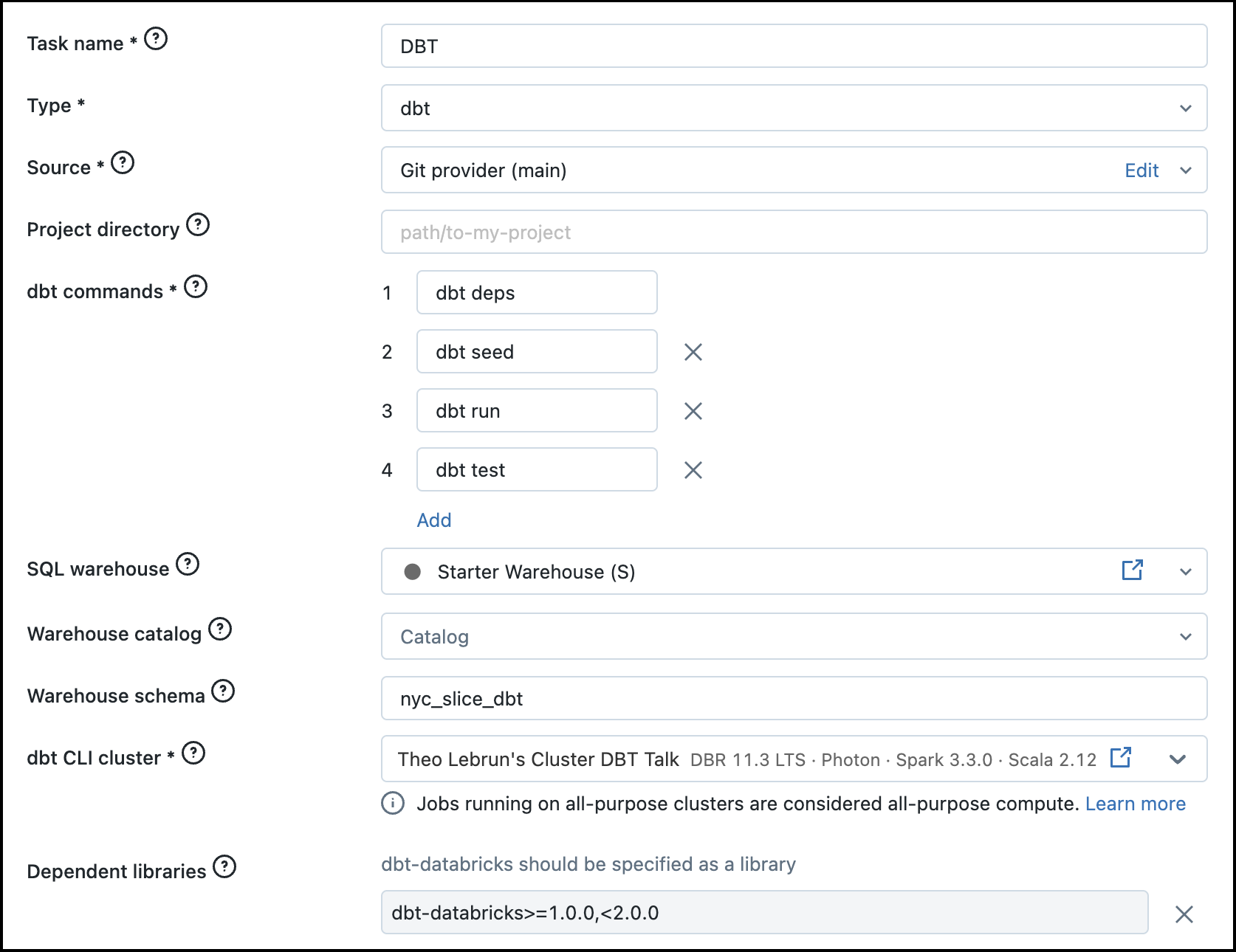
The dbt commands is very important and defines the order of the dbt commands run by the task. Feel free to specify any flags like --full-refresh for a full refresh or -m my_model for a specific model. Don't forget to set the correct schema and also the right cluster to run the dbt CLI on.
Run and monitor job
You can configure the job to run on a schedule or trigger it manually. After triggering a run, you can monitor its progress in the Databricks UI or using the Databricks API. You can view the job run history, logs, and metrics. You can also configure alerts to notify you when the job fails or exceeds a certain threshold.
The output of the Job run displays our dbt logs, and they can be inspected to make sure that everything was completed successfully.
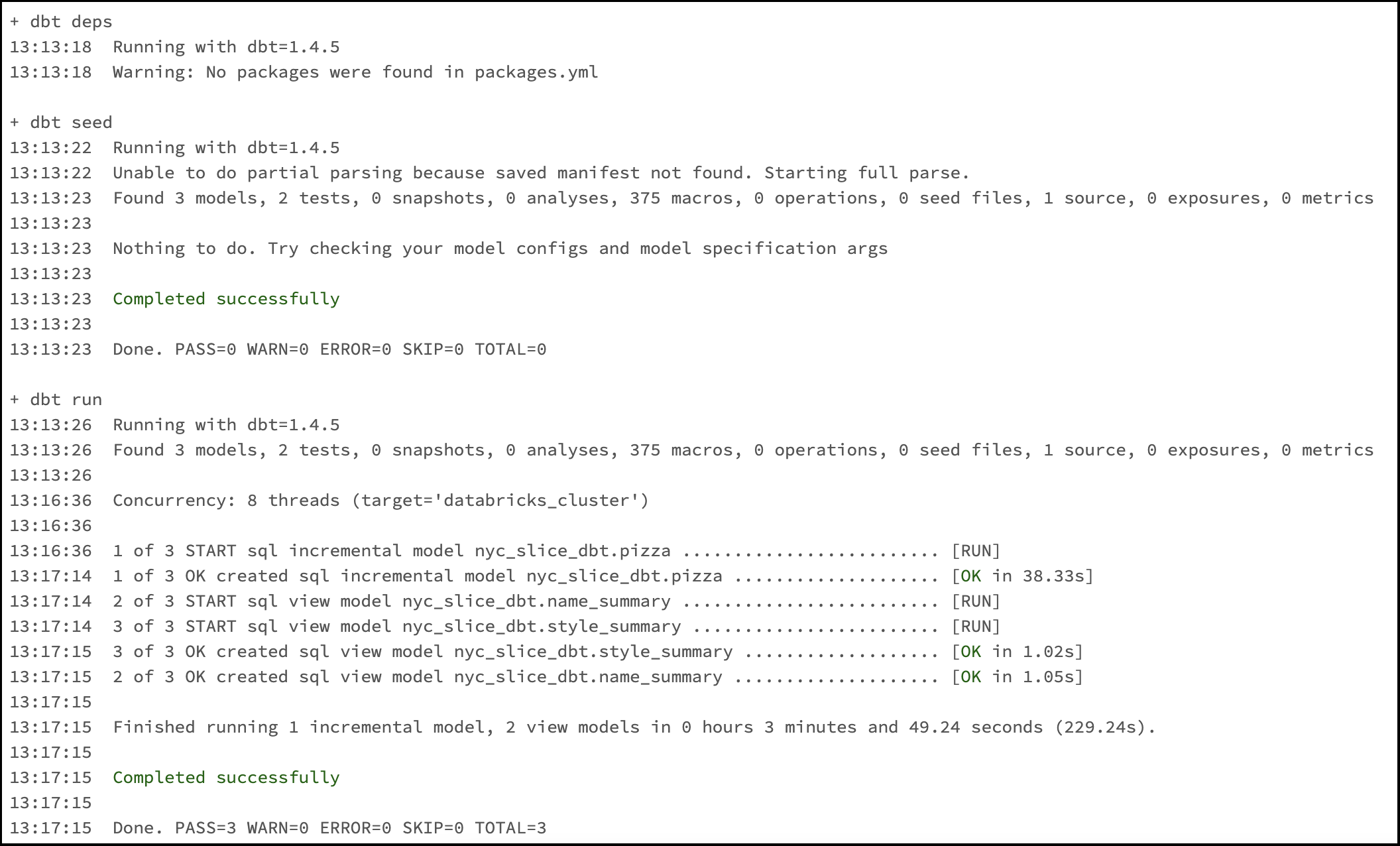
My dbt project is configured to run tests using dbt's generic tests, and we can see that the test unique_pizza_id failed:
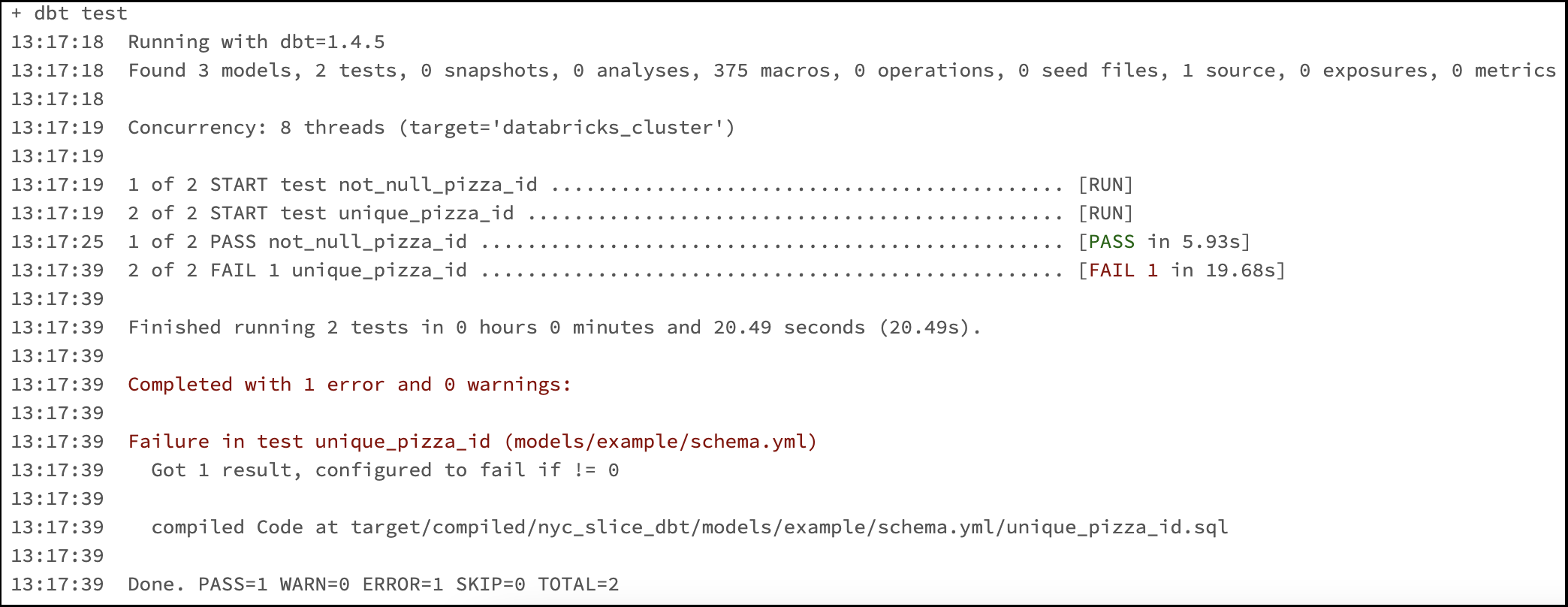
After a quick SQL query, we can find out what happened:
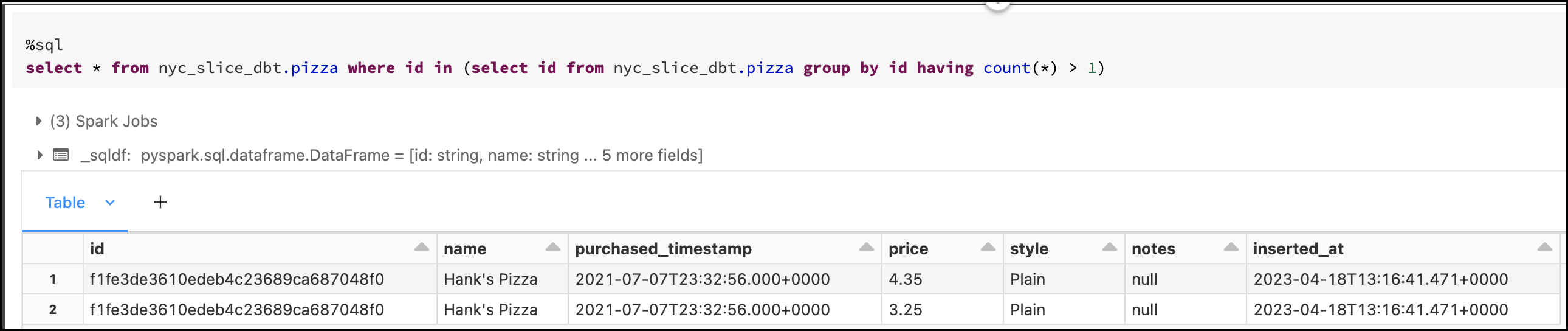
Looks like there is a mistake in our dataset unless it is normal to pay a different price for the same pizza...
Conclusion
Running dbt directly on Databricks using a job is a powerful way to automate your data transformation workflows. With Databricks, you can easily set up a cluster, create a dbt project, and schedule the execution of your dbt commands. Read this article for best practices and advices on running your dbt project with Databricks.
Need help with your existing Databricks Lakehouse Platform and dbt? Or do you need help using the latest Data lake technology? Ippon can help! Send us a line at contact@ippon.tech.




Comments