
Supercharge LLMs with Your Own Data: AWS Bedrock + Knowledge Base

Large Language Models (LLMs) refer to advanced artificial intelligence models that are designed to understand and generate human-like text at a massive scale. These models are trained on vast amounts of diverse language data, enabling them to grasp intricate language patterns, contexts, and nuances.
LLMs play a pivotal role in generative AI, as they possess the capability to generate coherent and contextually relevant text based on a given prompt or user input. LLMs can perform an array of tasks, including text completion, summarization, translation, and even creative writing. While LLMs are highly trained on large general datasets, if you want to use them for a specific use case, it is beneficial to provide additional data as context.
This approach is typically referred to as Retrieval-Augmented Generation (RAG). RAG is when models retrieve relevant information from additional data provided outside of their existing training before generating a response. This pattern is designed to improve the quality and context-awareness of generated content.
Please note there are a variety of mechanisms to provide additional data to an LLM (as well as a variety of LLMs). For this scenario, we utilized the following tools/technologies:
- Cloud Service: AWS Bedrock, Bedrock Knowledge Base
- Cloud Storage: AWS S3
- AI Model: Claude Instant v1.2 (via Bedrock)
- File Types: HTML, CSV
Gather Test Data
In this example, we used insurance claim data as our test dataset but you can always use your own data and business use case. If you would like to follow along with our sample data, all necessary files are available in this repository.
There are two CSV files with medical codes and descriptions for ICD codes, which describe the patient’s diagnosis, and CPT codes, which describe procedures and diagnostic care activities supplied by the provider, as well as some fake claims data in the form of HTML files, which were made to simulate 'paper claims'. For half of the HTML files we include the data in a table format while the others are purely text-based.
Here are examples of the 'paper claim' files:


Now that we have data to play around with, let's get started!
Load Data and Create a Knowledge Base
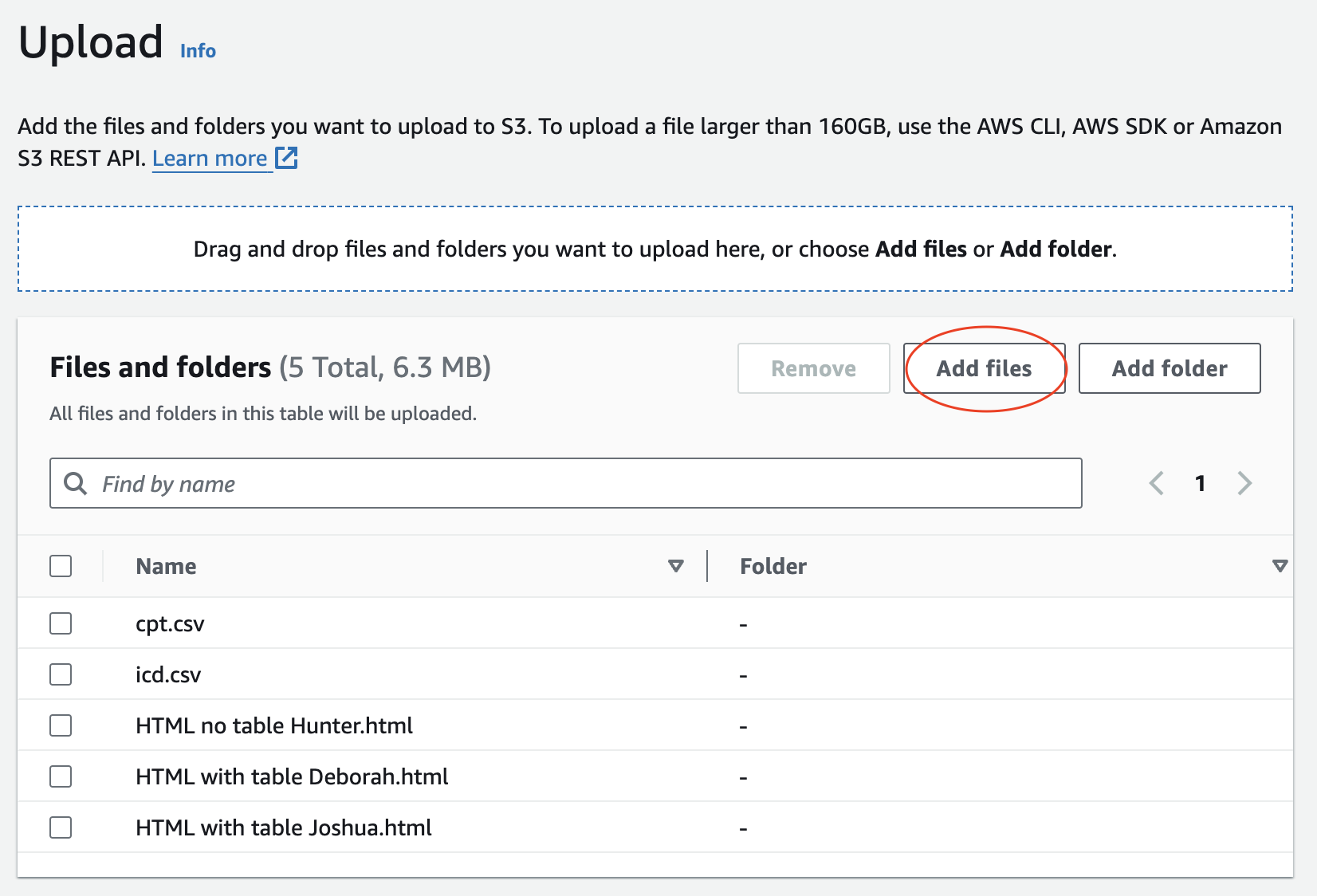
First, we will upload the HTML claim files and the two medical code CSV files to s3.
As mentioned before we will be utilizing AWS Bedrock for our Generative AI functionality. Bedrock is a fully managed service for building generative AI applications and offers multiple options for foundational models. The term foundational models broadly refers to models that serve as the foundation for natural language processing (NLP) tasks, which include LLMs. We will utilize Claude Instant, one of two versions of Claude offered by Anthropic. Read more about Claude here.
A feature of Amazon Bedrock is the Amazon Knowledge Base which streamlines the entire RAG workflow, from data ingestion to retrieval and prompt augmentation, eliminating the need for custom integrations. Users simply point the Knowledge Base to their S3 location containing the data desired, and it handles the rest: fetching data from S3, text conversion to embeddings, and storage in a vector database. Creating embeddings and a vector store is an important component for providing data to LLMs, but that is a larger topic for another blog! In the meantime, feel free to read more about both topics on AWS:
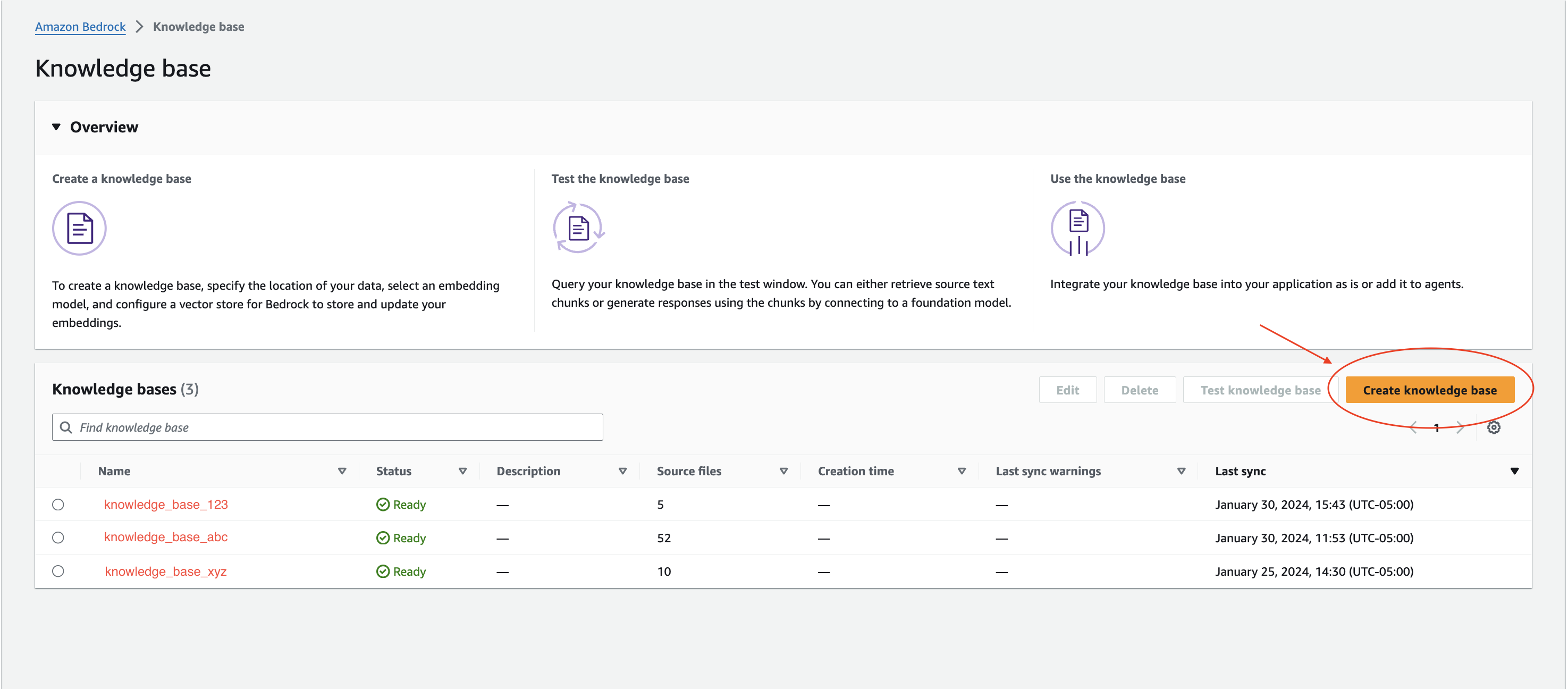
Ok, let's get back to it. In the AWS Console, navigate to Bedrock > Orchestration > Knowledge Base.

Create a new knowledge base.
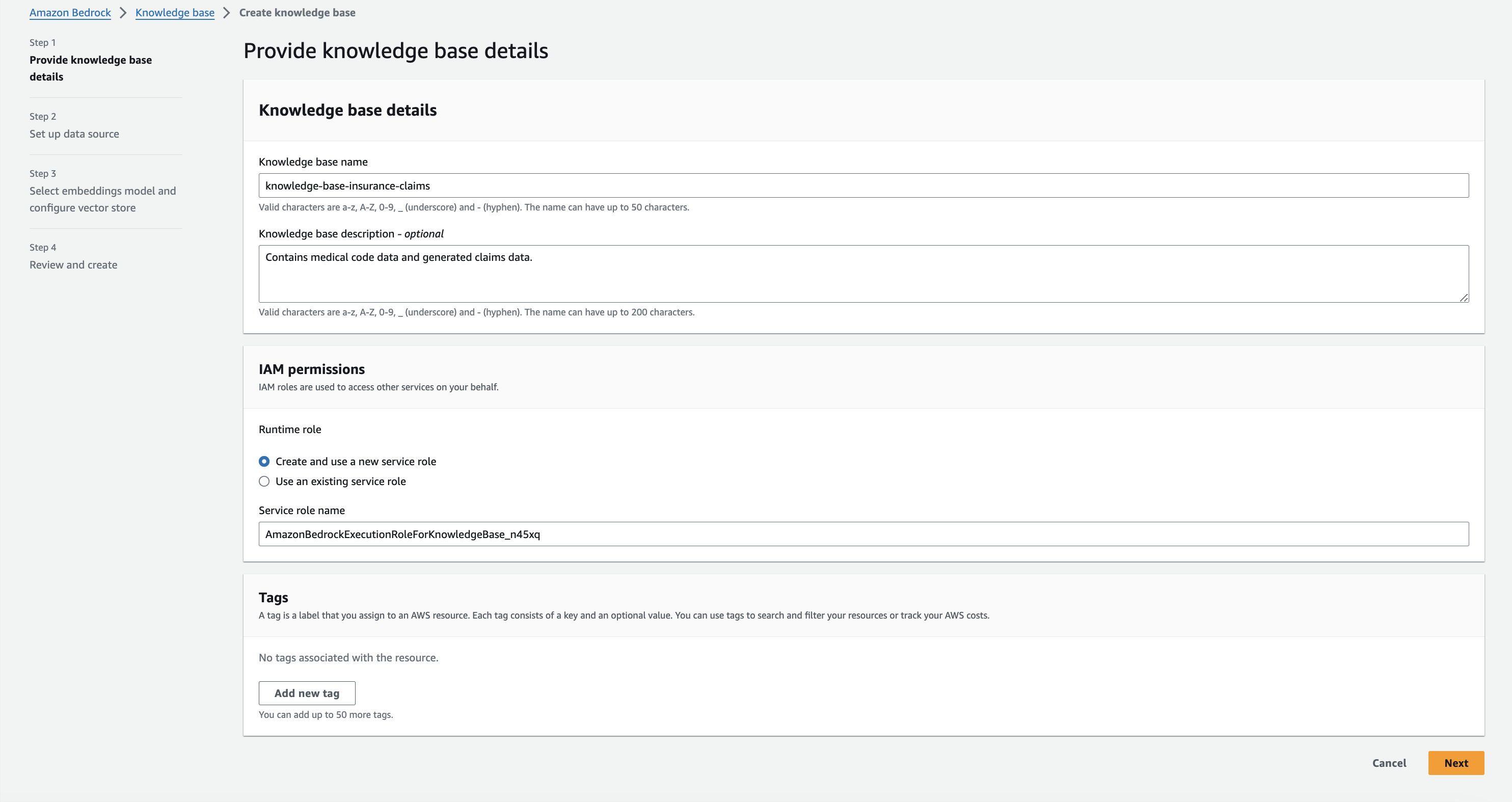
For this example, we are using the default option for IAM permissions, letting AWS create a new role for Bedrock.
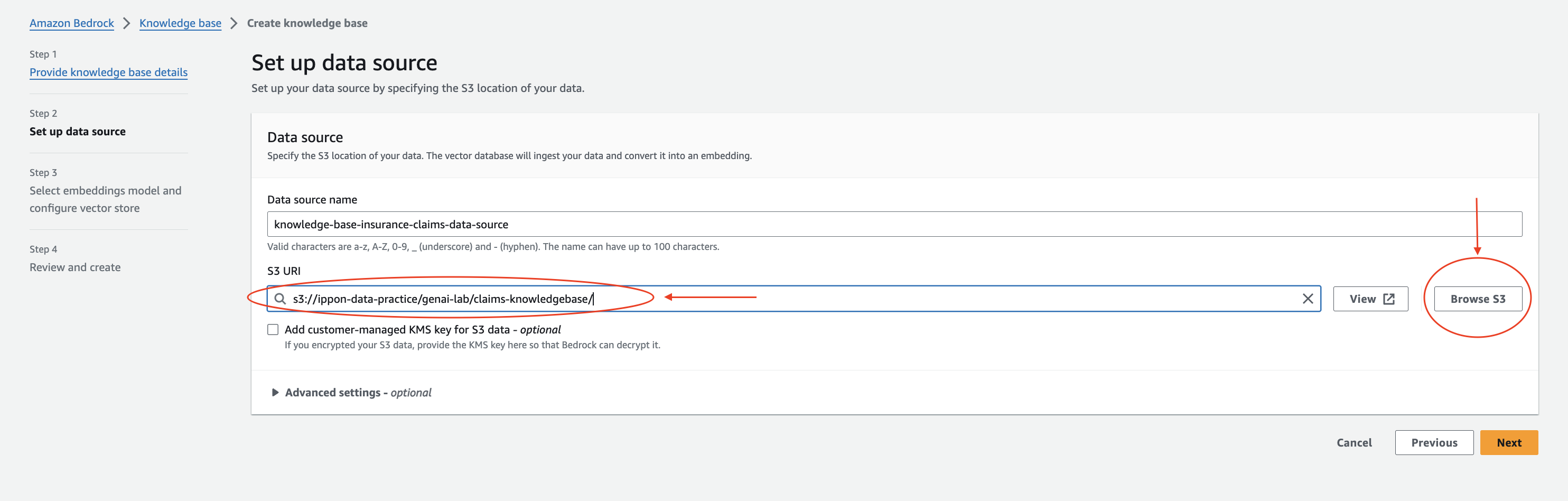
When prompted to set up the data source, browse S3 and select the location of the uploaded files.
Finally, for the embeddings model and vector store we will use Amazon's Titan Embeddings and the 'quick create' option for a vector store.
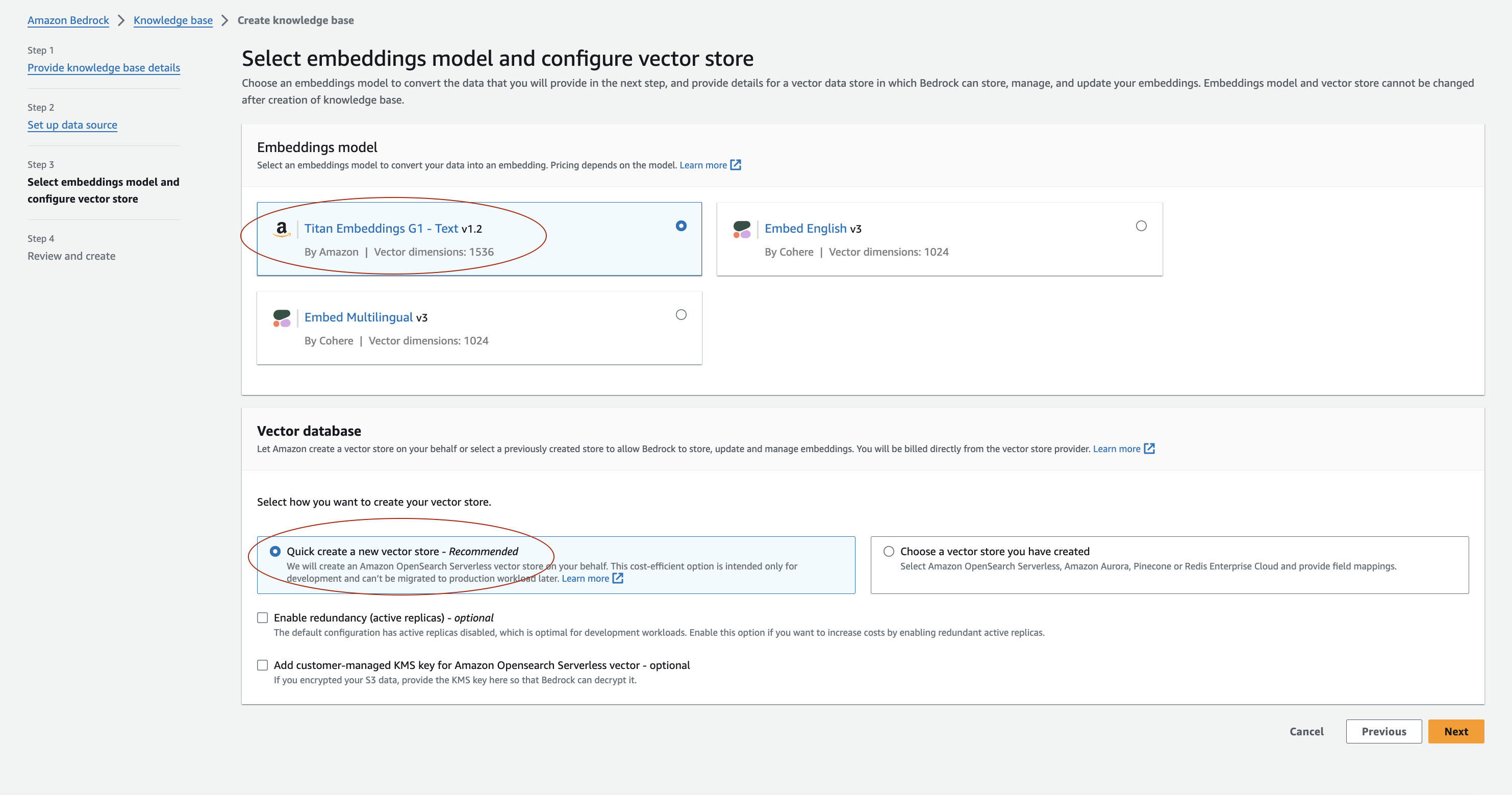
⚠️Consideration: Behind the scenes of Amazon Knowledge Base, AWS generates embeddings from the defined data source and creates a vector store in Amazon's OpenSearch Serverless. OpenSearch charges hourly for ingestion, search and querying, and storage.
⚠️Be mindful of these charges as you set up your own Bedrock services. ⚠️
Read more about OpenSearch Serverless pricing here.
Once the knowledge base has been created, you will need to sync the data before you can start utilizing it with your chosen model.

Ask Claude Questions
Now select the model and we can start asking questions about our data!
⛔ Limitation: Claude does have limitations based on the files uploaded. Files uploaded to Claude must meet the following criteria:
- Maximum 10MB per file
- Maximum 5 files
- Under 200k tokens
Note that these limitations are not enforced by Amazon Knowledge Base, so if you upload more than 5 files to your S3 location and create your knowledge base, it will do so without error. However, when you ask a question in the Bedrock UI (or through CLI), only 5 of the files will be uploaded to Claude for context. Each time you wipe the conversation, a different 5 files can be uploaded for context. Read more about these limitations of Claude here:
Now for the fun part: Enter a question and click run.
Ex. What is the total billed amount for all claims?
You will see an answer appear with the option to show and hide result details. When expanded, you will be able to see the files from the knowledge base that were used to find the given answer.
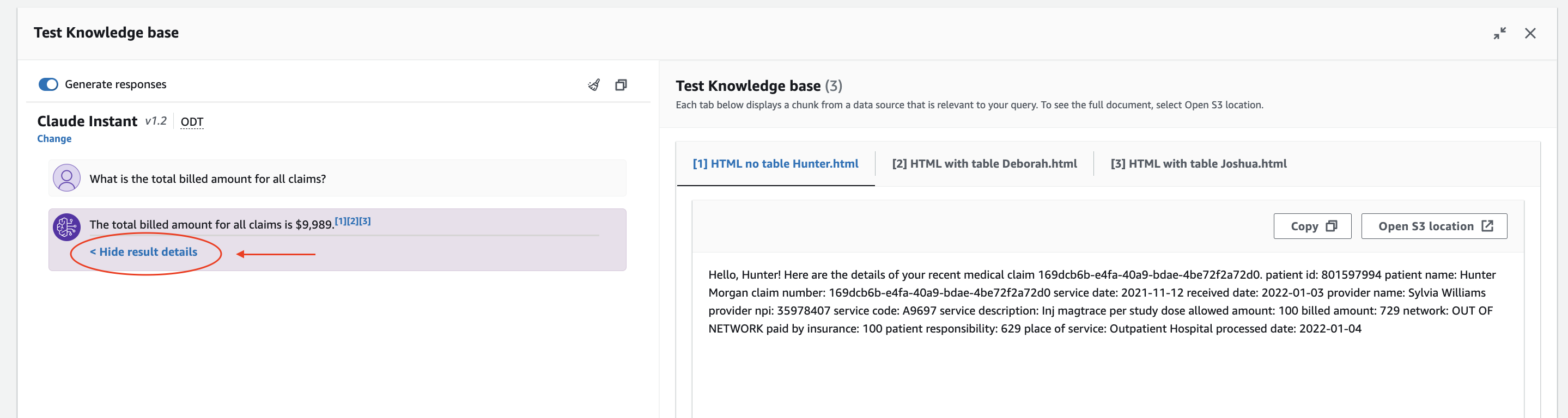
💡 Considerations:
- As you continue to ask questions, the model will use the context of your conversation to answer questions, which can sometimes lead to unexpected results. You always have the option to clear the conversation by clicking the little broom icon.
- The models used to generate answers have additional context outside of just the data you provided, which is great, but when you are looking for or expecting a specific response, you may have to consider how you word your questions.
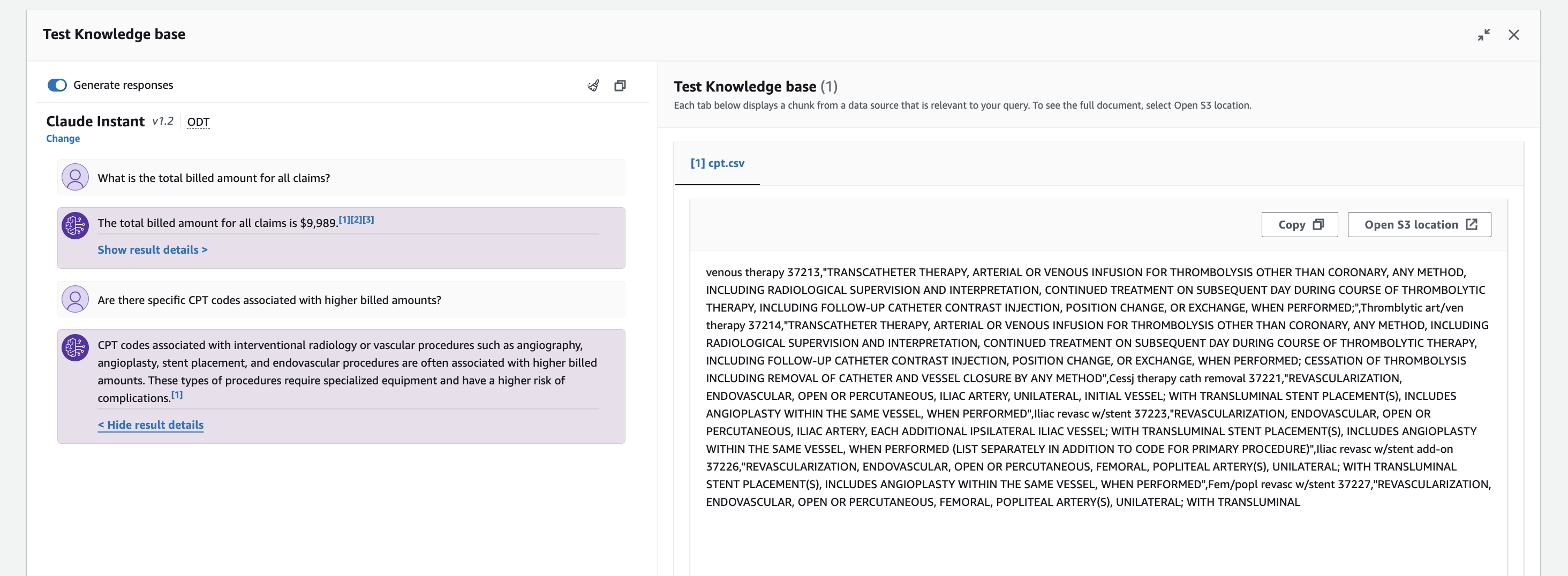
For example, if asked 'Are there specific CPT codes associated with higher billed amounts?', the model produces a response with general information about medical codes and why certain codes may be higher. This is still helpful information within the context of the topic we are asking about, but it does not specifically pertain to the claims data we provided in the knowledge base.
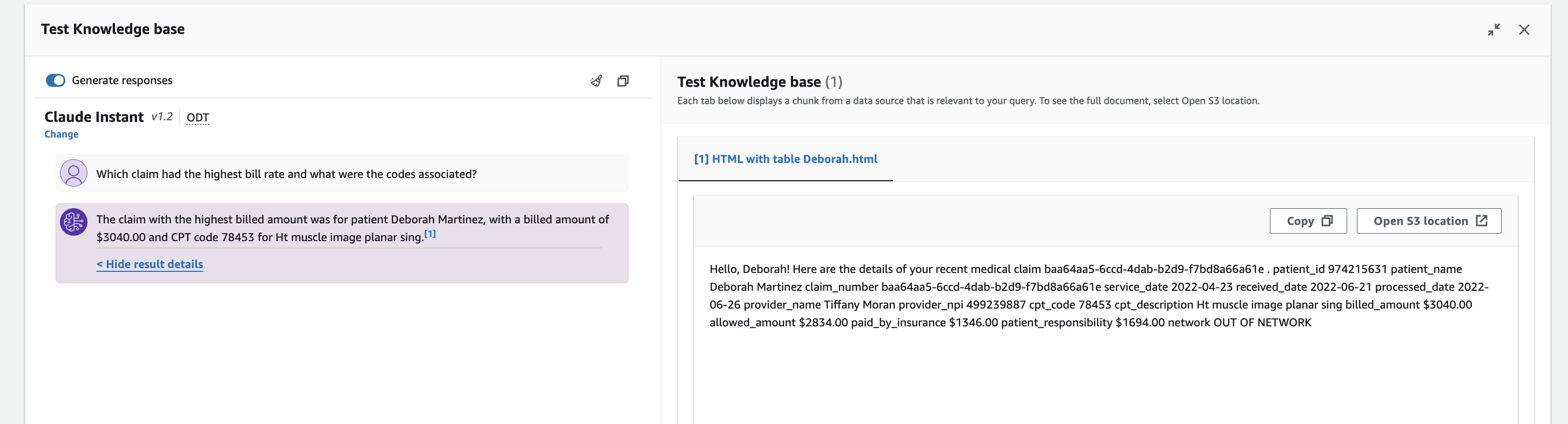
If we reword the question to 'Which claim had the highest bill rate and what were the codes associated?', now the model refers specifically to our knowledge base data and provides information about an individual claim.
And there you have it! By supercharging our LLMs with AWS Bedrock and a Knowledge Base, we've turned these language wizards into specialists for specific tasks.
Thank you for diving into the world of Retrieval-Augmented Generation (RAG) with us. Continue to explore the many use cases for Bedrock and LLMs: summarize documents, generate new content, speed up data analysis, quickly find data anomalies, and so much more! Now, armed with your own data and the Bedrock toolkit, go ahead, ask those burning questions, and let the LLM do its magic.
✨Happy experimenting!✨




Comments