
- Accuracy
- Consistency
- Completeness
- Integrity
- Timeliness
In this article, we will expand on the definition of the ABC Framework as mentioned in this article, written by my colleague Daniel Ferguson. There, he introduces the ABC Framework of Data Quality Management, mainly focusing on how the Audit process lays the groundwork for high-quality data.
In this blog, we will look at the "B" in the ABC framework: Balance. In addition, we will review how the Balance process on an ETL pipeline can confirm your data's accuracy and consistency. We'll also examine how the metadata collected as a part of the Audit process can be used to Balance your data.
How do you Balance your Data?
Balance, to put it simply, is how you can confirm if your ETL processes are operating with the correct data. Consider a situation where you have an ETL process that reads data from a source table's partition (from another system) and writes that partition to a target table within your system. How can you tell that all the data from your source partition made it to your target partition? If you already have an audit process that captures metadata, you can use those metrics to balance your data. Consider the below sample data model for an Audit table created using SQLDBM
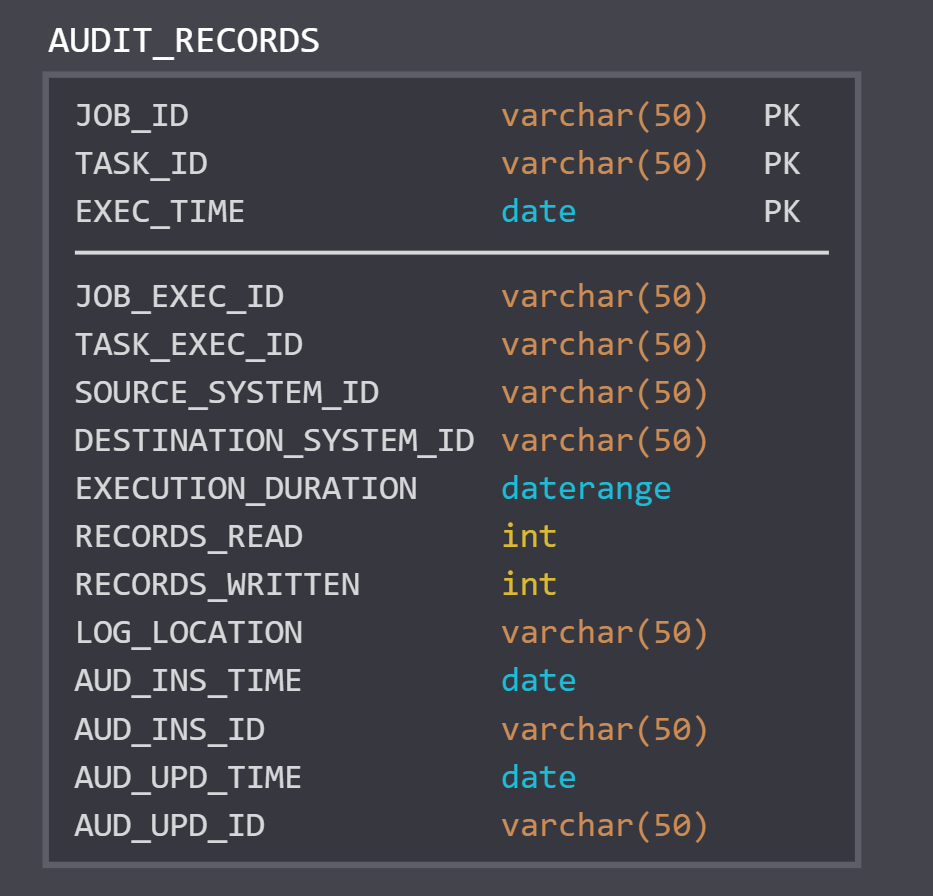
With this model, we know how each job ran, and where each job's records came from and were stored. This audit information will form the basis for our balance process.
The first step to balancing your data in this scenario might be to look at the records_written and records_read fields from the Audit table. If they match, all the records you wanted to insert have done so. However, this approach only works if you are inserting every record from your source table to your target. What do you do if there are multiple tables you pull from your source? What if it is difficult to distinguish between a job and a task? Let's look at a sample balance framework to narow down a potential solution.
Balancing in Practice
To balance your data, you would need to ensure at minimum, the following:
- That your data in your source table is as expected.
- The data in your target table is as expected.
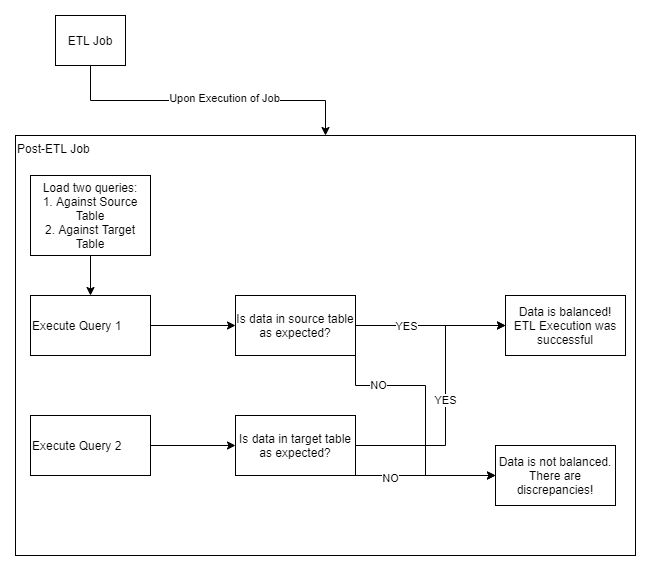
Consider the above balance framework for an ETL job that retrieves data from a source table (from another system) to a target table in your database. At its simplest form, your balance job could take the form of loading two queries (one against the source dataset and one against the target) and executing them against your two tables. Depending on the ETL process, these queries could be derived from the inputs to the ETL process themselves. Ideally, the queries would capture the following two types of information about your source and target tables:
- Count of Records
- Checks against aggregated values, such as amounts
Upon execution of the queries, you would be able to compare the results from the source table to that from the target table. If they match, your data is balanced. If there are discrepancies, these errors need to feed directly into the Control Process. After all, it is in the Control Process that our ABC framework can make corrections to the data to ensure consistency from the start of ETL execution to its completion.
What I describe above would occur only after the successful execution of your ETL job. Normally, if your ETL Job fails due to an exception, the DQM processes would never have begun. A possible solution could be for the Balance job to revert any changes and return both datasets to their prior states.
A Decoupled Approach to ETL and Balance
Events allow you to transmit data from one application to another asynchronously. Your data quality jobs can be triggered by notification or event upon completion of your ETL job (or jobs). One of these would ideally be your balance job. In an event-driven ETL process, balancing your data is a little trickier than a traditional ETL process, as it is more difficult to distinguish between a job and a task. A platform that processes credit card transactions, for example, would be processing each purchase as a separate event. There are usually a series of processes a bank or credit card company uses to verify transactions and eventually post them to your account. How would you balance such a system?
An Aside on Orchestration in Event-Driven ETL
In the Balancing in Practice section above, we looked at a balance architecture that ran serially; upon completion of our ETL Job, we ran the audit process, followed by the balance process, followed by control. In an event-driven ETL pipeline, the entire ETL execution could mean processing thousands, or even millions of events. Thus, we would have to balance and control while we are completing the ETL Job execution.
Balancing the Event-Driven Way
When balancing the event-driven way, we first need to define what an event looks like for the ABC process. Events for your DQM process will mainly be capturing the metadata created by your ETL Job. Some of the metadata that can be included in the event are:
- Primary Keys
- Data Types
- Row Counts
- Fields to audit for quality
- Fields to balance for quality
- Queries to be executed for auditing or balancing your data
With this understanding of what an event looks like, we can now examine what balancing could look like.
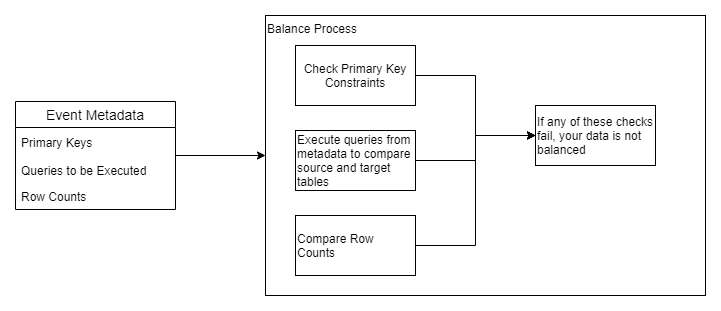
In the diagram above, I've simplified the event, which would be the input to the balance process, into three specific types of metadata: primary keys, queries to be executed, and row counts. For each event, you would want to check that all primary key constraints have been upheld to ensure data integrity. You would also want to check the row counts and execute any queries for balancing data. If all the constraints and row counts match up, much like the case discussed above, your data is balanced. However, if there are any discrepancies, the response would be different as part of the balance job. For each event that encounters inconsistencies as a part of the balance process within the event-driven balance process, the results and even specific rows from the dataset could be sent to the control process. From here, it would again be the realm of the control process, which will be addressed in an upcoming post, to correct the data.
If something in this article piqued your interest or you would like to learn how to leverage and gain insights on your data, Ippon Technologies USA would love to hear from you! Please contact us at contact@ippon.tech with your questions and inquiries.




Comments